
This content originally appeared on Level Up Coding - Medium and was authored by Senthil E

A Technical Deep Dive into the RAG Pipeline
The Challenge of Managing Enterprise Knowledge
Imagine trying to find a specific conversation from three years ago in your email inbox, but multiply that challenge by 10,000. That’s what enterprises face daily. Modern organizations are drowning in data:
- 📄 Documents spread across multiple formats (PDFs, Word docs, presentations)
- 🎥 Recorded meetings and training videos
- 📧 Years of email communications
- 💬 Chat logs and support tickets
- 📊 Spreadsheets and reports
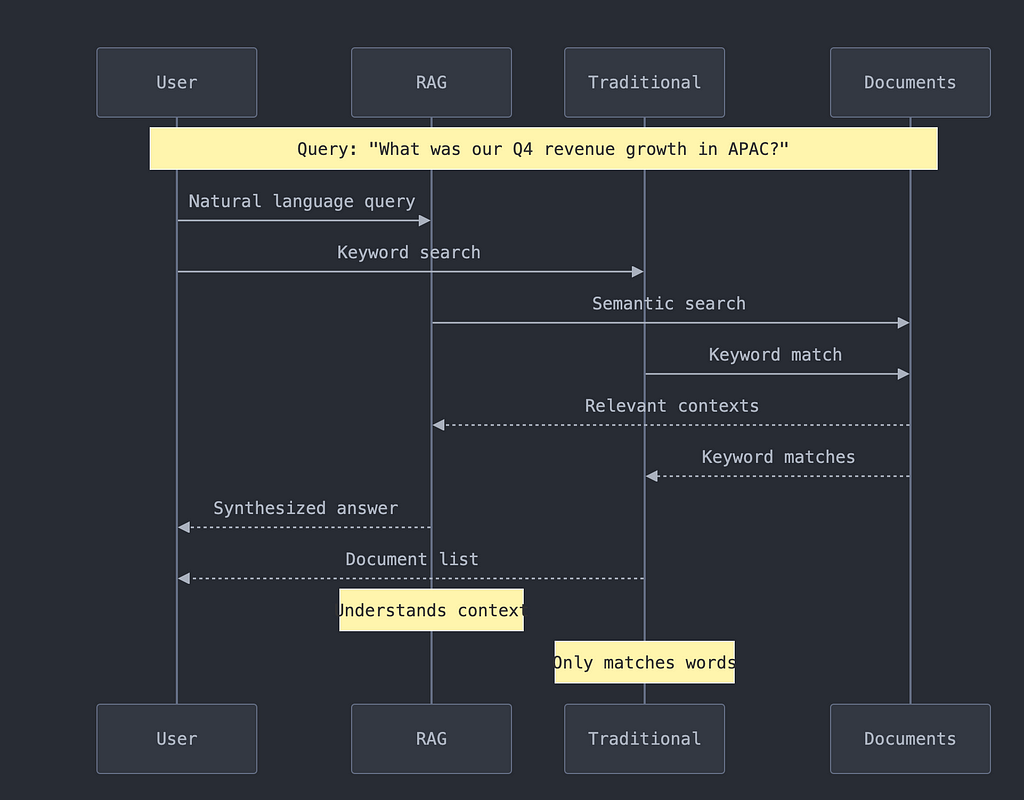
The real challenge isn’t just storing this information — it’s making it accessible and useful. Traditional search solutions fall short because they:
- Rely on exact keyword matches
- Can’t understand context or meaning
- Struggle with multiple file formats
- Don’t learn from user interactions
Why RAG Matters in the Age of AI
Retrieval-Augmented Generation (RAG) is transforming how organizations handle their knowledge base. Think of RAG as your organization’s “smart memory” that:
- Understands Context: Instead of just matching keywords, RAG understands the meaning behind your questions
- Handles Any Format: Whether it’s a PDF, video, or email thread, RAG can process and understand it
- Stays Current: Unlike traditional AI models, RAG always uses your latest data
- Maintains Accuracy: By grounding responses in your actual documents, RAG prevents hallucination
What We’ll Build
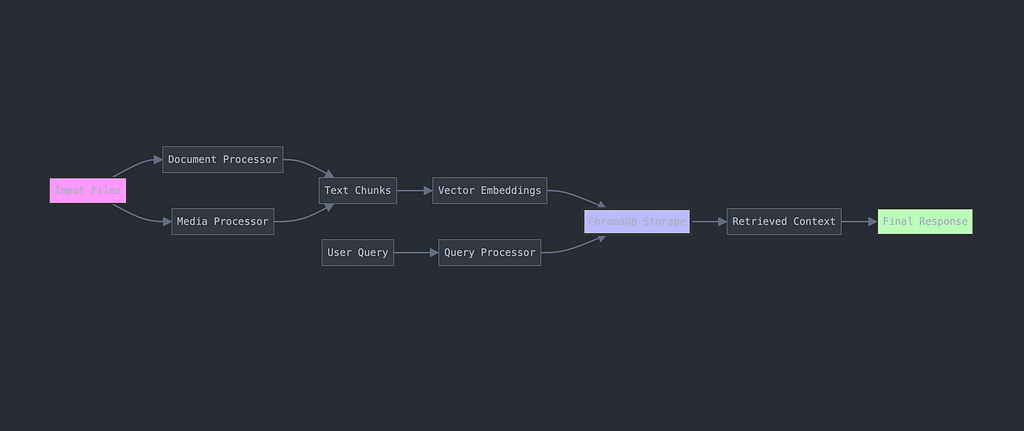
We’re creating a comprehensive RAG pipeline that can:
# Example usage of our RAG pipeline
from rag_pipeline import RAGPipeline, FileConfig
# Initialize with smart defaults
pipeline = RAGPipeline(
persist_directory="./chroma_db",
collection_name="enterprise_docs",
config=FileConfig(
chunk_size=1000,
chunk_overlap=200,
whisper_model_size="base"
)
)
# Process entire directories of mixed content
result = pipeline.process_directory("./company_data")
Our pipeline handles:
- Multiple File Formats:
supported_types = [
# Documents
'.pdf', '.docx', '.pptx', '.xlsx', '.txt',
# Media
'.mp3', '.wav', '.mp4', '.avi',
# Communications
'.eml', '.html', '.md'
]
2. Intelligent Processing:
- Smart chunking for optimal context
- Automatic metadata extraction
- Audio/video transcription
- Vector embedding generation
3. Efficient Storage and Retrieval:
# Example query
results = pipeline.db_manager.query(
collection_name="enterprise_docs",
query_texts=["What were our key achievements in Q4?"],
n_results=3
)
Technical Requirements and Prerequisites
To get started, you’ll need:
1. Python Environment
- Python 3.11+ installed
- Virtual environment recommended
2. Core Dependencies
pip install -r requirements.txt
# Core dependencies
chromadb>=0.4.0
langchain>=0.1.0
pandas>=1.5.0
numpy>=1.24.0
sentence-transformers>=2.2.0
# Document processing
pypdf>=3.0.0
python-docx>=0.8.11
openpyxl>=3.1.0
python-pptx>=0.6.21
beautifulsoup4>=4.12.0
markdown>=3.4.0
lxml>=4.9.0
# Media processing
openai-whisper>=20231117
moviepy>=1.0.3
pydub>=0.25.1
torch>=2.0.0
# Optional but recommended
tqdm>=4.65.0
python-magic>=0.4.27
pyyaml>=6.0.0
All code is thoroughly documented and follows best practices:
