
This content originally appeared on HackerNoon and was authored by Abhishek Gupta
\ Apache Flink provides a powerful engine to process data in real time. If we can answer what, where, when and how of data processing we can build a very robust stream processing pipeline using Apache Flink and Apache Beam.
What
like what is the output of the computation, are we doing sum, min, max, average etc or a complex transformation within the pipeline. Complex computation could be building histogram, training machine learning models, building a recommendation engine.
Where
Where is computation happening, like using in memory windows of variety type like fixed window, sliding windows or session windows. Some use cases can have no notion of windowing like classic batch processing.
When
when is the time when results are used. This decision can be made using triggers and watermarks*. Triggers* are conditions defined on the stream to fire the data for using as a final output. Trigger firing is dependent on the generated watermark in the system*.*
How
Lastly and most important question to answer is what type of accumulation method is used
discarding - where all results are independent
accumulating - where later results build upon prior one
retracting - where is uses accumulating value plus retraction of previously emitted value
\
\
\
\

\
Processing time vs Event time?
Consider a group fitness activity like hike with multiple online users reporting a group activity on a health fitness app like strava. Each time a user completes a task, he gets a score. These users are using mobile device to report the activity. Now during this activity, some users might lose internet connectivity. These individual users also belong to some regional teams like users in team1, team2 etc The team which scores highest points wins. The team score is calculated based on total sum of each team member’s score. Imagine a sql table TeamScore with following entries.
\
> SELECT * FROM TeamScore ORDER BY EventTime;
------------------------------------------------------
| Name | Team | Score | EventTime | ProcessingTime |
------------------------------------------------------
| jeremy | Team1 | 9 | 07:00:26 | 07:05:19 |
| allen | Team1 | 4 | 07:01:26 | 07:08:19 |
| michael| Team1 | 3 | 07:02:26 | 07:05:39 |
| holly | Team2 | 2 | 07:03:06 | 07:07:06 |
| kevin | Team2 | 6 | 07:03:39 | 07:06:13 |
| amie | Team3 | 3 | 07:04:19 | 07:06:39 |
| shash | Team3 | 5 | 07:06:39 | 07:07:19 |
| rudie | Team4 | 9 | 07:07:26 | 07:08:39 |
| parker | Team4 | 1 | 07:07:30 | 07:08:20 |
| karen | Team4 | 2 | 07:08:01 | 07:08:34 |
| hari | Team4 | 2 | 07:08:20 | 07:08:55 |
| shari | Team4 | 3 | 07:08:25 | 07:09:30 |
------------------------------------------------------
\
Here, Event time is the time at which the event actually occurred, usually based on the timestamp within the event data itself. In our table above this is the time when the group activity was completed by each individual user. Processing time refers to the time at which a specific event is processed by the system. The processing for the score is time at which the score was observed by the system.
\ Event Time is crucial in this application since it requires precise accuracy based on when events actually occurred.
Lets process this data
what is a flink pipeline ?
Typical flink infra structure contains: job manager and one or more task managers. The task managers help horizontally scale the pipeline, job manager helps as a orchestrator to the user code (pipeline). User program runs on one or more task managers. Imagine flink as a stateless processing engine which hosts one or more user functions called DAG(directed acyclic graph) for you transformations.
\
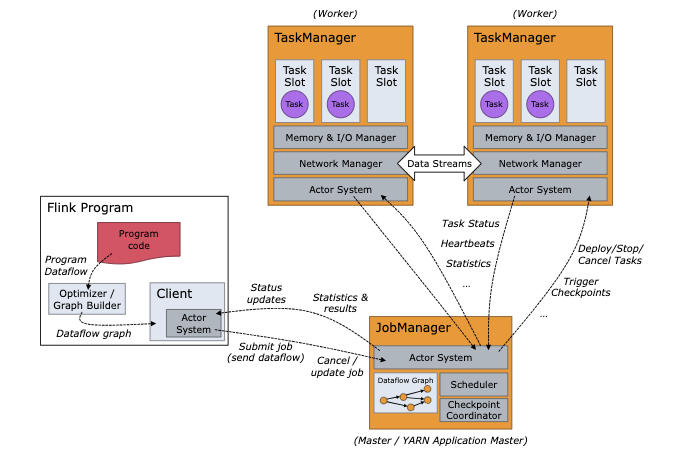
\ In the above diagram, the user code is represented by the “Flink program” block. We will talk about how to build and deploy this user program in the sections below as we understand more on event time procressing.
