
This content originally appeared on HackerNoon and was authored by Segmentation
:::info Authors:
(1) Zhaoqing Wang, The University of Sydney and AI2Robotics;
(2) Xiaobo Xia, The University of Sydney;
(3) Ziye Chen, The University of Melbourne;
(4) Xiao He, AI2Robotics;
(5) Yandong Guo, AI2Robotics;
(6) Mingming Gong, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence;
(7) Tongliang Liu, The University of Sydney.
:::
Table of Links
3. Method and 3.1. Problem definition
3.2. Baseline and 3.3. Uni-OVSeg framework
4. Experiments
6. Broader impacts and References
A. Framework details
Inputs. For input images, we initially apply a random horizontal flip to each image. Subsequently, the image is randomly scaled to a resolution within the range of 716 × 716 to 1075 × 1075 resolutions. Finally, a crop of 896 × 896 resolutions is extracted from the scaled image to serve as the input. Regarding the category names, we construct a sentence using a prompt and tokenise it using a lower-cased byte pair encoding (BPE). For the visual prompt, we create a uniform grid of points with dimensions h × w, which is aligned with the center of the pixels.
\ CLIP encoder. In general, the CLIP encoder can be any architecture. Motivated by the scalability of different input resolutions, we employ a ConvNext-based CLIP model to serve as both the image and text encoders. The image encoder is configured as a ConvNext-Large model, comprising four stages. Each stage contains a different number of blocks: 3 in the first, 3 in the second, 27 in the third, and 3 in the fourth. In contrast, the text encoder is structured as a 16-layer transformer, each layer being 768 units wide and featuring 12 attention heads. We harness the power of multi-scale features extracted by the image encoder. These features are represented as feature maps of varying widths and scales: a 192-wide feature map downscaled by a factor of 4, a 384-wide map downscaled by 8, a 768-wide map downscaled by 16, and a 1536-wide map downscaled by 32.
\ Pixel decoder. Following Mask2Former [13], we incorporate a lightweight pixel decoder based on the widely used Feature Pyramid Network (FPN) architecture [41]. We first adopt a 6-layer multi-scale deformable transformer on the multi-scale features to aggregate contextual information. Afterward, we upscale the low-resolution feature map in the decoder by a factor of 2 and then combine it with the corresponding resolution feature map from the backbone, which has been projected to match channel dimensions. This projection is achieved through a 1×1 convolution layer, followed by Group Normalization (GroupNorm). Subsequently, the merged features undergo further processing with an additional 3×3 convolution layer, complemented by GroupNorm and ReLU activation. This procedure is applied iteratively, beginning with the 32× downscaled feature map, until we attain a final feature map that is 4× downscaled. To generate pixel-wise embeddings, a single 1×1 convolution layer is applied at the end. Throughout the pixel decoder, all feature maps maintain a consistent dimension of 256 channels.
\ Visual prompt encoder. We have two types of visual prompts, including points and bounding boxes. Each type of prompts is mapped to 256-wide embeddings as follows. A point is first converted into a small bounding box. We represent a bounding box by an embedding pair, including the sine position embedding of its top-left and bottom-right corners. Afterward, we use two extra learnable embeddings to indicate these two corners.
\
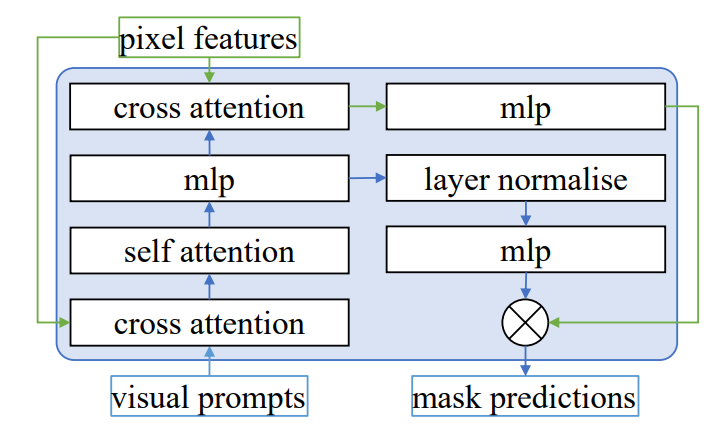
\ Mask decoder. Following Mask2Former, we use a similar transformer decoder design. Each visual prompt embedding within our framework is coupled with a sine positional embedding. As depicted in Fig. 5, our approach utilizes six mask decoder layers, and we apply the same loss function after each layer. Moreover, every decoder layer includes a cross-attention layer. This layer is crucial as it ensures that the final pixel features are enriched with essential geometric information, such as point coordinates and bounding boxes. Besides, in each decoder layer, we use a cross-attention layer, which ensures that the final pixel features have access to critical geometric information (e.g., point coordinates, and boxes). Finally, visual prompt embeddings are fed to a layer normalization, followed by processing through a multiple perception layer (MLP). These processed embeddings are then dot-producted with the pixel features, culminating in the generation of mask predictions.
\
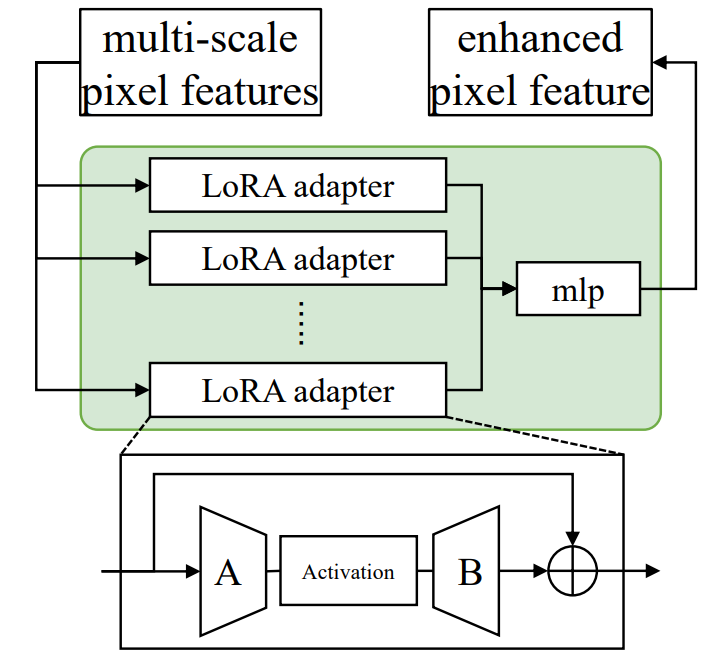
\ Multi-scale feature adapter. The multi-scale feature adapter illustrated in Fig. 6 is designed to refine and enhance pixel features at various scales. This adapter is composed of multiple Low-rank Adapters (LoRA adapters) [27], each specifically tailored to update features at a particular scale. Each LoRA adapter incorporates two linear layers, denoted as A and B, with a non-linear activation function placed in between. The linear layers A and B serve to transform the input data linearly, while the activation function introduces non-linearity, allowing for the modeling of more complex relationships in the data. Each adapter is responsible for handling features at a specific scale, suggesting a hierarchical approach to feature refinement. This modular design allows for a focused and specialized treatment of features depending on their resolution and semantic complexity, which can be particularly advantageous for dense prediction tasks.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Segmentation
Segmentation | Sciencx (2024-11-13T16:00:24+00:00) Advanced Open-Vocabulary Segmentation with Uni-OVSeg. Retrieved from https://www.scien.cx/2024/11/13/advanced-open-vocabulary-segmentation-with-uni-ovseg/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.