
This content originally appeared on HackerNoon and was authored by Load Balancer
:::info Authors:
(1) Tianyi Cui, University of Washington (cuity@cs.washington.edu);
(2) Chenxingyu Zhao, University of Washington (cxyzhao@cs.washington.edu);
(3) Wei Zhang, Microsoft (wei.zhang.gbs@gmail.com);
(4) Kaiyuan Zhang, University of Washington (kaiyuanz@cs.washington.edu).
:::
:::tip Editor's note: This is Part 3 of 6 of a study detailing attempts to optimize layer-7 load balancing. Read the rest below.
:::
Table of Links
2.2 Load balancers
3 SmartNIC-based Load Balancers and 3.1 Offloading to SmartNICs: Challenges and Opportunities
3.2 Laconic Overview
3.3 Lightweight Network Stack
3.4 Lightweight synchronization for shared data
3.5 Acceleration with Hardware Engine
4.2 End-to-end Throughput
4.3 End-to-end Latency
4.4 Evaluating the Benefits of Key Techniques
4.5 Real-world Workload
A Appendix
3 SmartNIC-based Load Balancers
Laconic is a load balancer (LB) designed for SmartNICs that effectively uses their packet-processing capabilities. Our work primarily targets L7 load balancers, but some techniques also apply to accelerating L4 load balancers as well as optimizing L7 load balancers running on traditional servers.
\ In this section, we first provide some baseline characterization experiments that empirically quantify the suitability of running a traditional load balancer on NIC cores, then provide an overview of the design of Laconic before describing in detail the core techniques used by the system.
3.1 Offloading to SmartNICs: Challenges and Opportunities
We perform characterization experiments that quantify the cost of running an unmodified load balancer on the SmartNIC and then examine the performance of hardware acceleration features on SmartNICs. We demonstrate that while SmartNICs are not a good fit for directly porting LB software written for the host, customizing the software to leverage SmartNICs’ hardware accelerators can yield significant performance gains.
\ We take a stock Nginx 1.20 load-balancer and run it on both host cores and SmartNIC cores. We use an x86 server with a Xeon Gold CPU and Mellanox ConnectX-5 NIC for the host experiments. We compared the host x86 performance to the LiquidIO3 CN3380 (with 24 ARM cores @2.2GHz) and BlueField-2 (with 8 ARM A72 cores) SmartNICs. We serve static files on the backend servers using a cache-enabled Nginx to ensure the bottleneck is on the load balancer, and we use wrk [22] to generate the workload.
\ Table 1 provides the throughput achieved by the different configurations, as we vary the number of cores on the process (i.e., x86 cores on the host and ARM cores on the
\
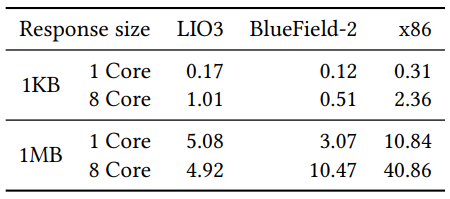
\ SmartNICs) for two different request sizes (1KB and 1MB). When we consider single-core experiments, we observe that the x86 core is about 1.8x to 3.5x more effective than the ARM cores on the SmartNIC. As we scale the number of cores on the processor, we observe a disparity between 4x and 8x. In both SmartNICs, we observe significant scalability bottlenecks; the LiquidIO3 achieves a lower line rate with eight cores than one core while performing 1MB transfers. These experiments quantify the inefficiencies of simply running an unmodified load balancer on the SmartNIC cores, which aren’t architected to run complex LB software.
\
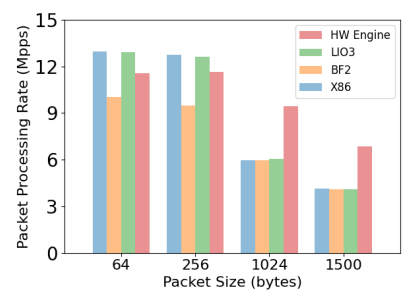
\ We perform another characterization experiment related to basic packet forwarding capability. We measure the performance of a DPDK-based packet rewriting and forwarding program on all of our three platforms (i.e., host x86 cores, LiquidIO3 ARM cores, and BlueField-2 ARM cores). This benchmark simply forwards packets after swapping the MAC address fields on received packets. We consider different packet sizes and vary the number of operating cores (or queues). Figure 2 depicts the performance of our three platforms and the hardware flow processing engine of BlueField-2. In contrast to the Nginx benchmark, we observe that the disparity in packet processing performance between the three platforms is much lower, indicating that the SmartNIC cores are better suited for packet processing than the additional general-purpose computing required by Nginx. Also, we demonstrate that the flow processing engine can operate efficiently compared with using x86 cores or ARM cores to process packets. Hardware flow processing engines can entirely offload packet processing and release the capability of the generic computing cores. But, the hardware rules have limited processing capability, and there is a rule update cost
\
\ (tens of 𝜇𝑠, more details in Section 4) to inserting and deleting rules from the flow processing engine, which limits the performance gain for processing small messages with the hardware engine. Thus, we need a hybrid design combining generic NIC cores with a hardware flow processing engine.