The stack
In our proof of concept, we will have following deployment. The Flink pipeline hosts Kafka reader and writer along with the transformations. This together runs as a Flink pipeline. Console producer and console consumer are Kafka command line utilities which are used to write and read to and from Kafka.
\

\
What does our pipeline do?
- Pipeline reads the data from kafka from ==psource==
- updates the watermark based on the timestamp received from the event. Now this is very important step. We will talk about this in little more details
- passed the data to a sliding window of 5 mins duration which slides every 1 mins
- further there could be one or more transformations that can be applied
- write data to kafka to ==pemit== topic
\ Here is the code for this pipeline:
public class PipelineDataHandler {
private static final Logger LOGGER = LoggerFactory.getLogger(PipelineDataHandler.class);
final static Counter counter = Metrics.counter("stats", "event-times");
public static void main(String[] args) {
DataPipelineOptions dataPipelineOptions = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(DataPipelineOptions.class);
Pipeline pipeline = Pipeline.create(dataPipelineOptions);
counter.inc();
LOGGER.info("dataPipelineOptions.getBootstrapServers(): {}, {}", dataPipelineOptions.getBootstrapServers(),
dataPipelineOptions.getInputTopic());
try {
PCollection<KV<String, InputData>> pCollection = pipeline.apply(KafkaIO.<byte[], byte[]>readBytes()
.withBootstrapServers(dataPipelineOptions.getBootstrapServers())
.withTopics(Arrays.asList(dataPipelineOptions.getInputTopic()))
.withKeyDeserializer(ByteArrayDeserializer.class)
.withValueDeserializer(ByteArrayDeserializer.class)
.withTimestampPolicyFactory((tp, previousWatermark) -> new CustomFieldTimePolicy(previousWatermark))
.withoutMetadata())
.apply(Values.<byte[]>create())
.apply(ParDo.of(new DoFn<byte[], KV<String, InputData>>() {
@ProcessElement
public void processElement(@Element byte[] data, ProcessContext c) {
try {
String dataStr = new String(data);
InputData inputData = getInputData(dataStr);
LOGGER.info("recieved : {}", inputData);
KV<String, InputData> kv = KV.of(inputData.getId(), inputData);
LOGGER.debug("KV: {}", kv);
c.output(kv);
} catch (Exception ex) {
ex.printStackTrace();
}
}
}));
PCollection<KV<String, Iterable<InputData>>> outputData = toEventWindows(pCollection);
LOGGER.info("calling kafka writer");
outputData.apply("writeToKafka", ParDo.of(new KakaWriter(dataPipelineOptions)));
pipeline.run();
} catch (Exception ex) {
LOGGER.error("failed to deploy. error: {}", ex.getMessage(), ex);
}
}
}
\ Now, pay attention to ==CustomFieldTimePolicy== class. ==CustomFieldTimePolicy== allows us to specify the policy on the pipeline and this is where the pipeline decides to move the watermark based on event time i.e. timestamp coming from the event and not clock time. Hey, wait a minute, “what exactly is watermark??”
\ watermark is a timestamp that tracks the progress of event time in a data stream. Watermarks are metadata markers that are not actual data events. They are used to ensure that events are processed accurately and in a timely manner. In order to work with event time, Flink needs to know the events timestamps, meaning each element in the stream needs to have its event timestamp assigned.
