
This content originally appeared on HackerNoon and was authored by Gating
:::info Authors:
(1) Soham De, Google DeepMind and with Equal contributions;
(2) Samuel L. Smith, Google DeepMind and with Equal contributions;
(3) Anushan Fernando, Google DeepMind and with Equal contributions;
(4) Aleksandar Botev, Google DeepMind and with Equal contributions;
(5) George Cristian-Muraru, Google DeepMind and with Equal contributions;
(6) Albert Gu, Work done while at Google DeepMind;
(7) Ruba Haroun, Google DeepMind;
(8) Leonard Berrada, Google DeepMind;
(9) Yutian Chen, Google DeepMind;
(10) Srivatsan Srinivasan, Google DeepMind;
(11) Guillaume Desjardins, Google DeepMind;
(12) Arnaud Doucet, Google DeepMind;
(13) David Budden, Google DeepMind;
(14) Yee Whye Teh, Google DeepMind;
(15) David Budden, Google DeepMind;
(16) Razvan Pascanu, Google DeepMind;
(17) Nando De Freitas, Google DeepMind;
(18) Caglar Gulcehre, Google DeepMind.
:::
Table of Links
3 Recurrent Models Scale as Efficiently as Transformers
3.2. Evaluation on downstream tasks
4.2. Efficient linear recurrences on device
4.3. Training speed on longer sequences
5.1. A simple model of the decode step
6. Long Context Modeling and 6.1. Improving next token prediction with longer contexts
6.2. Copy and retrieval capabilities
8. Conclusion, Acknowledgements, and References
B. Complex-Gated Linear Recurrent Unit (CG-LRU)
C. Model Scale Hyper-Parameters
D. Efficient Linear Recurrences on Device
E. The Local Attention Window Size of Griffin
G. Improving Next Token Prediction with Longer Contexts: Additional Results
H. Additional Details of the Copy and Retrieval Tasks
6. Long Context Modeling
In this section, we explore the effectiveness of Hawk and Griffin to use longer contexts to improve their next token prediction, and investigate their extrapolation capabilities during inference. Additionally, we explore our models’ performance on tasks that require copying and retrieval capabilities, both for models that are trained on such tasks, as well as when testing for these capabilities with our pre-trained language models.
6.1. Improving next token prediction with longer contexts
We investigate the ability of Hawk and Griffin to improve their predictions with longer contexts. In particular, we evaluate our trained models by measuring the loss on a held-out books dataset across a range of sequence lengths. Using these long documents allows us to evaluate the ability of the models
\
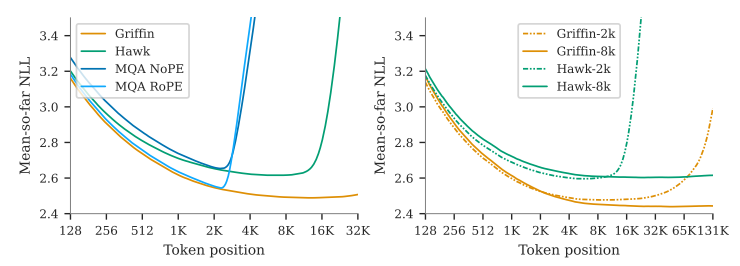
\ to extrapolate, i.e. the ability to accurately predict the next token given contexts that are longer than those seen during training.
\ In Transformers, this ability to extrapolate is largely determined by the positional encoding used for the attention layers (Kazemnejad et al., 2024). For recurrent models, it is instead dictated by the capacity of the model to keep refining the representation stored in the recurrence state as the context becomes longer. From the left plot of Figure 5, we observe that, up to some maximal length, both Hawk and Griffin improve next token prediction given longer contexts, and they are overall able to extrapolate to significantly longer sequences (at least 4x longer) than they were trained on. In particular, Griffin extrapolates remarkably well even when using RoPE (Su et al., 2021) for the local attention layers.
\ The results so far evaluate models that have been trained on sequences of 2048 tokens. In order to assess whether our models can also effectively learn from longer contexts, we train 1B parameter models on sequences of 8192 (8k) tokens on MassiveText, and compare them to models trained on the same dataset but on sequences of length 2048 (2k) tokens. We keep the total number of training tokens the same across the models by reducing the batch size by a factor of 4 for the models trained on the sequence length of 8192 (while keeping the number of training steps fixed). As illustrated in the right plot of Figure 5, we find that Hawk-8k and Griffin-8k do achieve lower evaluation loss for sequences of length 8192 or larger, compared to Hawk-2k and Griffin-2k. This indicates that Hawk and Griffin are able to learn to use longer contexts during training. Interestingly, when evaluating at short sequence lengths, we find that Hawk-2k and Griffin-2k perform slightly better than Hawk-8k and Griffin-8k. This suggests that the training sequence length should be carefully chosen according to the intended downstream use of the model.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Gating
Gating | Sciencx (2025-01-14T16:30:10+00:00) Hawk and Griffin: Mastering Long-Context Extrapolation in AI. Retrieved from https://www.scien.cx/2025/01/14/hawk-and-griffin-mastering-long-context-extrapolation-in-ai/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.