
This content originally appeared on Level Up Coding - Medium and was authored by Lucas de Brito Silva
Mastering FastAPI Deployment: Best Practices for Performance, Security, and Scalability in Production

Introduction
When the goal is to run a FastAPI application in a production environment, it is essential to consider some fundamental aspects. According to the official documentation, one of the best practices is to use containers to facilitate the deployment and scalability of APIs. Containers, such as those provided by Docker, ensure that the application’s dependencies and environment are standardized, allowing the “productionization” process to occur more efficiently.
In addition to the use of containers, other critical factors for optimizing performance include specific Gunicorn configurations, such as the number of workers and the process management model. Below, we will explore these and other aspects in detail that contribute to better FastAPI performance in production.
Using Containers
Deploying APIs in production with FastAPI often involves using Docker containers, a well-established practice that offers isolation for the application and its dependencies, keeping them separate from other containers and services on the system. This not only simplifies dependency management but also ensures that the application environment remains consistent across different executions.
Additionally, containers have a significantly lower resource consumption compared to virtual machines, as they typically run only a single isolated process. This reduced overhead is particularly advantageous for APIs, as it facilitates security, network configurations, development, and deployment.
The use of containers introduces the concept of container images, which are essentially ready-to-use templates from which containers are launched. These images contain specific versions of the necessary files, libraries, and configurations, ensuring predictability and consistency in the application’s behavior. In short, a container image acts as a template that, when executed, creates a container with the necessary instructions to run the application in isolation.
Containers remain active as long as the main command or configured process is running — exactly what is expected for FastAPI-based APIs. However, if no active processes are running, the container is automatically terminated.
Here is an example of a basic Dockerfile for a FastAPI application:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./app /code/app
CMD ["fastapi", "run", "app/main.py", "--port", "80"]
This file is usually saved as Dockerfile, and to build the image, simply execute the following command:
docker build -t api-image .
And to run the container, the command would be:
docker run -d --name mycontainer -p 80:80 api-image
This process works perfectly, as long as some prerequisites are met, such as:
- Correct organization of directories and files (refer to: FastAPI Docker — Directory Structure);
- A requirements.txt that correctly lists the application dependencies (see more at: FastAPI Docker — Package Requirements);
- Error-free code in the main.py file (refer to the documentation: FastAPI Docker — Creating FastAPI Code).
After understanding the creation and use of containers, it’s essential to know other factors that optimize the use of APIs in production. Below, we will detail important points such as:
- HTTPS;
- Startup configurations;
- Automatic restarts;
- Replication;
- Memory optimization.
HTTPS
When discussing HTTP and HTTPS protocols, it’s important to highlight that HTTPS offers a much higher level of security, as it uses encryption to protect the data transfer between the client and server. This is crucial for APIs, especially when they interact with external applications, where the protection of sensitive data becomes a priority.
In the official FastAPI documentation, there is a clear recommendation that HTTPS should be used whenever possible, particularly in production. Many hosting providers offer free SSL certificates, which simplifies the configuration of HTTPS connections.
Furthermore, if your application is behind a Proxy or Load Balancer, adjustments are necessary in the FastAPI application’s startup command. To ensure that the HTTP headers sent by the proxy are correctly forwarded to the application, you should add the --proxy-headers option. This ensures that the FastAPI application properly processes information about the original client (such as the IP address) in proxy scenarios.
Here is an updated example of the Dockerfile, with the inclusion of the --proxy-headers parameter:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./app /code/app
CMD ["fastapi", "run", "app/main.py", "--proxy-headers", "--port", "80"]
This command allows your FastAPI application to work properly behind a proxy while maintaining the security and integrity of the transferred data.
Startup Applications
There are several ways to initialize a container with FastAPI, from using Docker to more advanced solutions like Kubernetes. The choice of the ideal tool depends on the API’s complexity, the available infrastructure, and the project’s scope. The most common options include:
- Docker: A simple and efficient solution for local development and less complex deployments. It is ideal for testing and running the application in an isolated environment with all dependencies configured.
- Docker Compose: Useful for orchestrating multiple containers that need to work together, such as when an API depends on a database or other services.