\ Here is the ==CustomFieldTimePolicy== class:
public class CustomFieldTimePolicy extends TimestampPolicy<byte[], byte[]>{
private static final Logger LOGGER = LoggerFactory.getLogger(CustomFieldTimePolicy.class);
protected Instant currentWatermark;
public CustomFieldTimePolicy(Optional<Instant> previousWatermark){
currentWatermark = previousWatermark.orElse(BoundedWindow.TIMESTAMP_MIN_VALUE);
}
@Override
public Instant getTimestampForRecord(PartitionContext ctx, KafkaRecord<byte[], byte[]> record) {
String value = new String(record.getKV().getValue());
Instant instant = new Instant();
Long eventTime = getTimestamp(value);
currentWatermark = instant.withMillis(eventTime);
LOGGER.debug("record: {}", record.getKV().getValue());
return currentWatermark;
}
@Override
public Instant getWatermark(PartitionContext ctx) {
return currentWatermark;
}
public Long getTimestamp(String data){
String[] values = data.split(",");
LOGGER.info("size: " + values.length);;
return Long.valueOf(values[0].trim());
}
}
\ Here is the definition of the sliding window:
public static PCollection<KV<String, Iterable<InputData>>> toEventWindows(
PCollection<KV<String, InputData>> inputs) {
return inputs
.apply("ApplySlidingWindows",
Window.<KV<String, InputData>>into(FixedWindows.of(Duration.standardSeconds(300)))
.every(Duration.standardSeconds(60)))
.triggering(AfterWatermark.pastEndOfWindow()
.withLateFirings(AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(Duration.standardSeconds(1))))
.withAllowedLateness(Duration.standardSeconds(1)).discardingFiredPanes())
.setCoder(KvCoder.of(StringUtf8Coder.of(), SerializableCoder.of(InputData.class)))
.apply("GroupById", GroupByKey.create());
}
\ Read input data from kafka source:
public static InputData getInputData(String data) {
try {
String[] fields = data.split(",");
LOGGER.debug("data: {}, fields: {}", data, fields);
if (fields.length != 6) {
return null;
}
LOGGER.debug("fields length: {}", fields.length);
long ts = Long.valueOf(fields[0]);
String id = fields[1];
String name = fields[2];
int score = Integer.valueOf(fields[3]);
int age = Integer.valueOf(fields[4]);
String gender = fields[5];
LOGGER.debug("ts: {}", ts);
InputData inputData = new InputData.Builder(id)
.atTimestamp(ts)
.withName(name)
.withAge(age)
.withScore(score)
.withGender(gender)
.build();
LOGGER.debug("inputdata: {}", inputData);
return inputData;
} catch (Exception ex) {
ex.printStackTrace();
}
return null;
}
\ Kafka reader:
KafkaIO.<byte[], byte[]>readBytes()
.withBootstrapServers(dataPipelineOptions.getBootstrapServers())
.withTopics(Arrays.asList(dataPipelineOptions.getInputTopic()))
.withKeyDeserializer(ByteArrayDeserializer.class)
.withValueDeserializer(ByteArrayDeserializer.class)
