
This content originally appeared on HackerNoon and was authored by Gating
:::info Authors:
(1) Soham De, Google DeepMind and with Equal contributions;
(2) Samuel L. Smith, Google DeepMind and with Equal contributions;
(3) Anushan Fernando, Google DeepMind and with Equal contributions;
(4) Aleksandar Botev, Google DeepMind and with Equal contributions;
(5) George Cristian-Muraru, Google DeepMind and with Equal contributions;
(6) Albert Gu, Work done while at Google DeepMind;
(7) Ruba Haroun, Google DeepMind;
(8) Leonard Berrada, Google DeepMind;
(9) Yutian Chen, Google DeepMind;
(10) Srivatsan Srinivasan, Google DeepMind;
(11) Guillaume Desjardins, Google DeepMind;
(12) Arnaud Doucet, Google DeepMind;
(13) David Budden, Google DeepMind;
(14) Yee Whye Teh, Google DeepMind;
(15) David Budden, Google DeepMind;
(16) Razvan Pascanu, Google DeepMind;
(17) Nando De Freitas, Google DeepMind;
(18) Caglar Gulcehre, Google DeepMind.
:::
Table of Links
3 Recurrent Models Scale as Efficiently as Transformers
3.2. Evaluation on downstream tasks
4.2. Efficient linear recurrences on device
4.3. Training speed on longer sequences
5.1. A simple model of the decode step
6. Long Context Modeling and 6.1. Improving next token prediction with longer contexts
6.2. Copy and retrieval capabilities
8. Conclusion, Acknowledgements, and References
B. Complex-Gated Linear Recurrent Unit (CG-LRU)
C. Model Scale Hyper-Parameters
D. Efficient Linear Recurrences on Device
E. The Local Attention Window Size of Griffin
G. Improving Next Token Prediction with Longer Contexts: Additional Results
H. Additional Details of the Copy and Retrieval Tasks
3.1. Scaling curves
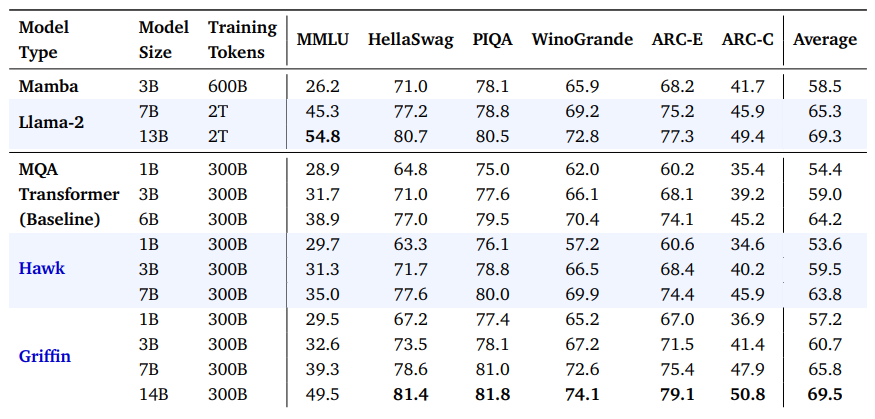
We present our main scaling results in Figure 1(a). All three model families are trained at a range of model scales from 100M to 7B parameters, with an additional Griffin model with 14 billion parameters. We increase the number of training tokens to be roughly proportional to the number of parameters of the model, as prescribed by the Chinchilla scaling laws (Hoffmann et al., 2022). Models are trained on the MassiveText dataset (Hoffmann et al., 2022), previously used to train Gopher (Rae et al., 2021) and Chinchilla (Hoffmann et al., 2022), although we use a slightly different data subset distribution. A sequence length of 2048 tokens was used (see Section 6 for results with longer sequences.) All experiments use the AdamW optimizer (Loshchilov and Hutter, 2017). We tune the learning rate, weight decay and 𝛽2 parameters for small models, and use these runs to identify scaling rules for these hyper-parameters which predict their optimal values for the 7B and 14B models.
\ All three model families demonstrate a linear scaling relationship between the validation loss and training FLOPs (see Figure 1(a); note both axes are in log scale), as previously observed for Transformers by Brown et al. (2020). Notably, Griffin achieves lower validation loss than the Transformer baseline across all FLOPs budgets despite not using any global attention layers. Hawk on the other hand achieves slightly higher validation loss, but this gap appears to close as the training budget increases.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Gating
Gating | Sciencx (2025-01-13T16:23:50+00:00) Griffin Models: Outperforming Transformers with Scalable AI Innovation. Retrieved from https://www.scien.cx/2025/01/13/griffin-models-outperforming-transformers-with-scalable-ai-innovation/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.