def process_file(self, file_path: str) -> List[Document]:
"""
Process a single file and return chunks with metadata.
Args:
file_path (str): Path to the file to process
Returns:
List[Document]: List of processed document chunks
Raises:
ValueError: If file type is not supported
"""
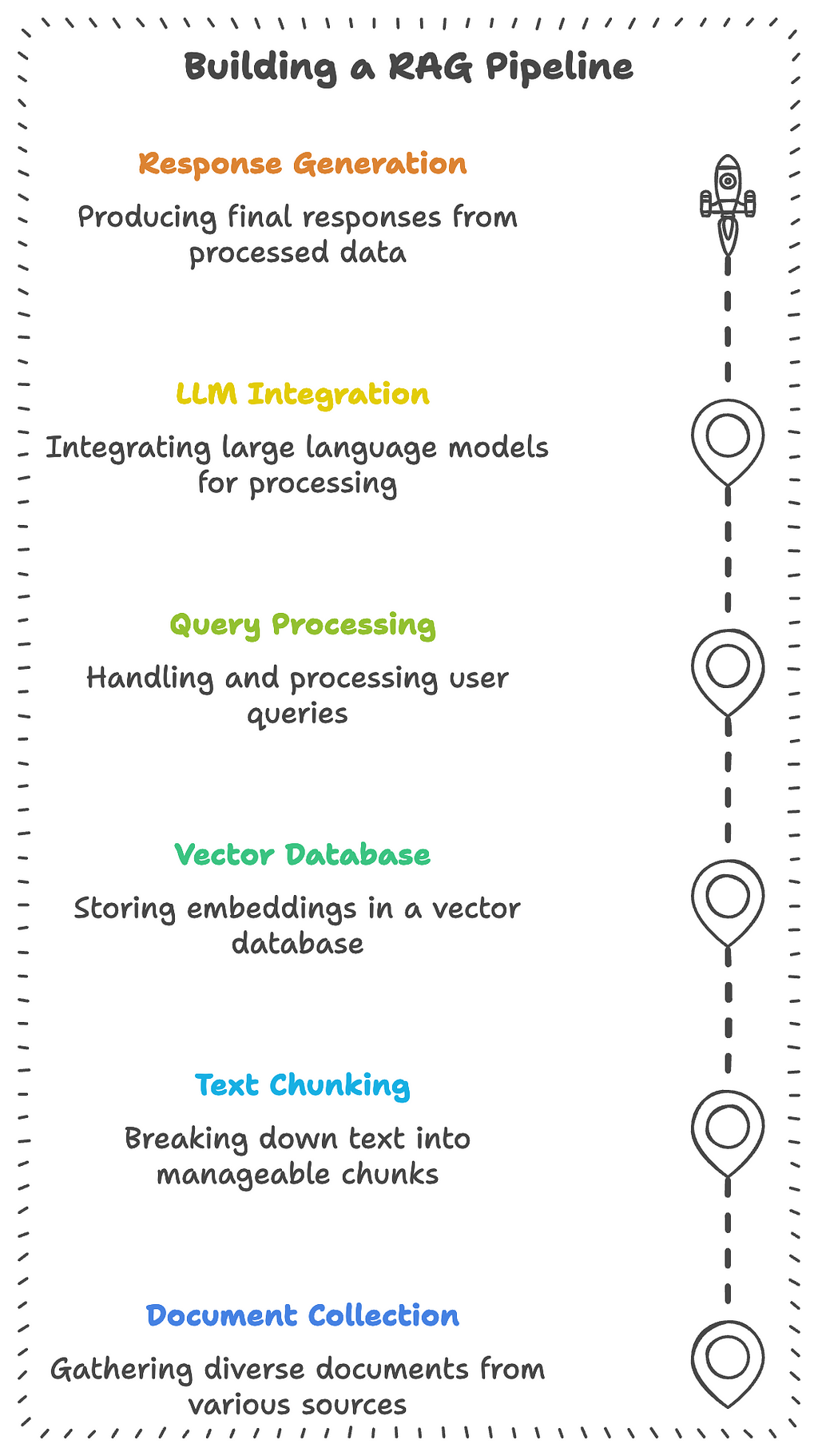
Understanding RAG Architecture: Building Blocks of Modern Document Intelligence
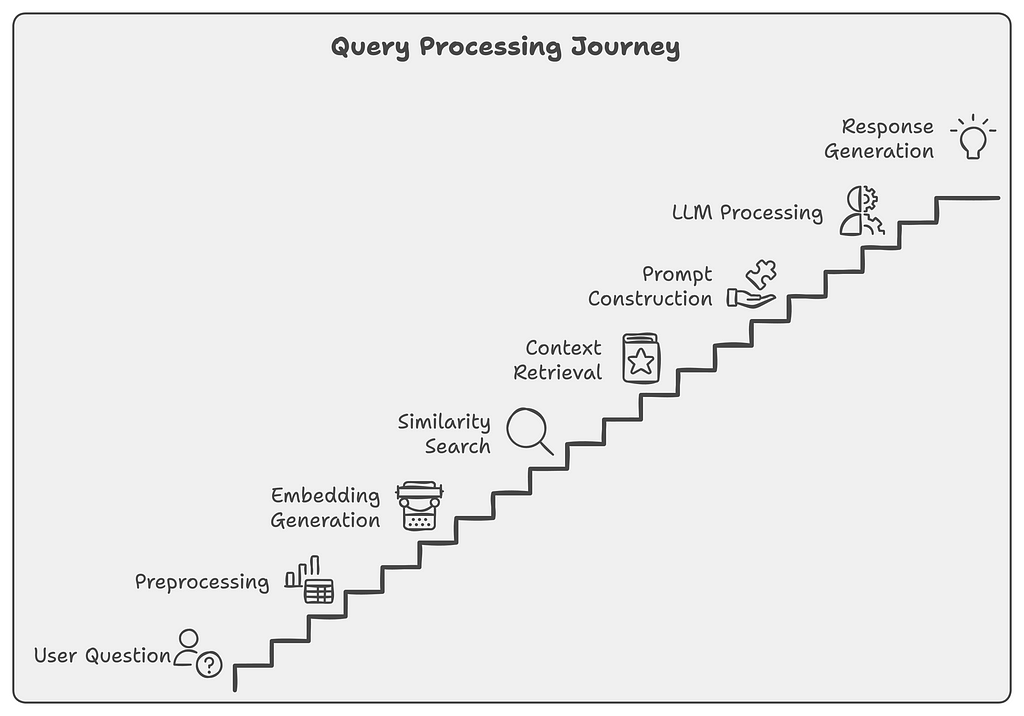
Components of a RAG System
Think of a RAG system like a highly efficient library with a brilliant librarian. Let’s break down how this “smart library” works:
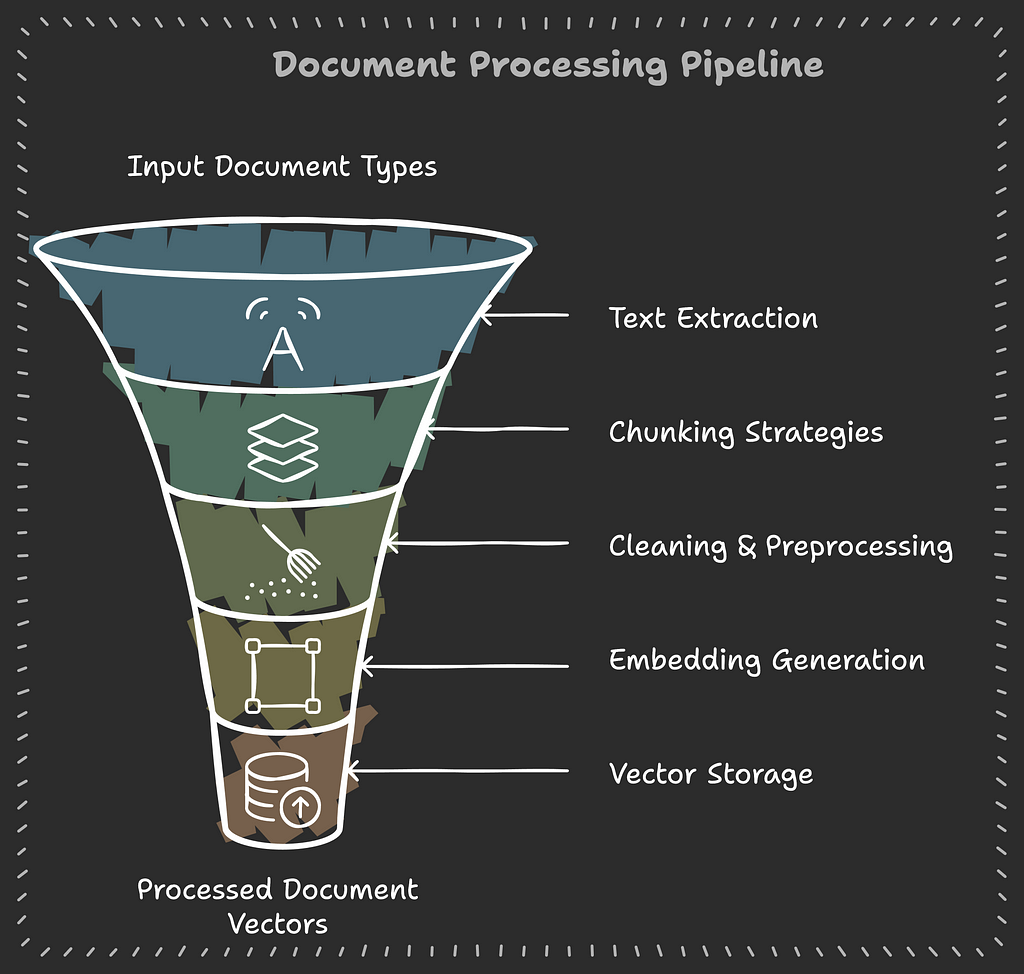
1. Document Processing Pipeline
This is our “book preparation” department. Just as a library needs to process new books before they can be shelved, our pipeline prepares documents for efficient retrieval:
class DocumentProcessor:
def __init__(self, config: FileConfig):
self.config = config
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size,
chunk_overlap=config.chunk_overlap
)
def process_file(self, file_path: str) -> List[LangchainDocument]:
"""Process a single file into searchable chunks"""
# Extract text based on file type
text = self._extract_text(file_path)
# Split into manageable chunks
chunks = self.text_splitter.split_text(text)
# Add metadata for better retrieval
return [
LangchainDocument(
page_content=chunk,
metadata={
"source": file_path,
"chunk_index": i,
"processed_date": datetime.now().isoformat()
}
)
for i, chunk in enumerate(chunks)
]
2. Vector Storage
This is our “smart shelving system.” Instead of organizing by alphabet or category, we arrange documents by meaning:
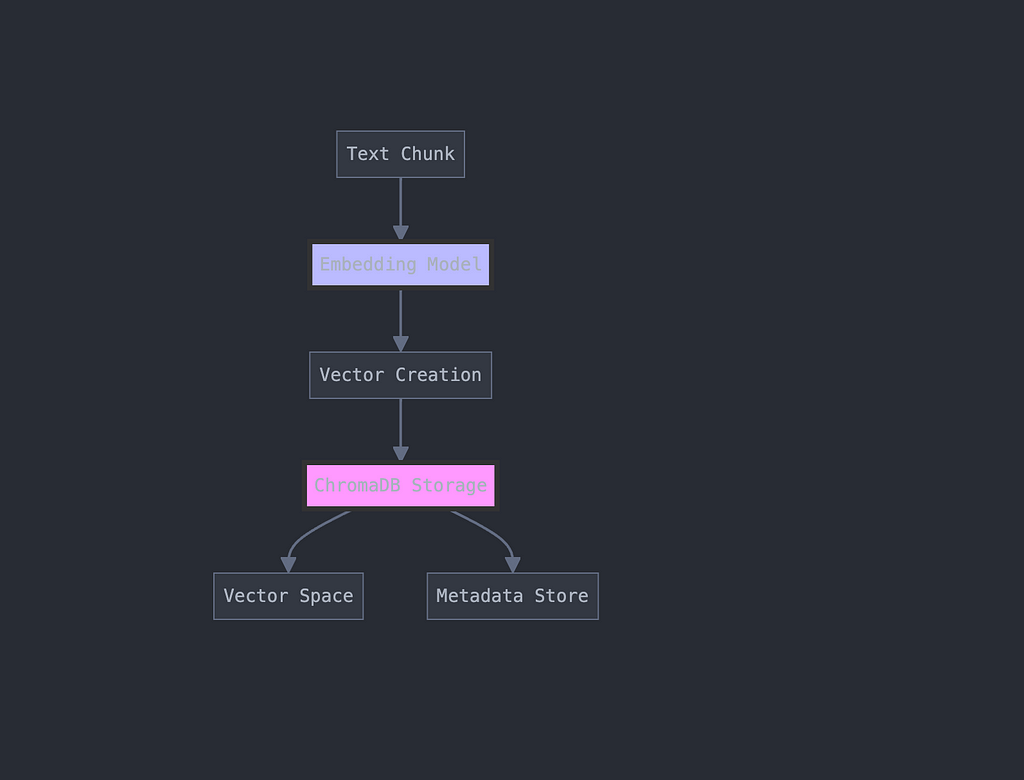
Here’s how we implement this using ChromaDB:
class ChromaDBManager:
def __init__(self, persist_directory: str):
self.client = chromadb.PersistentClient(path=persist_directory)
self.embedding_function = embedding_functions.DefaultEmbeddingFunction()
def add_documents(self, collection_name: str, documents: List[LangchainDocument]):
"""Store documents with their vector embeddings"""
collection = self.get_or_create_collection(collection_name)
# Prepare documents for storage
docs = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
ids = [f"{doc.metadata['file_hash']}_{doc.metadata['chunk_index']}"
for doc in documents]
# Store in ChromaDB
collection.add(
documents=docs,
metadatas=metadatas,
ids=ids
)
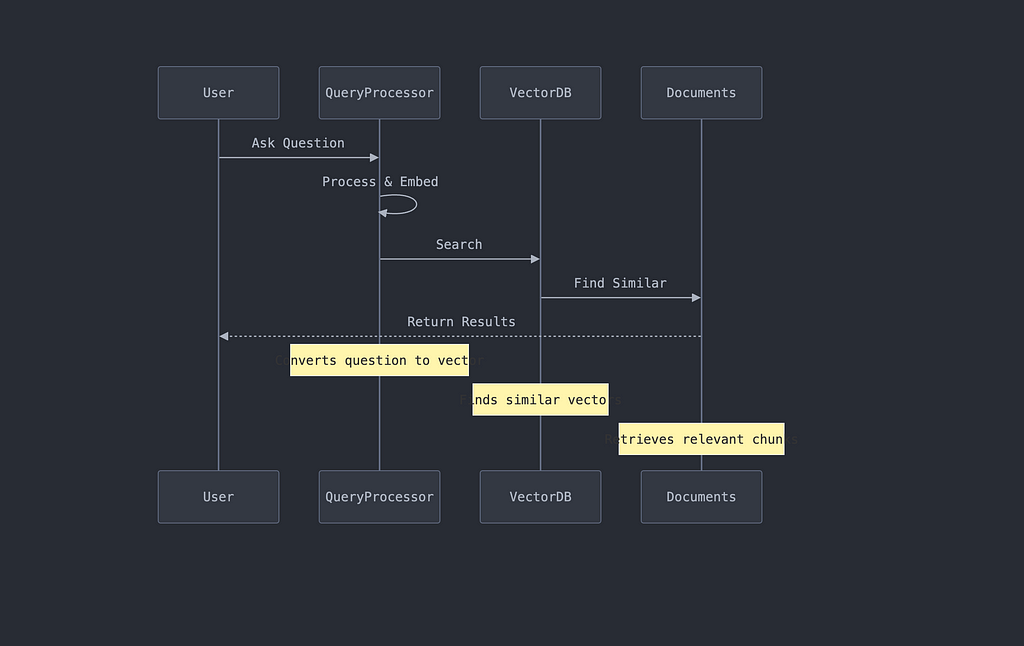
3. Retrieval Mechanism
This is our “librarian’s search process.” When someone asks a question, we:
- Convert the question into the same vector space
- Find similar vectors
- Retrieve relevant document chunks
Implementation example:
def query_database(self, query: str, n_results: int = 3) -> Dict:
"""Execute a semantic search query"""
try:
results = self.collection.query(
query_texts=[query],
n_results=n_results
)
return results
except Exception as e:
self.logger.error(f"Error querying database: {str(e)}")
return None
4. Query Processing
This is where we turn user questions into actionable searches:
Key Benefits Over Traditional Search
- Understanding Context
# Traditional Search
results = database.find({"$text": {"$search": "revenue growth 2023"}})
# RAG Search
results = rag_pipeline.query(
"How did our revenue grow in 2023 compared to previous years?"