- Kubernetes: A robust tool suitable for managing containers at scale. It offers high availability, scalability, and automatic load balancing, making it ideal for large-scale APIs and distributed systems.
The choice between these options should consider the project’s size, scalability requirements, and the level of automation desired in the deployment process.
Restarts
In production environments, it is essential to ensure that the FastAPI application can recover from unexpected failures. A common practice is to configure automatic restart mechanisms to prevent the application from becoming unavailable after an error. This can be done using features provided by Docker and Kubernetes.
A good practice in API development is to handle known errors directly in the code, returning appropriate status codes, such as 422 Unprocessable Entity, for invalid inputs. For example, if a user sends a boolean value instead of a number, the code can return this status without crashing the application.
However, some errors may be unpredictable and difficult to foresee. In these cases, rather than allowing the application to become completely unavailable, it is recommended to use an automatic restart mechanism. In Docker, this can be configured with the --restart option, which causes the container to restart automatically in case of failure.
Here is an updated example of the Dockerfile with the restart configuration:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./app /code/app
CMD ["fastapi", "run", "app/main.py", "--proxy-headers", "--port", "80", "--restart"]
In Docker Compose, you can add the restart configuration directly in the docker-compose.yml file:
version: '3'
services:
app:
image: api-image
restart: always
ports:
- "80:80"
This ensures that in case of an unexpected failure, the application will restart automatically, minimizing the impact in production.
Replication
The need for replication and scalability is one of the main reasons for optimizing the performance of APIs in production. In development environments, it’s generally not necessary to split requests across multiple processes, but in production, this practice is essential to ensure that the application remains efficient under high user load.
Process replication, also known as the use of multiple workers, is an approach recommended in the FastAPI documentation for handling a large volume of requests. In situations where the API is running on a machine with multiple CPU cores, or when traffic is too high for a single process, it is possible to use several processes (or “workers”) to divide the load. This ensures that multiple requests can be processed simultaneously, increasing efficiency and reducing response time.
This approach involves running multiple instances of the same API, where all instances “listen” for requests on the same port and divide the work among themselves. FastAPI, along with tools like Uvicorn and Gunicorn, makes it easy to configure these multiple workers, providing greater resilience and scalability.
Uvicorn vs. Gunicorn
Both Uvicorn and Gunicorn are popular for running APIs with FastAPI, but they have differences in process management:
- Uvicorn is a lightweight and efficient ASGI server, ideal for simple, smaller-scale scenarios.
- Gunicorn, on the other hand, is a more robust WSGI server that can manage multiple processes more efficiently, especially in large-scale production environments. It also offers additional features like better worker control and automatic failure recovery, making it more suitable for high-availability scenarios.
However, to get the best of both worlds, it’s common to use Gunicorn in combination with Uvicorn (via uvicorn.workers.UvicornWorker), resulting in a powerful server with greater control over processes, and more suited for complex production scenarios.
Example with Uvicorn
Here’s an example of a configuration to start multiple workers using Uvicorn alone:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./app /code/app
CMD ["uvicorn", "app.main:app", "--proxy-headers", "--port", "80", "--workers", "4", "--restart"]
This example uses 4 workers to process requests in parallel, improving the API’s ability to handle multiple simultaneous connections.
Example with Gunicorn
If the application requires more control and resilience, Gunicorn with Uvicorn is a more robust option. Below is an example of a Dockerfile using Gunicorn with 4 workers:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./app /code/app
CMD ["gunicorn", "-k", "uvicorn.workers.UvicornWorker", "app.main:app", "--workers", "4", "--bind", "0.0.0.0:80"]
This configuration takes advantage of Uvicorn’s efficiency but with Gunicorn’s robustness for process management, ensuring high availability and better performance in production environments.
Memory
When optimizing APIs for production, memory management is a crucial aspect that requires attention, especially when dealing with multiple workers. Unlike other optimizations, such as process tuning or proxy configuration, memory management heavily depends on the careful analysis of the specific needs of the application.
Each worker process running your application consumes a certain amount of memory, which includes execution variables, machine learning models (if used), cache, and other necessary data. In the case of multiple workers, it’s important to understand that each worker consumes its own portion of memory, and they do not share memory between them. This means that the total memory consumption will be the sum of the consumption of each worker.
