
This content originally appeared on HackerNoon and was authored by Segmentation
:::info Authors:
(1) Zhaoqing Wang, The University of Sydney and AI2Robotics;
(2) Xiaobo Xia, The University of Sydney;
(3) Ziye Chen, The University of Melbourne;
(4) Xiao He, AI2Robotics;
(5) Yandong Guo, AI2Robotics;
(6) Mingming Gong, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence;
(7) Tongliang Liu, The University of Sydney.
:::
Table of Links
3. Method and 3.1. Problem definition
3.2. Baseline and 3.3. Uni-OVSeg framework
4. Experiments
6. Broader impacts and References
4.3. Ablation study
We conduct an extensive ablation study to demonstrate the contribution of each component of our framework.
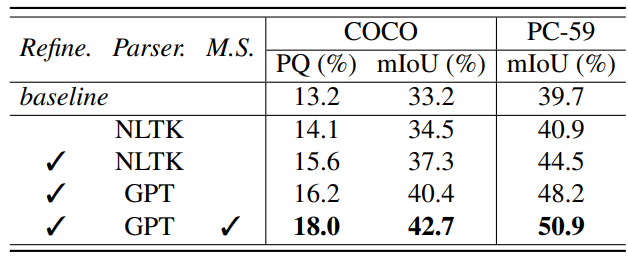
\ Mask-text alignment. Compared to the straightforward baseline, as shown in Tab. 3, our proposed Uni-OVSeg achieves significant gains of 4.8% PQ and 9.5% mIoU on the COCO dataset, and 11.2% mIoU on the PASCAL Context-59 dataset. This demonstrates our method effectively align objects in images and entities in text descriptions, generalising the CLIP embedding space from the image level to pixel level. By resorting to the refinement of text descriptions, new texts are more correlated with the corresponding images, improving the mIoU from 34.5% to 37.3% on the COCO dataset. Compared to the traditional NLP toolkit (NLTK) [3], ChatGPT-based parser extracts more reliable entities from text descriptions, which achieves obvious improvements of 3.1% and 3.7% mIoU on the COCO and PASCAL Context-59 datasets, respectively. Finally, the proposed multi-scale ensemble strategy that leverages the multi-scale information of objects within the images, stabilise the mask-text matching, which achieves a performance gain of 1.8% PQ on the COCO datasets.
\ Multi-scale ensemble in mask-text matching. The quality of correspondence between masks and entities is an essential part of mask-text matching. To investigate the impact of multi-scale information on this correspondence, as illustrated in Tab. 4, we use masks and semantic classes from
\

\
\ the ADE20K and COCO datasets, reporting the Top1 accuracy and forward time per sample. We first resize input images to multiple resolutions and extract visual features via the clip visual encoder. Given ground-truth masks, regional features are pooled from CLIP visual features and projected into the clip embedding space. Each regional embedding is classified by text embeddings. Taking into account the trade-off between performance and latency, we adopt the sizes of 869 × 896 and 1024 × 1024 as default.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Segmentation
Segmentation | Sciencx (2024-11-12T22:27:06+00:00) The Impact of Mask-Text Alignment and Multi-Scale Ensemble on Uni-OVSeg’s Segmentation Accuracy. Retrieved from https://www.scien.cx/2024/11/12/the-impact-of-mask-text-alignment-and-multi-scale-ensemble-on-uni-ovsegs-segmentation-accuracy/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.