)
2. Handling Variations
- Traditional: Needs exact keyword matches
- RAG: Understands synonyms and context
3. Multi-format Support
# Our pipeline handles multiple formats automatically
supported_formats = [
# Documents
'.pdf', '.docx', '.pptx',
# Media
'.mp3', '.mp4',
# Text
'.txt', '.md', '.html'
]
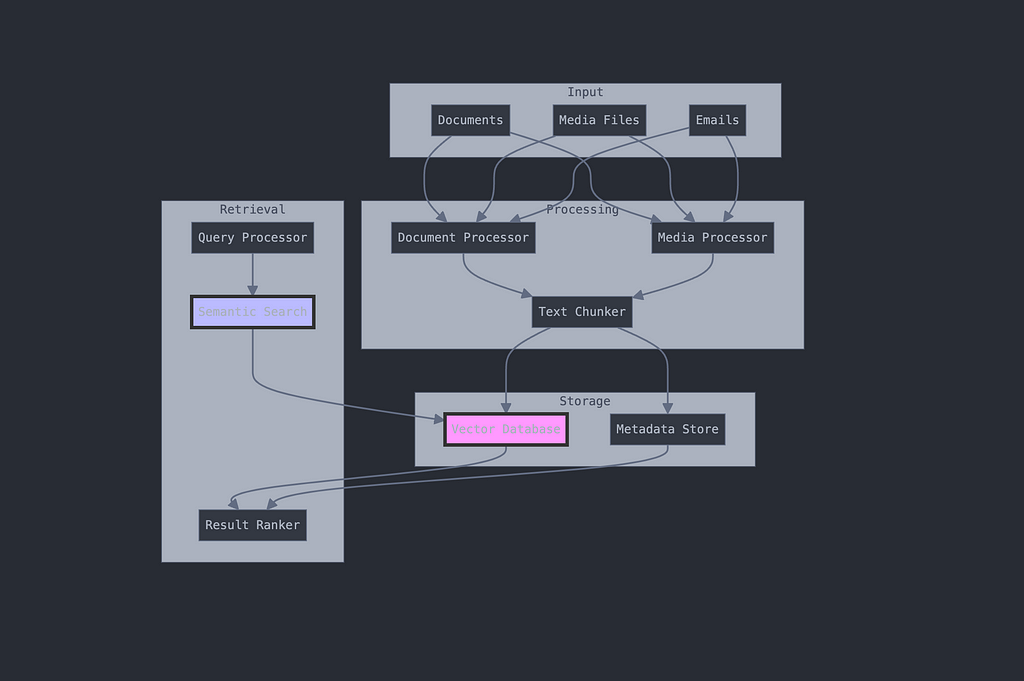
Data Flow Process
- Input Stage
- Documents enter the system
- Format detection
- Initial validation
2. Processing Stage
- Text extraction
- Chunking
- Embedding generation
3. Storage Stage
- Vector storage
- Metadata indexing
- Optimization
4. Retrieval Stage
- Query processing
- Vector similarity search
- Result ranking
Core Features: Building a Versatile Document Intelligence System
Multi-format Document Support
Think of our system as a universal translator for documents. Just as a polyglot can understand multiple languages, our pipeline can process various document formats:
Here’s how we implement this multi-format support:
class DocumentProcessor:
def process_file(self, file_path: str) -> List[LangchainDocument]:
"""Universal document processor"""
file_ext = Path(file_path).suffix.lower()
# Map file extensions to processors
processors = {
'.pdf': self.process_pdf,
'.docx': self.process_docx,
'.pptx': self.process_pptx,
'.xlsx': self.process_xlsx,
'.txt': self.process_text,
'.csv': self.process_csv,
'.eml': self.process_email
}
processor = processors.get(file_ext)
if not processor:
raise ValueError(f"Unsupported format: {file_ext}")
return processor(file_path)
Example of processing specific formats:
def process_pdf(self, file_path: str) -> str:
"""Extract text from PDF"""
text = ""
with open(file_path, 'rb') as file:
pdf = pypdf.PdfReader(file)
for page in pdf.pages:
text += page.extract_text() + "\n"
return text
def process_email(self, file_path: str) -> str:
"""Process email files"""
with open(file_path, 'r') as file:
msg = email.message_from_file(file)
return f"""
Subject: {msg['subject']}
From: {msg['from']}
To: {msg['to']}
Body: {msg.get_payload()}
"""
Media Processing Capabilities
Our system doesn’t just read text — it can “listen” and “watch” too:

Implementation of media processing:
class MediaProcessor:
def __init__(self, config: FileConfig):
self.whisper_model = whisper.load_model(
config.whisper_model_size,
device=config.device
)
def process_media(self, file_path: str) -> str:
"""Process audio and video files"""
file_ext = Path(file_path).suffix.lower()
# Handle video files
if file_ext in ['.mp4', '.avi', '.mov']:
audio_path = self.extract_audio(file_path)
return self.transcribe_audio(audio_path)
# Handle audio files
elif file_ext in ['.mp3', '.wav', '.m4a']:
return self.transcribe_audio(file_path)
Robust Error Handling and Logging
We’ve built in comprehensive error handling and logging to ensure reliability:
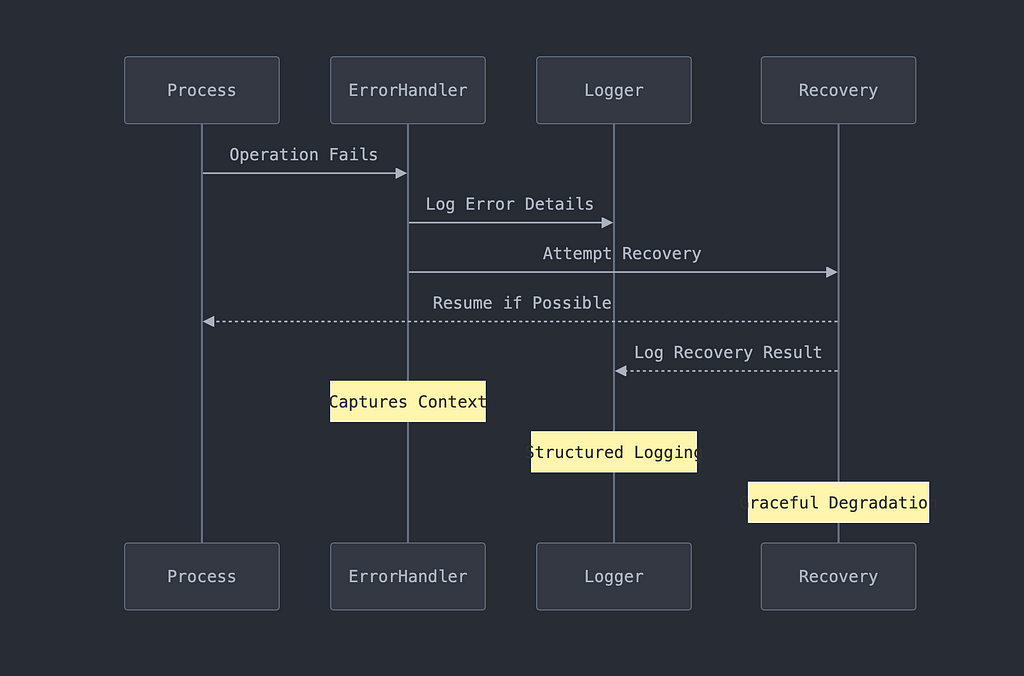
Implementation example:
def setup_logging():
"""Configure structured logging"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('logs/pipeline.log'),
logging.StreamHandler()
]
)
def process_directory(self, directory_path: str) -> Dict:
"""Process directory with error handling"""
processed_files = []
failed_files = []
try:
for file_path in Path(directory_path).rglob('*'):
try:
self.process_file(file_path)
processed_files.append(file_path)
self.logger.info(f"Processed: {file_path}")
except Exception as e:
failed_files.append((file_path, str(e)))
self.logger.error(f"Failed: {file_path} - {str(e)}")
except Exception as e:
self.logger.critical(f"Directory processing failed: {str(e)}")
raise
return {
"processed": processed_files,
"failed": failed_files
}
Batched Processing for Scalability
To handle large document collections efficiently, we implement batched processing:
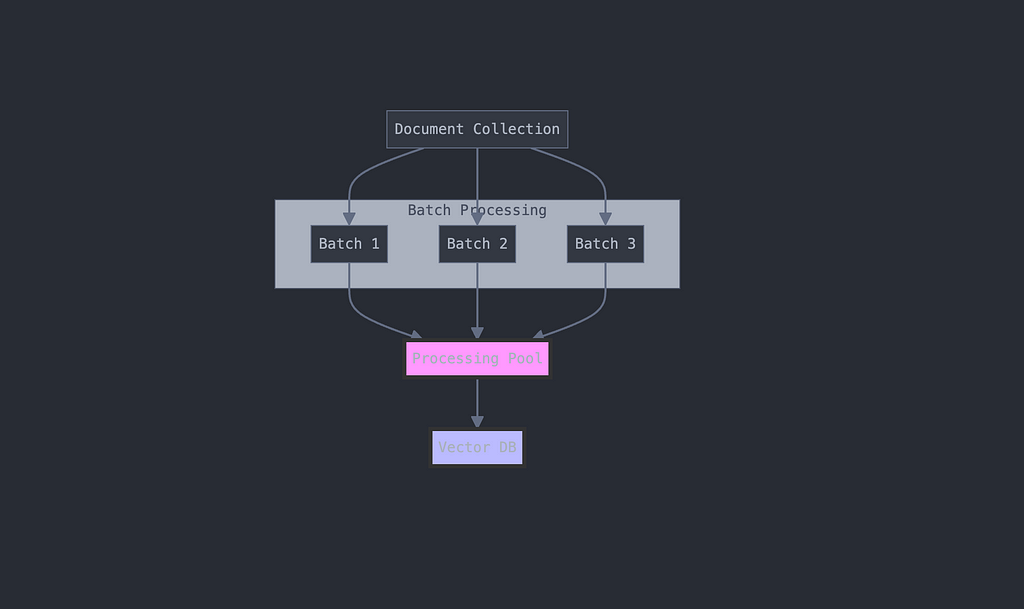
Implementation:
class RAGPipeline:
def process_directory(self, directory_path: str, batch_size: int = 10):
"""Process documents in batches"""
current_batch = []
for file_path in Path(directory_path).rglob('*'):
if len(current_batch) >= batch_size:
# Process current batch
self._process_batch(current_batch)
current_batch = []
current_batch.append(file_path)
# Process remaining documents
if current_batch:
self._process_batch(current_batch)
def _process_batch(self, batch: List[str]):
"""Process a batch of documents"""
documents = []
for file_path in batch:
try:
docs = self.processor.process_file(file_path)
documents.extend(docs)
except Exception as e:
self.logger.error(f"Batch processing error: {str(e)}")
# Store batch in vector database
if documents:
self.db_manager.add_documents(
self.collection_name,
documents
)
Benefits of our batched approach:
- Memory efficiency
- Better error isolation
- Progress tracking
- Scalability
- Resource management
Technical Deep Dive: Inside the RAG Pipeline
Document Processing: Converting Information into Intelligence
Text Extraction Strategies
Think of text extraction like an expert archeologist carefully extracting artifacts — each document type requires specific tools and techniques:
Implementation example:
class DocumentProcessor:
def _extract_text(self, file_path: str) -> str:
"""Extract text from various document formats"""
extractors = {
'.pdf': self._extract_pdf,
'.docx': self._extract_docx,
'.pptx': self._extract_pptx,
'.txt': self._extract_text
}