\ Kafka Writer:
public class KakaWriter extends DoFn<KV<String, Iterable<InputData>>, Void> {
private String topic;
private Map<String, Object> config;
private transient KafkaProducer<byte[], byte[]> producer = null;
private static final Logger LOGGER = LoggerFactory.getLogger(KakaWriter.class);
public KakaWriter(DataPipelineOptions pipelineOptions){
try {
this.topic = pipelineOptions.getOutputTopic();
this.config = ImmutableBiMap.<String, Object>of (
"bootstrap.servers", pipelineOptions.getBootstrapServers()
);
}catch(Exception ex){
ex.printStackTrace();
}
}
@StartBundle
public void startBundle() throws Exception {
try {
if(producer == null){
producer = new KafkaProducer<>(config);
}
}catch(Exception ex){
ex.printStackTrace();
}
}
@Teardown
public void teardown() throws Exception {
producer.flush();
producer.close();
}
@ProcessElement
public void processElement(ProcessContext ctx, final BoundedWindow window) throws Exception {
try {
KV<String, Iterable<InputData>> data = ctx.element();
LOGGER.info("sending to kafka: {}, {}", topic, data);
Iterable<InputData> events = data.getValue();
Iterator<InputData> eventIterator = events.iterator();
while(eventIterator.hasNext()){
send(data.getKey(), eventIterator.next(), window);
}
}catch(Exception ex) {
ex.printStackTrace();
}
}
public void send(String key, InputData inputData, final BoundedWindow window){
LOGGER.info("{} : triggerring windows -------------> key: {}, value: {}", window.maxTimestamp(), key, inputData.getName());
ProducerRecord<byte[], byte[]> record = new ProducerRecord<byte[], byte[]>(topic, 1, key.getBytes(), inputData.getName().getBytes());
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata rm, Exception exception){
LOGGER.info("onCompletion: {}, {}", rm, exception);
}
});
}
}
Putting it together
In order to deploy our pipeline we need the flink job manager, task manager and kafka running. Here are the steps to bring up the docker containers with job manager, task manager and kafka using docker command line interface (CLI)
FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager"
docker network create flink-network
docker run \
--rm \
--name=jobmanager \
--network flink-network \
--publish 8081:8081 \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:1.17.2-scala_2.12 jobmanager
docker run \
--rm \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:1.17.2-scala_2.12 taskmanager
# kafka
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/datastream/kafka/
docker run \
--rm \
--name broker \
--network flink-network \
apache/kafka:latest
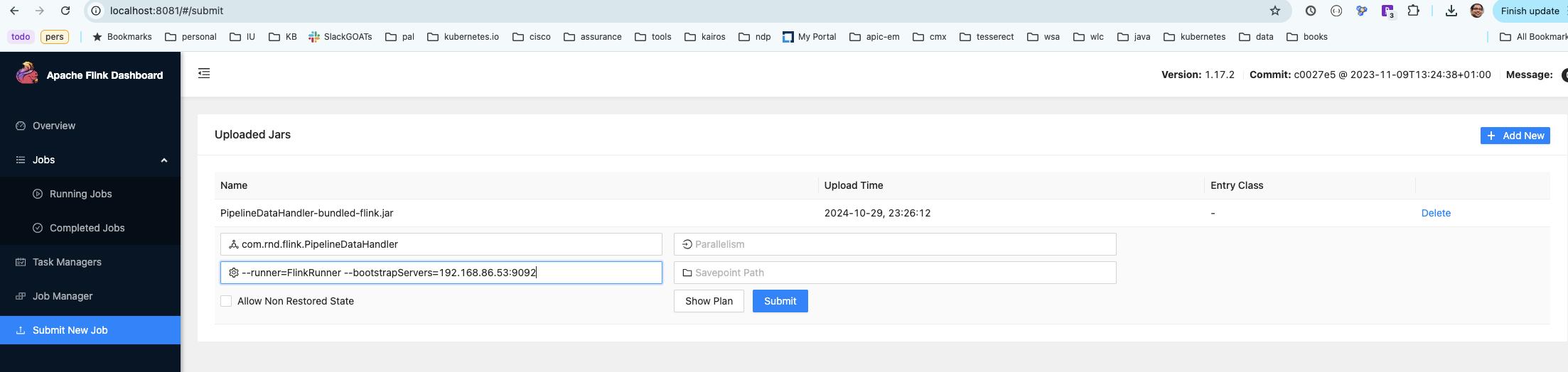
\ Once you have the flink/kafka stack running, you can build and deploy the pipeline the pipeline code using flink CLI.
