
This content originally appeared on HackerNoon and was authored by Tech Media Bias [Research Publication]
Table of Links
Abstract and 1 Introduction 2. Data
3. Measuring Media Slant and 3.1. Text pre-processing and featurization
3.2. Classifying transcripts by TV source
3.3. Text similarity between newspapers and TV stations and 3.4. Topic model
4. Econometric Framework
4.1. Instrumental variables specification
4.2. Instrument first stage and validity
5. Results
6. Mechanisms and Heterogeneity
6.1. Local vs. national or international news content
6.2. Cable news media slant polarizes local newspapers
\ Online Appendices
A. Data Appendix
A.2. Alternative county matching of newspapers and A.3. Filtering of the article snippets
A.4. Included prime-time TV shows and A.5. Summary statistics
B. Methods Appendix, B.1. Text pre-processing and B.2. Bigrams most predictive for FNC or CNN/MSNBC
B.3. Human validation of NLP model
B.6. Topics from the newspaper-based LDA model
C. Results Appendix
C.1. First stage results and C.2. Instrument exogeneity
C.3. Placebo: Content similarity in 1995/96
C.8. Robustness: Historical circulation weights and C.9. Robustness: Relative circulation weights
C.12. Mechanisms: Language features and topics
C.13. Mechanisms: Descriptive Evidence on Demand Side
C.14. Mechanisms: Slant contagion and polarization
C.12. Mechanisms: Language features and topics
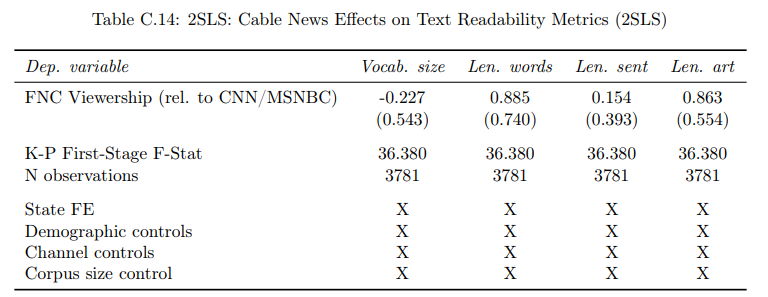
\ In Table C.14, re-run our main specification, but instead of bigram-based similarity with FNC, we regress vocabulary size (normalized by the total size of the corpus, column 1), average word length (column 2), average sentence length (column 3), and average article length (column 4) on instrumented FNC viewership relative to MSNBC and CNN. As before, we include demographic and channel controls. We also account for the size of the newspaper-specific corpus. [22] None of the coefficients are significant or close to significant. These results are consistent with the interpretation that our main results are driven by FNC-specific bigrams that diffuse into local newspaper content. [23]
\
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
[22] The number of articles scraped is given by the availability on NewsLibrary. It does not seem to follow a pattern: the correlation between corpus size and circulation by newspaper is rather small, around 0.3. The correlation between similarity with FNC and corpus size is, if anything, negative (around -0.21).
\ [23] The insignificance of the coefficients in Table C.14 should not come as a surprise given that the main results in Table 2 barely change when we move from column 2 to column 3 (where generic newspaper language controls are introduced).
:::info Authors:
(1) Philine Widmer, ETH Zürich and philine.widmer@gess.ethz.ch;
(2) Sergio Galletta, ETH Zürich and sergio.galletta@gess.ethz.ch;
(3) Elliott Ash, ETH Zürich and ashe@ethz.ch.
:::
\
This content originally appeared on HackerNoon and was authored by Tech Media Bias [Research Publication]
Tech Media Bias [Research Publication] | Sciencx (2025-02-08T02:59:13+00:00) Researching Media Slant: Language Features and Topics. Retrieved from https://www.scien.cx/2025/02/08/researching-media-slant-language-features-and-topics/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.