file_ext = Path(file_path).suffix.lower()
extractor = extractors.get(file_ext)
if not extractor:
raise ValueError(f"No extractor for {file_ext}")
return extractor(file_path)
def _extract_pdf(self, file_path: str) -> str:
"""PDF-specific extraction with layout preservation"""
text = ""
with open(file_path, 'rb') as file:
pdf = pypdf.PdfReader(file)
for page in pdf.pages:
# Extract text while preserving layout
text += page.extract_text(
layout=True,
orientation=True
) + "\n\n"
return text
Chunking and Preprocessing
Breaking down documents into digestible pieces while maintaining context:
def chunk_document(self, text: str) -> List[str]:
"""
Smart document chunking with context preservation
"""
return self.text_splitter.split_text(
text,
chunk_size=self.config.chunk_size,
chunk_overlap=self.config.chunk_overlap,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
Metadata Handling & Hash-based Deduplication
Every chunk gets its own “digital fingerprint”:
def process_with_metadata(self, file_path: str) -> List[Document]:
"""Process document with metadata and deduplication"""
text = self._extract_text(file_path)
chunks = self.chunk_document(text)
# Generate file hash for deduplication
file_hash = self._generate_hash(file_path)
documents = []
seen_chunks = set()
for i, chunk in enumerate(chunks):
# Generate chunk hash
chunk_hash = hashlib.md5(chunk.encode()).hexdigest()
# Skip if duplicate
if chunk_hash in seen_chunks:
continue
seen_chunks.add(chunk_hash)
# Create document with rich metadata
doc = Document(
page_content=chunk,
metadata={
"source": file_path,
"chunk_index": i,
"file_hash": file_hash,
"chunk_hash": chunk_hash,
"created_at": datetime.now().isoformat(),
"file_type": Path(file_path).suffix,
"word_count": len(chunk.split())
}
)
documents.append(doc)
return documents
Vector Storage with ChromaDB
Collection Management and Embedding Generation
Implementation:
class ChromaDBManager:
def __init__(self, persist_directory: str):
self.client = chromadb.PersistentClient(
path=persist_directory,
settings=Settings(
anonymized_telemetry=False,
allow_reset=True
)
)
self.embedding_function = embedding_functions.DefaultEmbeddingFunction()
def create_collection(self, name: str):
"""Create optimized collection"""
return self.client.create_collection(
name=name,
metadata={"hnsw:space": "cosine"},
embedding_function=self.embedding_function
)
Query Optimization
Smart query handling for better results:
def optimized_query(self, query_text: str, n_results: int = 5):
"""Optimized query processing"""
# Preprocess query
cleaned_query = self._clean_query(query_text)
# Get embedding
query_embedding = self.embedding_function([cleaned_query])
# Search with filtering
results = self.collection.query(
query_embeddings=query_embedding,
n_results=n_results * 2, # Get more candidates for reranking
include_metadata=True,
where={"word_count": {"$gt": 20}} # Filter short chunks
)
# Rerank results
reranked_results = self._rerank_results(results)
return reranked_results[:n_results]
Media Processing Pipeline
Whisper Integration for Audio Processing
Our audio processing pipeline in action:
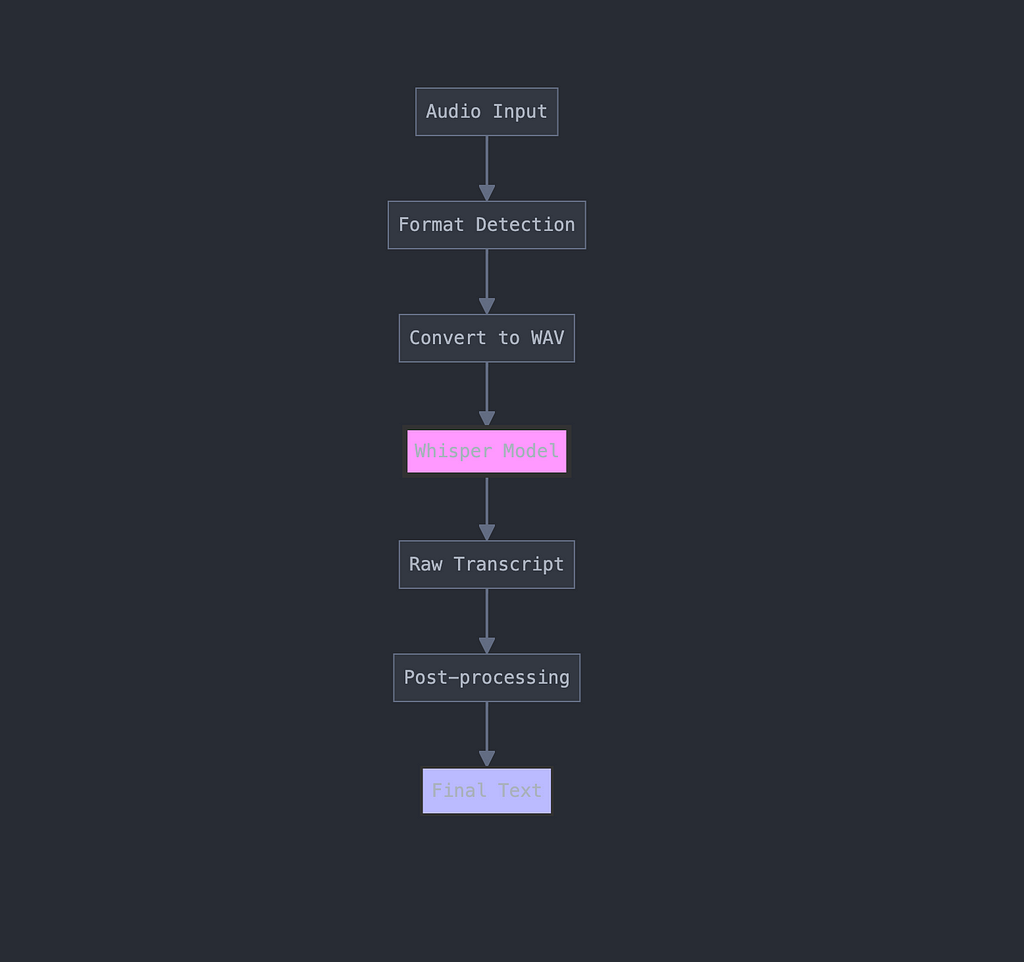
class MediaProcessor:
def __init__(self, config: FileConfig):
self.whisper_model = whisper.load_model(
config.whisper_model_size,
device=config.device
)
def process_audio(self, file_path: str) -> str:
"""Process audio with Whisper"""
audio_path = self._ensure_wav_format(file_path)
# Transcribe with timestamps
result = self.whisper_model.transcribe(
audio_path,
verbose=False,
language='auto',
task='transcribe'
)
# Format with timestamps
transcript = self._format_transcript(result)
return transcript
Video Processing and Frame Extraction
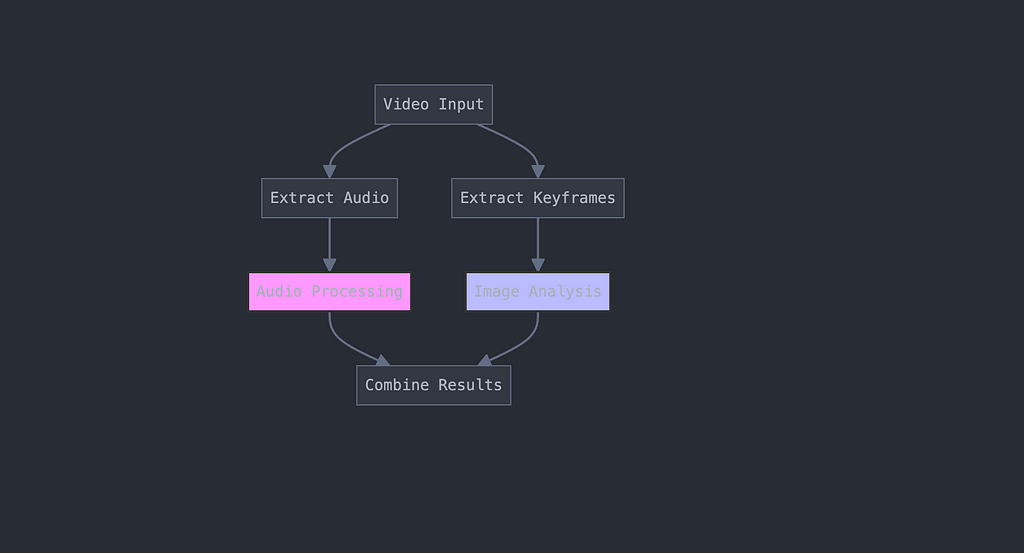
def process_video(self, video_path: str) -> Dict[str, Any]:
"""Process video content"""
try:
# Extract audio
with tempfile.NamedTemporaryFile(suffix='.wav') as temp_audio:
video = mp.VideoFileClip(video_path)
video.audio.write_audiofile(
temp_audio.name,
logger=None
)
# Process audio
transcript = self.process_audio(temp_audio.name)
# Extract metadata
metadata = {
"duration": video.duration,
"fps": video.fps,
"size": video.size,
"audio_channels": video.audio.nchannels
if video.audio else None
}
return {
"transcript": transcript,
"metadata": metadata
}
except Exception as e:
self.logger.error(f"Video processing failed: {str(e)}")
raise
Performance Considerations
Key optimization strategies:
- Batch Processing:
def process_batch(self, files: List[str], batch_size: int = 5):
"""Process files in optimized batches"""
for i in range(0, len(files), batch_size):
batch = files[i:i + batch_size]
with ThreadPoolExecutor() as executor:
futures = [executor.submit(self.process_file, f)
for f in batch]
results = [f.result() for f in futures]
yield results
2. Resource Management:
- GPU utilization for Whisper
- Memory-efficient processing
- Disk I/O optimization
3. Caching Strategy:
@lru_cache(maxsize=1000)
def get_embedding(self, text: str) -> List[float]:
"""Cached embedding generation"""
return self.embedding_function([text])[0]
Implementation Best Practices: Building a Robust RAG System
Configurability and Extensibility
Think of your RAG system like a high-end car — users should be able to customize features while maintaining core functionality.