flink/flink-1.17.0/bin/flink run -d -m \
localhost:8081 -c com.rnd.flink.PipelineDataHandler \
target/PipelineDataHandler-bundled-flink.jar \
--runner=FlinkRunner \
--bootstrapServers=192.168.86.53:9092
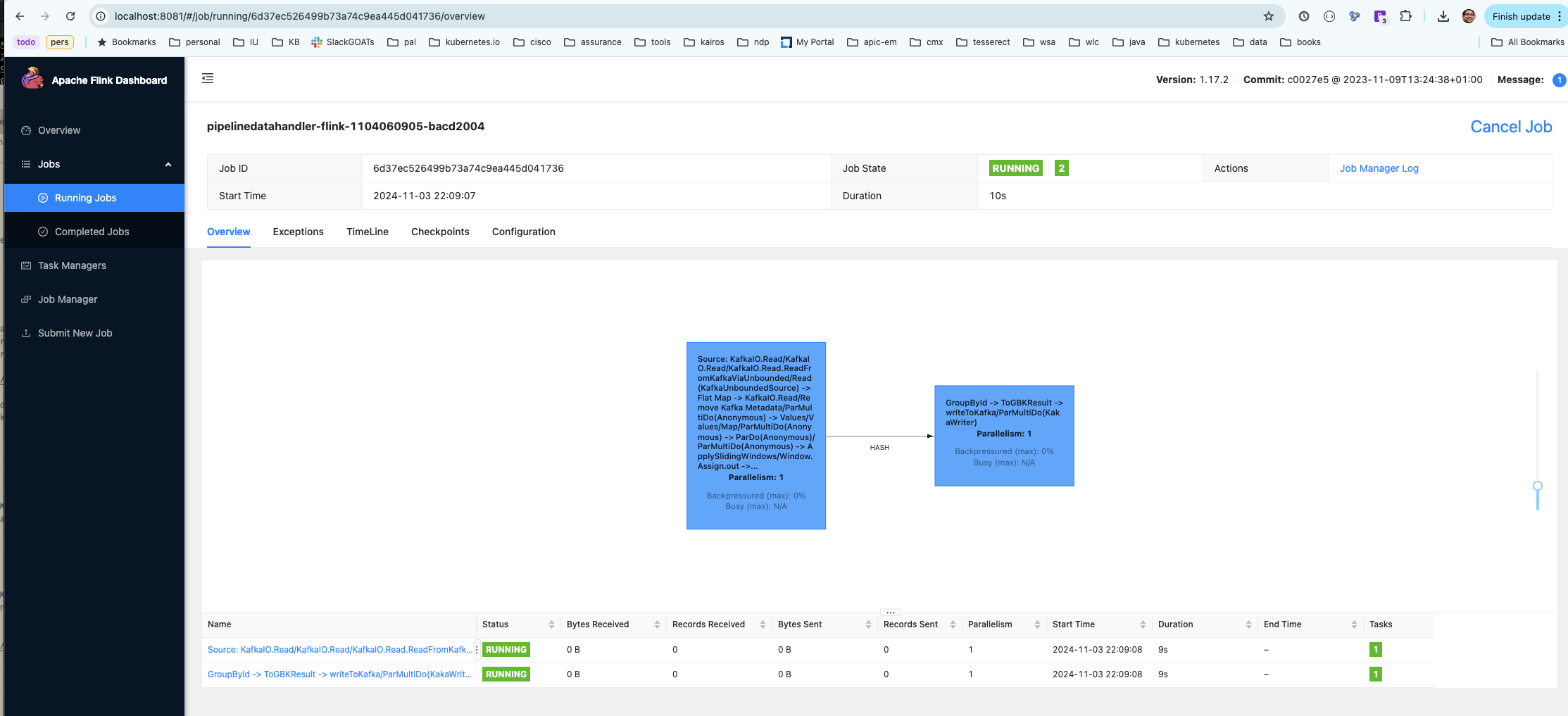
\ Or you can use the flink console to deploy the pipeline:
\
\
\
\
Let’s fire it up!
Its a eureka moment when you see you pipeline running on flink stack which is ready to process the event data in real time with event time processing enabled. Most of the real time analytics systems like recommendation engines, live messaging, gaming etc heavily use event time processing semantics.
\ start the producer
▶ docker ps -a | grep kafka
e6b614fe9bc9 apache/kafka:latest "/__cacert_entrypoin…" 22 hours ago Up 22 hours 9092/tcp broker
2049072cee53 2679/kafka:0.9.0.1 "start-kafka" 23 hours ago Exited (143) 22 hours ago container-kafka-1
(base)
projects/kafka/bin
▶ docker exec -it e6b614fe9bc9 bash
e6b614fe9bc9:/$ cd /opt/kafka/bin
e6b614fe9bc9:/opt/kafka/bin$ echo "`date +'%s'000`,100,testuser,10,27,F" | /opt/kafka/bin/kafka-console-producer.sh --broker-list 0.0.0.0:9092 --topic psource
e6b614fe9bc9:/opt/kafka/bin$ echo "`date +'%s'000`,100,testuser,10,27,F" | /opt/kafka/bin/kafka-console-producer.sh --broker-list 0.0.0.0:9092 --topic psource
e6b614fe9bc9:/opt/kafka/bin$ echo "`date +'%s'000`,100,testuser,10,27,F" | /opt/kafka/bin/kafka-console-producer.sh --broker-list 0.0.0.0:9092 --topic psource
e6b614fe9bc9:/opt/kafka/bin$ echo "`date +'%s'000`,100,testuser,10,27,F" | /opt/kafka/bin/kafka-console-producer.sh --broker-list 0.0.0.0:9092 --topic psource
e6b614fe9bc9:/opt/kafka/bin$
\ start the consumer
▶ docker exec -it e6b614fe9bc9 bash
e6b614fe9bc9:/$ cd /opt/kafka/bin/
e6b614fe9bc9:/opt/kafka/bin$ ./kafka-console-consumer.sh --bootstrap-server 0.0.0.0:9092 --topic pemit
\ You try replaying data with older timestamps, as long as flink has not see the data i.e. watermark has not moved, flink will process the data based on event time.
References
https://nightlies.apache.org/flink/flink-docs-master/docs/concepts/flink-architecture/
Akidau, T., Chernyak, S., & Lax, R. (2018). Streaming systems: the what, where, when, and how of large-scale data processing. " O'Reilly Media, Inc.".
https://hub.docker.com/r/apache/kafka
https://www.oreilly.com/radar/the-world-beyond-batch-streaming-101/
This content originally appeared on HackerNoon and was authored by Abhishek Gupta
Abhishek Gupta | Sciencx (2024-11-08T07:47:04+00:00) Event Time Processing with Flink and Beam – Power of Real time Analytics. Retrieved from https://www.scien.cx/2024/11/08/event-time-processing-with-flink-and-beam-power-of-real-time-analytics/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.