When configuring multiple workers, a key point is ensuring that the server or instance running the application has enough RAM to support the load of each process. For example, if your instance has 10 GB of RAM and each worker consumes about 2 GB, starting 6 workers will exceed the available memory limit, which can lead to serious issues such as crashes or slowness.
Visually, this dynamic can be represented as follows:
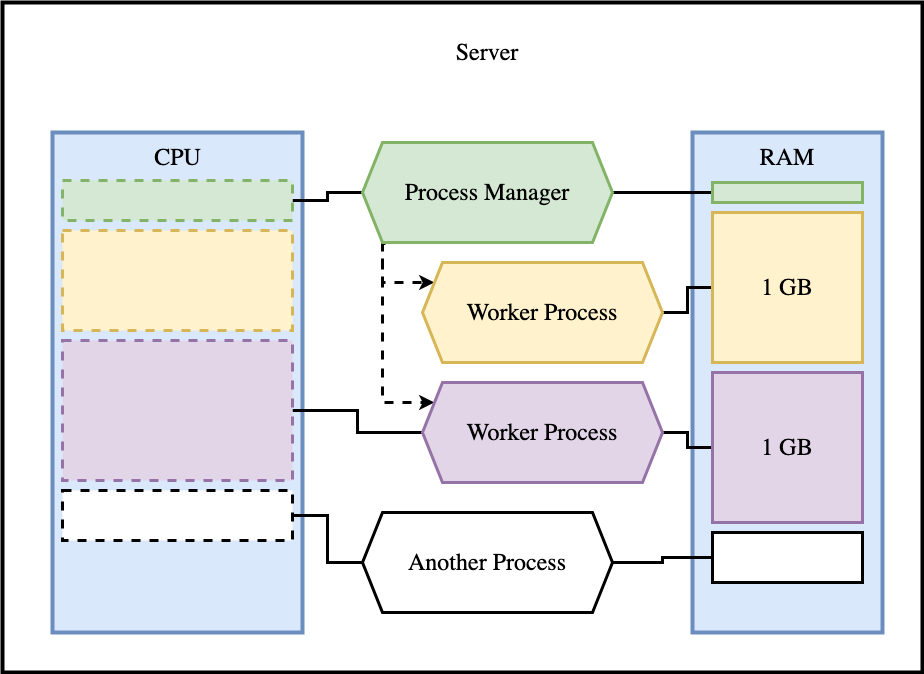
In the image, we see how the process manager distributes CPU usage among the workers and how each worker allocates a specific amount of RAM. This model clearly demonstrates that memory is duplicated for each worker, reinforcing the need for proper planning to avoid resource exhaustion.
Final Considerations
In this article, we explored best practices for optimizing and deploying a FastAPI application in production. We covered crucial aspects such as the use of containers, replication, memory management, and secure protocols, as well as analyzed how Gunicorn and Uvicorn can be used in different production scenarios.
With this detailed overview, you are now better prepared to adjust your API configuration according to your project’s needs. Elements like the number of workers, connection timeout, and the use of threads are just some of the variables available in Gunicorn to maximize performance. Each adjustment can directly impact the scalability and efficiency of your application.
Additionally, it’s important to consider whether FastAPI is truly the best choice for your use case. While it is an excellent option for high-performance APIs and easy to implement, alternatives like Django, Flask, and Bottle also offer distinct advantages, especially in terms of scalability, library integration, and ease of use. Evaluating these points in the context of your project can help you choose the most suitable solution.
Finally, remember that deploying an API in production involves more than just writing optimized code. The security provided by using HTTPS, efficient memory management, and a robust container configuration are essential factors to ensure success in production environments. The next step is to apply these configurations, test them in your environment, and adjust them as necessary, always striving for maximum performance, stability, and availability of your application.
Deploying FastAPI in Production: A Guide to Optimizing FastAPI Performance with Gunicorn was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Lucas de Brito Silva
Lucas de Brito Silva | Sciencx (2024-11-05T17:50:16+00:00) Deploying FastAPI in Production: A Guide to Optimizing FastAPI Performance with Gunicorn. Retrieved from https://www.scien.cx/2024/11/05/deploying-fastapi-in-production-a-guide-to-optimizing-fastapi-performance-with-gunicorn/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.