Configuration Management
Implementation:
from dataclasses import dataclass
from typing import List, Optional
@dataclass
class FileConfig:
"""Configuration for file processing"""
chunk_size: int = 1000
chunk_overlap: int = 200
supported_types: List[str] = None
whisper_model_size: str = "base"
batch_size: int = 10
max_retries: int = 3
class ConfigManager:
def __init__(self, config_path: str = "config.yaml"):
self.config = self._load_config(config_path)
def _load_config(self, path: str) -> dict:
"""Load and validate configuration"""
with open(path, 'r') as f:
config = yaml.safe_load(f)
# Override with environment variables
config = self._override_from_env(config)
return config
def get_file_config(self) -> FileConfig:
"""Get file processing configuration"""
return FileConfig(**self.config['file_processing'])
Example configuration file:
# config.yaml
pipeline:
persist_directory: "./chroma_db"
collection_name: "enterprise_docs"
file_processing:
chunk_size: 1000
chunk_overlap: 200
whisper_model_size: "base"
batch_size: 10
max_retries: 3
storage:
vector_db:
implementation: "chroma"
settings:
anonymized_telemetry: false
allow_reset: true
Error Handling and Recovery
Robust error handling is like having a safety net for your data processing:
class RobustProcessor:
def process_with_retry(self, func, *args, max_retries=3):
"""Process with automatic retry on failure"""
for attempt in range(max_retries):
try:
return func(*args)
except Exception as e:
if attempt == max_retries - 1:
self.logger.error(f"Final attempt failed: {str(e)}")
raise
self.logger.warning(f"Attempt {attempt + 1} failed, retrying...")
time.sleep(2 ** attempt) # Exponential backoff
Logging and Monitoring
Comprehensive logging system:
import logging
from datetime import datetime
import json
class StructuredLogger:
def __init__(self, app_name: str):
self.logger = logging.getLogger(app_name)
self.setup_logging()
def setup_logging(self):
"""Setup structured logging"""
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
# File handler
file_handler = logging.FileHandler('pipeline.log')
file_handler.setFormatter(formatter)
# Console handler
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
self.logger.addHandler(file_handler)
self.logger.addHandler(console_handler)
def log_event(self, event_type: str, details: dict):
"""Log structured event"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"event_type": event_type,
"details": details
}
self.logger.info(json.dumps(log_entry))
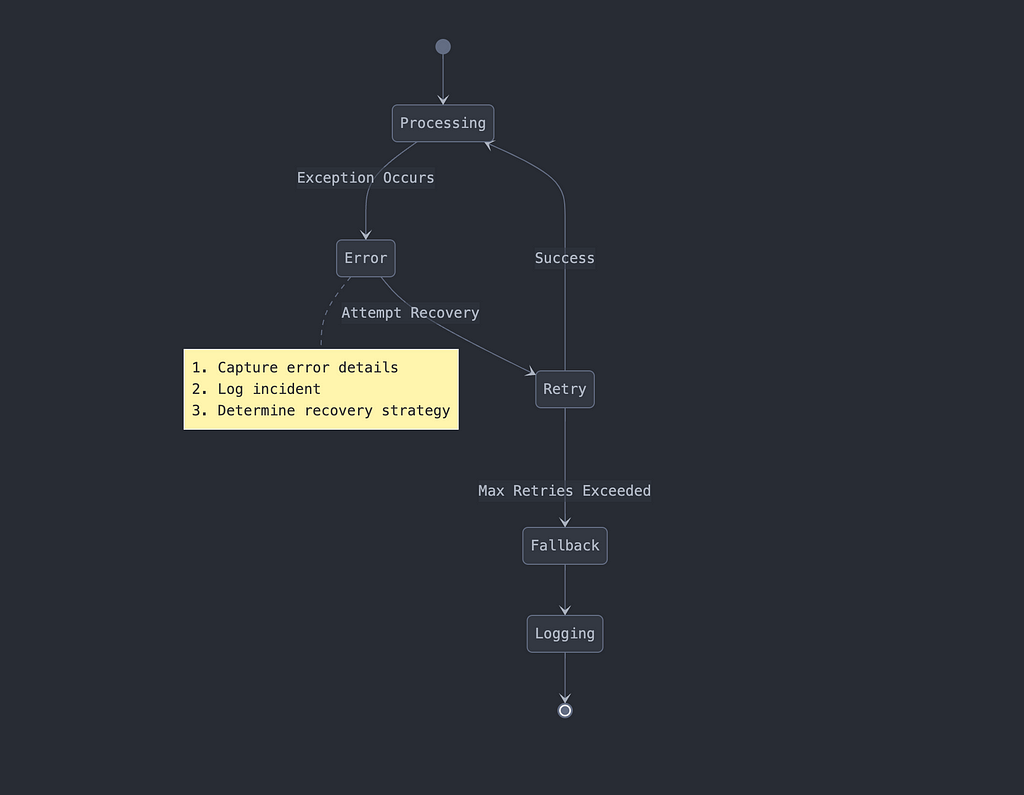
Testing Strategies
Implementation example:
import pytest
from unittest.mock import Mock, patch
class TestRAGPipeline:
@pytest.fixture
def pipeline(self):
"""Setup test pipeline"""
config = FileConfig(
chunk_size=500,
chunk_overlap=50
)
return RAGPipeline(
persist_directory="./test_db",
collection_name="test_collection",
config=config
)
def test_document_processing(self, pipeline):
"""Test document processing"""
# Test with various document types
result = pipeline.process_file("test_doc.pdf")
assert result is not None
assert len(result) > 0
@patch('chromadb.PersistentClient')
def test_vector_storage(self, mock_client):
"""Test vector storage operations"""
mock_collection = Mock()
mock_client.return_value.get_collection.return_value = mock_collection
# Test storage operations
pipeline = self.pipeline()
pipeline.store_vectors([{"text": "test", "embedding": [0.1, 0.2]}])
mock_collection.add.assert_called_once()
Advanced Features: Taking Your RAG System to the Next Level
Batch Processing for Large Datasets
Think of batch processing like an efficient assembly line — instead of processing documents one at a time, we handle them in optimized groups:
Implementation:
class BatchProcessor:
def __init__(self, batch_size: int = 100):
self.batch_size = batch_size
self.current_batch = []
self.processed_count = 0
async def process_large_dataset(self, file_paths: List[str]):
"""Process large datasets efficiently"""
async with AsyncProcessPool() as pool:
# Create batches
batches = [
file_paths[i:i + self.batch_size]
for i in range(0, len(file_paths), self.batch_size)
]
# Process batches concurrently
tasks = [
pool.schedule(self._process_batch, batch)
for batch in batches
]
# Gather results
results = await asyncio.gather(*tasks)
return self._combine_results(results)
async def _process_batch(self, batch: List[str]):
"""Process a single batch of documents"""
try:
processed_docs = []
for file_path in batch:
doc = await self.processor.process_file(file_path)
processed_docs.append(doc)
# Store batch in vector database
await self.db_manager.store_batch(processed_docs)
return {
"success": True,
"count": len(processed_docs)
}
except Exception as e:
return {
"success": False,
"error": str(e)
}
Incremental Updates
Managing document updates efficiently:
Implementation:
class IncrementalUpdater:
def __init__(self, db_manager: ChromaDBManager):
self.db_manager = db_manager
self.file_tracker = FileTracker()
async def process_updates(self, directory: str):
"""Process document updates incrementally"""
# Detect changes
changes = self.file_tracker.detect_changes(directory)
# Process modifications
for file_path in changes['modified']:
await self._update_document(file_path)
# Process deletions
for file_path in changes['deleted']:
await self._remove_document(file_path)
# Process new files
for file_path in changes['added']:
await self._add_document(file_path)
async def _update_document(self, file_path: str):
"""Update changed document"""
# Get old vectors
old_vectors = await self.db_manager.get_vectors_for_file(file_path)
# Process new version
new_vectors = await self.processor.process_file(file_path)
# Update only changed chunks
await self._update_changed_chunks(old_vectors, new_vectors)
Multi-modal Content Handling
Processing different types of content seamlessly:
Implementation:
class MultiModalProcessor:
def __init__(self):
self.text_processor = TextProcessor()
self.image_processor = ImageProcessor()
self.audio_processor = AudioProcessor()
self.video_processor = VideoProcessor()
async def process_content(self, file_path: str):
"""Process multi-modal content"""
content_type = self._detect_content_type(file_path)
processors = {
'text': self.text_processor.process,
'image': self.image_processor.process,
'audio': self.audio_processor.process,
'video': self.video_processor.process
}
processor = processors.get(content_type)
if not processor:
raise ValueError(f"Unsupported content type: {content_type}")
# Process content and generate embeddings
embeddings = await processor(file_path)
return embeddings
Query Result Ranking and Filtering
Smart ranking system for better results:
Implementation:
class QueryEngine:
def __init__(self):
self.ranker = ResultRanker()
self.filter_engine = FilterEngine()
async def execute_query(self, query: str, filters: dict = None):
"""Execute query with smart ranking"""
# Get initial results
raw_results = await self.db_manager.query(
query_text=query,
n_results=50 # Get more candidates for reranking
)
# Apply filters
if filters:
filtered_results = self.filter_engine.apply_filters(
raw_results,
filters
)
else:
filtered_results = raw_results
# Rank results
ranked_results = self.ranker.rank_results(
query=query,
results=filtered_results
)
return ranked_results[:10] # Return top 10
Custom Embedding Functions
Create specialized embeddings for your use case:
Implementation:
class CustomEmbeddingFunction:
def __init__(self, model_name: str = "domain-specific-model"):
self.base_model = self._load_model(model_name)
self.domain_processor = DomainProcessor()
def generate_embedding(self, text: str) -> List[float]:
"""Generate domain-optimized embeddings"""
# Preprocess with domain knowledge
processed_text = self.domain_processor.process(text)
# Generate base embedding
base_embedding = self.base_model.encode(processed_text)
# Enhance with domain-specific features
enhanced_embedding = self._enhance_embedding(
base_embedding,
processed_text
)
return enhanced_embedding
def _enhance_embedding(self, base_embedding: List[float],
text: str) -> List[float]:
"""Add domain-specific enhancements"""
# Extract domain features
domain_features = self.domain_processor.extract_features(text)
# Combine with base embedding
enhanced = np.concatenate([
base_embedding,
domain_features
])
# Normalize
return enhanced / np.linalg.norm(enhanced)
Example usage:
# Initialize with custom embedding
pipeline = RAGPipeline(
custom_embedding=CustomEmbeddingFunction(),
collection_name="domain_specific_docs"
)
# Process documents with custom embeddings
results = await pipeline.process_directory(
"domain_documents/",
use_custom_embedding=True
)
Testing and Quality Assurance: Ensuring RAG Pipeline Reliability
Unit Testing Strategy
Think of unit tests like checking individual LEGO pieces before building a complex structure:
Example implementation:
import pytest
from unittest.mock import Mock, patch
class TestDocumentProcessor:
@pytest.fixture
def processor(self):
"""Setup test processor"""
config = FileConfig(
chunk_size=500,
chunk_overlap=50
)
return DocumentProcessor(config)
def test_pdf_extraction(self, processor):
"""Test PDF text extraction"""
# Arrange
test_pdf = "tests/data/sample.pdf"
expected_text = "Sample PDF content"
# Act
result = processor.process_pdf(test_pdf)
# Assert
assert expected_text in result
assert len(result) > 0
@pytest.mark.parametrize("file_type,content", [
("pdf", "PDF content"),
("docx", "Word content"),
("txt", "Text content")
])
def test_multiple_formats(self, processor, file_type, content):
"""Test multiple file formats"""
test_file = f"tests/data/sample.{file_type}"
result = processor.process_file(test_file)
assert content in result
Integration Testing
Integration tests ensure components work together seamlessly:
Implementation:
class TestRAGPipelineIntegration:
@pytest.fixture(scope="module")
def pipeline(self):
"""Setup test pipeline"""
return RAGPipeline(
persist_directory="./test_db",
collection_name="test_collection"
)
async def test_end_to_end_flow(self, pipeline):
"""Test complete pipeline flow"""
# 1. Process test documents
test_docs = ["test.pdf", "test.docx", "test.mp3"]
results = await pipeline.process_files(test_docs)
assert results["processed"] == len(test_docs)
# 2. Verify storage
collection = pipeline.db_manager.get_collection()
assert collection.count() == results["processed"]
# 3. Test retrieval
query = "test query"
search_results = await pipeline.query(query)
assert len(search_results) > 0
assert all(isinstance(r["score"], float) for r in search_results)
Performance Testing
Measuring system performance under various conditions:
Performance test implementation:
class PerformanceTester:
def __init__(self, pipeline: RAGPipeline):
self.pipeline = pipeline
self.metrics = []
async def run_load_test(self,
document_count: int,
concurrent_users: int,
duration_seconds: int):
"""Run load test"""
start_time = time.time()
# Create test documents
test_docs = self._generate_test_docs(document_count)
# Simulate concurrent users
async with AsyncPool(concurrent_users) as pool:
tasks = []
while time.time() - start_time < duration_seconds:
tasks.append(pool.spawn(self._simulate_user_activity))
results = await asyncio.gather(*tasks)
# Analyze results
self._analyze_performance(results)
def _analyze_performance(self, results: List[Dict]):
"""Calculate performance metrics"""
metrics = {
"avg_latency": np.mean([r["latency"] for r in results]),
"p95_latency": np.percentile([r["latency"] for r in results], 95),
"throughput": len(results) / self.duration_seconds,
"error_rate": sum(1 for r in results if r["error"]) / len(results)
}
self.metrics.append(metrics)
Error Scenario Handling
Testing how the system handles various error conditions:
Implementation:
class ErrorScenarioTester:
def __init__(self, pipeline: RAGPipeline):
self.pipeline = pipeline
async def test_error_scenarios(self):
"""Test various error scenarios"""
scenarios = [
self._test_invalid_document,
self._test_network_failure,
self._test_resource_exhaustion,
self._test_timeout,
self._test_data_corruption
]
results = []
for scenario in scenarios:
try:
await scenario()
results.append({"scenario": scenario.__name__, "passed": True})
except Exception as e:
results.append({
"scenario": scenario.__name__,
"passed": False,
"error": str(e)
})
return results
async def _test_invalid_document(self):
"""Test handling of invalid documents"""
with pytest.raises(ValueError):
await self.pipeline.process_file("invalid.xyz")
Query Testing Framework
Comprehensive testing of the query system:
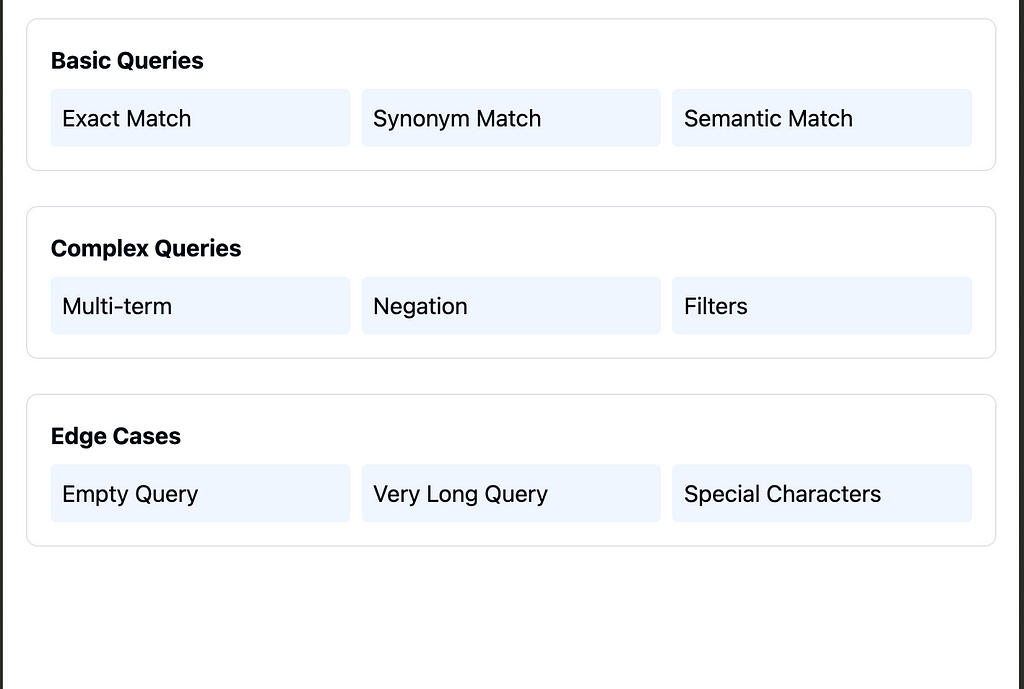
Implementation:
class QueryTester:
def __init__(self, pipeline: RAGPipeline):
self.pipeline = pipeline
self.test_cases = self._load_test_cases()
async def run_query_tests(self):
"""Run comprehensive query tests"""
results = []
for test_case in self.test_cases:
# Setup test data
await self._setup_test_data(test_case)
# Run query
actual_results = await self.pipeline.query(
test_case["query"],
**test_case.get("params", {})
)
# Verify results
score = self._evaluate_results(
actual_results,
test_case["expected"]
)
results.append({
"test_case": test_case["name"],
"score": score,
"details": self._generate_test_report(
actual_results,
test_case
)
})
return results
def _evaluate_results(self, actual, expected):
"""Evaluate query results"""
metrics = {
"precision": self._calculate_precision(actual, expected),
"recall": self._calculate_recall(actual, expected),
"mrr": self._calculate_mrr(actual, expected)
}
return metrics
Example repository structure:
rag-implementation/
├── src/
│ ├── core/
│ │ ├── pipeline.py
│ │ ├── processor.py
│ │ └── config.py
│ ├── processors/
│ │ ├── document.py
│ │ ├── media.py
│ │ └── embedding.py
│ ├── storage/
│ │ ├── vector_store.py
│ │ └── cache.py
│ └── api/
│ ├── routes.py
│ └── schema.py
├── docs/
│ ├── api/
│ ├── guides/
│ └── tutorials/
├── examples/
│ ├── basic/
│ ├── advanced/
│ └── integrations/
├── tests/
│ ├── unit/
│ ├── integration/
│ └── performance/
└── requirements.txt
The full code:

rag_pipeline.py
import os
import logging
from typing import List, Dict, Any, Optional
from pathlib import Path
from datetime import datetime
from dataclasses import dataclass
import hashlib
import tempfile
# File processing
import pypdf
from docx import Document
import pandas as pd
from pptx import Presentation
import email
import csv
import json
import xml.etree.ElementTree as ET
from bs4 import BeautifulSoup
import markdown
# Media processing
import whisper
import moviepy.editor as mp
from pydub import AudioSegment
import torch
# Vector operations
import chromadb
from chromadb.config import Settings
from chromadb.utils import embedding_functions
import numpy as np
# Text processing
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LangchainDocument
class ChromaDBManager:
"""Manages interactions with ChromaDB"""
def __init__(self, persist_directory: str):
self.client = chromadb.PersistentClient(path=persist_directory)
self.logger = logging.getLogger(__name__)
# Default to OpenAI's text embedding function
self.embedding_function = embedding_functions.DefaultEmbeddingFunction()
# Initialize collection during setup
self.initialize_collection("enterprise_docs")
def initialize_collection(self, collection_name: str):
"""Initialize collection during setup"""
try:
collection = self.client.get_collection(
name=collection_name,
embedding_function=self.embedding_function
)
self.logger.info(f"Using existing collection: {collection_name}")
except Exception:
collection = self.client.create_collection(
name=collection_name,
embedding_function=self.embedding_function
)
self.logger.info(f"Created new collection: {collection_name}")
return collection
def get_or_create_collection(self, collection_name: str):
"""Get existing collection or create new one"""
try:
return self.client.get_collection(
name=collection_name,
embedding_function=self.embedding_function
)
except Exception:
return self.client.create_collection(
name=collection_name,
embedding_function=self.embedding_function
)
def add_documents(self, collection_name: str, documents: List[LangchainDocument]):
"""Add documents to the collection"""
try:
collection = self.get_or_create_collection(collection_name)
if not documents: # Skip if no documents
return
# Prepare the documents for ChromaDB format
docs = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
ids = [f"{doc.metadata['file_hash']}_{doc.metadata['chunk_index']}"
for doc in documents]
# Add documents to collection
collection.add(
documents=docs,
metadatas=metadatas,
ids=ids
)
self.logger.info(f"Added {len(documents)} documents to collection {collection_name}")
except Exception as e:
self.logger.error(f"Error adding documents to ChromaDB: {str(e)}")
raise
def query(self, collection_name: str, query_texts: List[str], n_results: int = 5):
"""Query the collection"""
try:
collection = self.get_or_create_collection(collection_name)
results = collection.query(
query_texts=query_texts,
n_results=n_results
)
return results
except Exception as e:
self.logger.error(f"Error querying ChromaDB: {str(e)}")
raise
@dataclass
class FileConfig:
"""Configuration for file processing"""
chunk_size: int = 1000
chunk_overlap: int = 200
supported_types: List[str] = None
whisper_model_size: str = "base" # options: tiny, base, small, medium, large
device: str = "cuda" if torch.cuda.is_available() else "cpu"
def __post_init__(self):
self.supported_types = [
# Previous file types
'.pdf', # PDF documents
'.docx', # Word documents
'.pptx', # PowerPoint presentations
'.xlsx', # Excel spreadsheets
'.txt', # Plain text files
'.csv', # CSV files
'.json', # JSON files
'.html', # HTML files
'.eml', # Email files
'.md', # Markdown files
# New media file types
'.mp3', # Audio files
'.wav', # Audio files
'.m4a', # Audio files
'.mp4', # Video files
'.avi', # Video files
'.mov', # Video files
'.mkv', # Video files
'.webm' # Video files
]
class MediaProcessor:
"""Handles audio and video processing using Whisper"""
def __init__(self, config: FileConfig):
self.config = config
self.logger = logging.getLogger(__name__)
self.whisper_model = whisper.load_model(
config.whisper_model_size,
device=config.device
)
def extract_audio_from_video(self, video_path: str) -> str:
"""Extract audio from video file"""
try:
with tempfile.NamedTemporaryFile(suffix='.wav', delete=False) as temp_audio:
video = mp.VideoFileClip(video_path)
video.audio.write_audiofile(temp_audio.name, logger=None)
video.close()
return temp_audio.name
except Exception as e:
self.logger.error(f"Error extracting audio from video {video_path}: {str(e)}")
raise
def convert_audio_to_wav(self, audio_path: str) -> str:
"""Convert any audio format to WAV"""
try:
with tempfile.NamedTemporaryFile(suffix='.wav', delete=False) as temp_audio:
audio = AudioSegment.from_file(audio_path)
audio.export(temp_audio.name, format='wav')
return temp_audio.name
except Exception as e:
self.logger.error(f"Error converting audio {audio_path}: {str(e)}")
raise
def transcribe_audio(self, audio_path: str, original_file_path: str) -> str:
"""Transcribe audio using Whisper"""
try:
# Convert to WAV if needed
if not audio_path.endswith('.wav'):
audio_path = self.convert_audio_to_wav(audio_path)
# Transcribe
result = self.whisper_model.transcribe(
audio_path,
verbose=False
)
# Add metadata about timestamps
transcription = ""
for segment in result['segments']:
timestamp = f"[{self._format_timestamp(segment['start'])} -> {self._format_timestamp(segment['end'])}] "
transcription += timestamp + segment['text'] + "\n"
# Clean up temporary files
if audio_path != original_file_path:
os.unlink(audio_path)
return transcription
except Exception as e:
self.logger.error(f"Error transcribing audio {audio_path}: {str(e)}")
if audio_path != original_file_path:
os.unlink(audio_path)
raise
@staticmethod
def _format_timestamp(seconds: float) -> str:
"""Format seconds into HH:MM:SS"""
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
seconds = int(seconds % 60)
return f"{hours:02d}:{minutes:02d}:{seconds:02d}"
class DocumentProcessor:
"""Handles document processing and text extraction"""
def __init__(self, config: FileConfig):
self.config = config
self.logger = logging.getLogger(__name__)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size,
chunk_overlap=config.chunk_overlap
)
self.media_processor = MediaProcessor(config)
def get_file_hash(self, file_path: str) -> str:
"""Generate SHA-256 hash of file"""
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def process_pdf(self, file_path: str) -> str:
"""Process PDF file"""
text = ""
with open(file_path, 'rb') as file:
pdf = pypdf.PdfReader(file)
for page in pdf.pages:
text += page.extract_text() + "\n"
return text
def process_docx(self, file_path: str) -> str:
"""Process Word document"""
doc = Document(file_path)
return "\n".join([paragraph.text for paragraph in doc.paragraphs])
def process_pptx(self, file_path: str) -> str:
"""Process PowerPoint presentation"""
prs = Presentation(file_path)
text = ""
for slide in prs.slides:
for shape in slide.shapes:
if hasattr(shape, "text"):
text += shape.text + "\n"
return text
def process_xlsx(self, file_path: str) -> str:
"""Process Excel file"""
df = pd.read_excel(file_path)
return df.to_string()
def process_text(self, file_path: str) -> str:
"""Process text file"""
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
def process_csv(self, file_path: str) -> str:
"""Process CSV file"""
with open(file_path, 'r', encoding='utf-8') as file:
csv_reader = csv.reader(file)
return "\n".join([",".join(row) for row in csv_reader])
def process_json(self, file_path: str) -> str:
"""Process JSON file"""
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
return json.dumps(data, indent=2)
def process_html(self, file_path: str) -> str:
"""Process HTML file"""
with open(file_path, 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file, 'html.parser')
return soup.get_text()
def process_eml(self, file_path: str) -> str:
"""Process email file"""
with open(file_path, 'r', encoding='utf-8') as file:
msg = email.message_from_file(file)
return f"Subject: {msg['subject']}\nFrom: {msg['from']}\nTo: {msg['to']}\n\n{msg.get_payload()}"
def process_markdown(self, file_path: str) -> str:
"""Process Markdown file"""
with open(file_path, 'r', encoding='utf-8') as file:
return markdown.markdown(file.read())
def process_media(self, file_path: str) -> str:
"""Process audio and video files"""
file_ext = Path(file_path).suffix.lower()
try:
# Handle video files
if file_ext in ['.mp4', '.avi', '.mov', '.mkv', '.webm']:
audio_path = self.media_processor.extract_audio_from_video(file_path)
return self.media_processor.transcribe_audio(audio_path, file_path)
# Handle audio files
elif file_ext in ['.mp3', '.wav', '.m4a']:
return self.media_processor.transcribe_audio(file_path, file_path)
else:
raise ValueError(f"Unsupported media format: {file_ext}")
except Exception as e:
self.logger.error(f"Error processing media file {file_path}: {str(e)}")
raise
def process_file(self, file_path: str) -> List[LangchainDocument]:
"""Process a file and return chunks"""
file_ext = Path(file_path).suffix.lower()
if file_ext not in self.config.supported_types:
raise ValueError(f"Unsupported file type: {file_ext}")
processors = {
'.pdf': self.process_pdf,
'.docx': self.process_docx,
'.pptx': self.process_pptx,
'.xlsx': self.process_xlsx,
'.txt': self.process_text,
'.csv': self.process_csv,
'.json': self.process_json,
'.html': self.process_html,
'.eml': self.process_eml,
'.md': self.process_markdown,
'.mp3': self.process_media,
'.wav': self.process_media,
'.m4a': self.process_media,
'.mp4': self.process_media,
'.avi': self.process_media,
'.mov': self.process_media,
'.mkv': self.process_media,
'.webm': self.process_media
}
processor = processors.get(file_ext)
if not processor:
raise ValueError(f"No processor found for {file_ext}")
text = processor(file_path)
file_hash = self.get_file_hash(file_path)
chunks = self.text_splitter.split_text(text)
return [
LangchainDocument(
page_content=chunk,
metadata={
"source": file_path,
"file_type": file_ext,
"chunk_index": i,
"file_hash": file_hash,
"processed_date": datetime.now().isoformat(),
"is_media_file": file_ext in ['.mp3', '.wav', '.m4a', '.mp4', '.avi', '.mov', '.mkv', '.webm']
}
)
for i, chunk in enumerate(chunks)
]
class RAGPipeline:
"""Main pipeline for RAG document processing"""
def __init__(self,
persist_directory: str,
collection_name: str = "enterprise_docs",
config: Optional[FileConfig] = None):
self.config = config or FileConfig()
self.processor = DocumentProcessor(self.config)
self.db_manager = ChromaDBManager(persist_directory)
self.collection_name = collection_name
self.logger = logging.getLogger(__name__)
def process_directory(self, directory_path: str, batch_size: int = 10):
"""Process all supported files in a directory with batching"""
try:
processed_files = []
failed_files = []
current_batch = []
for root, _, files in os.walk(directory_path):
for file in files:
file_path = os.path.join(root, file)
if Path(file_path).suffix.lower() in self.config.supported_types:
try:
# Process media files individually due to potential memory usage
if Path(file_path).suffix.lower() in ['.mp3', '.wav', '.m4a', '.mp4', '.avi', '.mov',
'.mkv', '.webm']:
documents = self.processor.process_file(file_path)
self.db_manager.add_documents(self.collection_name, documents)
processed_files.append(file_path)
self.logger.info(f"Successfully processed media file {file_path}")
else:
current_batch.append(file_path)
# Process batch when it reaches the batch size
if len(current_batch) >= batch_size:
self._process_batch(current_batch, processed_files, failed_files)
current_batch = []
except Exception as e:
self.logger.error(f"Failed to process {file_path}: {str(e)}")
failed_files.append((file_path, str(e)))
# Process remaining files in the last batch
if current_batch:
self._process_batch(current_batch, processed_files, failed_files)
return {
"processed_files": processed_files,
"failed_files": failed_files,
"total_processed": len(processed_files),
"total_failed": len(failed_files)
}
except Exception as e:
self.logger.error(f"Error processing directory {directory_path}: {str(e)}")
raise
def _process_batch(self, batch: List[str], processed_files: List[str], failed_files: List[tuple]):
"""Process a batch of files"""
for file_path in batch:
try:
documents = self.processor.process_file(file_path)
self.db_manager.add_documents(self.collection_name, documents)
processed_files.append(file_path)
self.logger.info(f"Successfully processed {file_path}")
except Exception as e:
self.logger.error(f"Failed to process {file_path}: {str(e)}")
failed_files.append((file_path, str(e)))
# Also, setup_logging should be defined outside any class
def setup_logging(
log_file: str = "rag_pipeline.log",
log_level: int = logging.INFO,
log_format: str = "%(asctime)s - %(levelname)s - %(message)s"
):
"""Setup logging configuration"""
logging.basicConfig(
level=log_level,
format=log_format,
handlers=[
logging.FileHandler(log_file),
logging.StreamHandler()
]
)
# Example usage
if __name__ == "__main__":
# Setup logging
setup_logging()
# Initialize pipeline with custom configuration
config = FileConfig(
chunk_size=1000,
chunk_overlap=200,
whisper_model_size="base" # Can be changed to "medium" or "large" for better accuracy
)
pipeline = RAGPipeline(
persist_directory="./chroma_db",
collection_name="enterprise_docs",
config=config
)
# Process documents
result = pipeline.process_directory("./documents", batch_size=10)
print(f"Processing complete. Results: {result}")
# test_pipeline.py
import os
from rag_pipeline import RAGPipeline, FileConfig
import yaml
import logging
from tqdm import tqdm
import chromadb
from chromadb.utils import embedding_functions # Add this import
def setup_logging():
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('logs/pipeline_test.log'),
logging.StreamHandler()
]
)
return logging.getLogger(__name__)
def count_files_by_type(directory):
"""Count files by their extensions"""
file_counts = {}
for root, _, files in os.walk(directory):
for file in files:
if not file.startswith('.'): # Skip hidden files
ext = os.path.splitext(file)[1].lower()
if ext:
file_counts[ext] = file_counts.get(ext, 0) + 1
return file_counts
def verify_chromadb_collection(persist_directory, collection_name):
"""Verify that documents were stored in ChromaDB"""
try:
client = chromadb.PersistentClient(path=persist_directory)
embedding_func = embedding_functions.DefaultEmbeddingFunction() # Create embedding function
try:
collection = client.get_collection(
name=collection_name,
embedding_function=embedding_func
)
except Exception:
collection = client.create_collection(
name=collection_name,
embedding_function=embedding_func
)
count = collection.count()
return count
except Exception as e:
logging.error(f"Error verifying ChromaDB collection: {str(e)}")
return 0
def main():
logger = setup_logging()
# Load configuration
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
# Print initial statistics
logger.info("Starting RAG Pipeline Test")
logger.info("\nChecking input files:")
# Count documents
doc_counts = count_files_by_type("data/documents")
logger.info("\nDocument files found:")
for ext, count in doc_counts.items():
logger.info(f"{ext}: {count} files")
# Count media files
media_counts = count_files_by_type("data/media")
logger.info("\nMedia files found:")
for ext, count in media_counts.items():
logger.info(f"{ext}: {count} files")
try:
# Initialize pipeline with error handling for JSON files
pipeline = RAGPipeline(
persist_directory=config["pipeline"]["persist_directory"],
collection_name=config["pipeline"]["collection_name"],
config=FileConfig(**config["file_processing"])
)
# Process directories with better error handling
logger.info("\nProcessing documents...")
doc_results = pipeline.process_directory("./data/documents")
logger.info("\nProcessing media files...")
media_results = pipeline.process_directory("./data/media")
# Verify results
total_processed = doc_results['total_processed'] + media_results['total_processed']
total_failed = doc_results['total_failed'] + media_results['total_failed']
# Verify ChromaDB storage with proper embedding function
total_embeddings = verify_chromadb_collection(
config["pipeline"]["persist_directory"],
config["pipeline"]["collection_name"]
)
# Print summary
logger.info("\n=== Processing Summary ===")
logger.info(f"Total files processed: {total_processed}")
logger.info(f"Total files failed: {total_failed}")
logger.info(f"Total chunks stored in ChromaDB: {total_embeddings}")
if doc_results['failed_files'] or media_results['failed_files']:
logger.info("\nFailed files:")
for file_path, error in doc_results['failed_files'] + media_results['failed_files']:
logger.error(f"{file_path}: {error}")
# Test simple query with proper embedding function
logger.info("\nTesting document retrieval...")
client = chromadb.PersistentClient(path=config["pipeline"]["persist_directory"])
embedding_func = embedding_functions.DefaultEmbeddingFunction()
collection = client.get_collection(
name=config["pipeline"]["collection_name"],
embedding_function=embedding_func
)
test_query = "test query"
results = collection.query(
query_texts=[test_query],
n_results=1
)
if results and results['documents']:
logger.info("✅ ChromaDB query test successful")
else:
logger.warning("⚠️ ChromaDB query test returned no results")
except Exception as e:
logger.error(f"Pipeline test failed: {str(e)}", exc_info=True)
raise
if __name__ == "__main__":
main()
My query testing script based on my documents:
import chromadb
from chromadb.utils import embedding_functions
import logging
from typing import List, Dict
import json
def setup_logging():
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
return logging.getLogger(__name__)
class RAGQueryTester:
def __init__(self, persist_directory: str, collection_name: str):
self.logger = setup_logging()
self.client = chromadb.PersistentClient(path=persist_directory)
self.embedding_function = embedding_functions.DefaultEmbeddingFunction()
self.collection = self.client.get_collection(
name=collection_name,
embedding_function=self.embedding_function
)
def query_database(self, query: str, n_results: int = 3) -> Dict:
"""Execute a query and return results"""
try:
results = self.collection.query(
query_texts=[query],
n_results=n_results
)
return results
except Exception as e:
self.logger.error(f"Error querying database: {str(e)}")
return None
def run_test_queries(self, queries: List[Dict[str, str]]):
"""Run a set of test queries and log results"""
for query_info in queries:
self.logger.info(f"\n=== Testing Query: {query_info['description']} ===")
self.logger.info(f"Query: {query_info['query']}")
results = self.query_database(query_info['query'])
if results and results['documents']:
self.logger.info("\nTop matches:")
for i, (doc, metadata) in enumerate(zip(results['documents'][0], results['metadatas'][0]), 1):
self.logger.info(f"\nMatch {i}:")
self.logger.info(f"Source: {metadata.get('source', 'Unknown')}")
self.logger.info(f"Content: {doc[:200]}...") # Show first 200 chars
else:
self.logger.warning("No results found")
def main():
# Initialize the tester
tester = RAGQueryTester(
persist_directory="./chroma_db",
collection_name="enterprise_docs"
)
# Define test queries
test_queries = [
{
"description": "Company Information Query",
"query": "What is TechCorp Solutions and when was it founded?"
},
{
"description": "Product Features Query",
"query": "What are the features of the Enterprise Cloud Suite?"
},
{
"description": "Sales Performance Query",
"query": "What was the total revenue and growth rate in Q4 2023?"
},
{
"description": "Canvas Features Query",
"query": "What are the main features and capabilities of the new Canvas interface?"
},
{
"description": "Customer Support Query",
"query": "What support tickets have been raised by customers and what was their priority?"
}
]
# Run the tests
tester.run_test_queries(test_queries)
if __name__ == "__main__":
main()
My config.yaml:
# Pipeline Configuration
pipeline:
persist_directory: "./chroma_db"
collection_name: "enterprise_docs"
batch_size: 10
# File Processing
file_processing:
chunk_size: 1000
chunk_overlap: 200
supported_types:
documents:
- ".pdf"
- ".docx"
- ".pptx"
- ".xlsx"
- ".txt"
- ".csv"
- ".json"
- ".html"
- ".eml"
- ".md"
media:
- ".mp3"
- ".wav"
- ".m4a"
- ".mp4"
- ".avi"
- ".mov"
- ".mkv"
- ".webm"
# Media Processing
media:
whisper_model_size: "base" # options: tiny, base, small, medium, large
device: "auto" # auto, cuda, cpu
audio_quality: "medium" # low, medium, high
# Logging
logging:
level: "INFO"
file: "logs/rag_pipeline.log"
format: "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
Conclusion
Building an enterprise-grade RAG pipeline is like constructing a smart library that not only stores your documents but understands and retrieves them intelligently. Through this article, we’ve covered how to build a system that can:
- Process Any Document: Our pipeline can efficiently handle PDFs, Word documents, videos, and audio files. It's like having a universal translator for all your content.
- Scale Smoothly: The system grows with your needs, handling anything from a few documents to millions, just like a well-organized library that can expand from a single shelf to an entire building.
- Stay Reliable: With robust error handling and monitoring, the system keeps running smoothly even when problems occur. Think of it as having a self-healing system that can detect and fix issues automatically.
- Deliver Fast Results: Using modern vector search technology, the system finds relevant information in milliseconds, similar to having a genius librarian who instantly knows where every piece of information is stored.
The Ultimate RAG Pipeline: Building Scalable Document Intelligence Systems was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Senthil E
Senthil E | Sciencx (2024-10-31T13:48:29+00:00) The Ultimate RAG Pipeline: Building Scalable Document Intelligence Systems. Retrieved from https://www.scien.cx/2024/10/31/the-ultimate-rag-pipeline-building-scalable-document-intelligence-systems/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.