\ In summary, SmartNIC’s ARM cores can match x86 cores for simple packet processing but are significantly worse for executing a full-featured network stack. The SmartNIC can, however, enjoy the benefits of hardware acceleration if the packet processing can be entirely performed using the flow processing engine.
3.2 Laconic Overview
As observed above, unmodified L7 load balancers incur significant overheads when executed on the SmartNIC cores. The SmartNIC cores are significantly worse than the host cores for running a full-featured network stack that relies on the OS kernel to maintain channel state and provide reliable and sequenced delivery channels. We, therefore, develop a streamlined version of the load balancer that is explicitly tailored to the capabilities of SmartNICs.
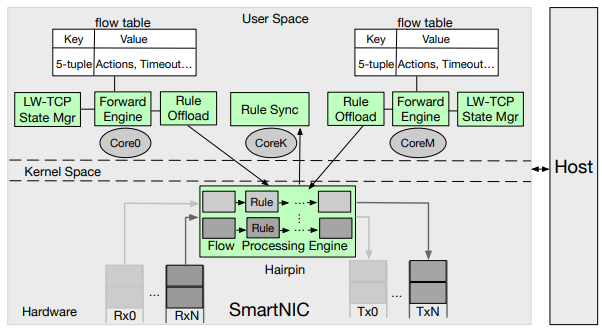
\ We identify three key techniques to effectively use SmartNICs: lightweight network stack, lightweight synchronization for shared data structures, and hardware-accelerated packet processing. The first two techniques streamline the packet-processing logic performed by the load balancers. The third technique takes advantage of hardware flow processing engines available on SmartNICs for accelerating packet processing and rewriting. Figure 3 shows how Laconic integrates the three techniques.
\ Lightweight network stack: To avoid the costs associated with the use of a full-featured network stack, we consider an alternate design that utilizes a lightweight packet forwarding stack on the LB and relies on the end-hosts themselves to achieve the desired end-to-end properties. We co-design the application layer load-balancing functions with a streamlined transport layer. Only a subset of the packets have their payloads inspected and modified by the application layer (e.g., client HTTP request packets and HTTP headers on server responses), and the LB’s transport layer is responsible for reliable delivery only for this subset. Laconic relies on the TCP stacks at the server and the client to provide reliability, sequencing, and congestion control for the remaining packets; it performs simple transformations to the packet headers, without needing access to their payloads, to transfer these responsibilities.
\ Lightweight synchronization for shared data structures: As we streamline the processing logic, the synchronization costs for concurrent access to shared data structures would limit performance. These synchronization costs are incurred when different cores on a SmartNIC handle a flow’s packets. (On-path SmartNICs eschew using RSS to spread packets across cores evenly. Even when RSS is available, say on off-path SmartNICs, the packets associated with the two different flow directions of a given client-server connection will be handled on different SmartNIC cores.) We, therefore, design highly concurrent connection table management mechanisms for load balancers. We use the semantics of the shared data and the context in which the data structures are accessed to optimize the concurrency control. For instance, some elements of the connection table are initialized during connection setup and never mutated afterward. Other elements, like the expiry timestamp for connection table entries, can benefit from relaxed update semantics.
\ Acceleration with Hardware Engine: Our design considers the flow processing engine on off-path SmartNICs as a packet-processing accelerator on which we can offload the load-balancing logic. This allows us to perform the commoncase packet rewriting logic on the hardware accelerators, thus reducing the packet processing burden on the generic ARM cores. However, these hardware accelerators cannot be used for all flows, as adding or removing match-action rules incurs moderate latency and is throughput limited. Laconic uses hardware acceleration only for sufficiently large flows. Laconic also relies on the general-purpose cores to perform packet rewriting while rules are being added and hides the latency of rule deletions with the connection establishment phases of subsequent flows.
3.3 Lightweight Network Stack
Our description focuses on two crucial functionalities of L7 load balancers, as these motivate the processing performed by the load balancer and its associated state.
\ Route HTTP requests. An L7 load balancer can be configured to route an HTTP request by parsing the fields in the HTTP header, such as the URL prefix. L7 load balancers buffer the entire HTTP header and then identify the backend using configured match rules.
\
\ Modify HTTP headers. L7 load balancers update HTTP header requests and responses by adding specific header values. For example, headers protect against XSS or CSRF attacks. Another common usage is to insert the client’s IP address into the request header or a server identifier into a response cookie to enable a consistent level of service per client.
\ Laconic’s approach to packet processing is designed to be lightweight. Laconic utilizes a simple forwarding agent that constructs only the necessary packet content to make routing decisions and only buffers modified packet content. In particular, Laconic buffers and processes packets from the client that corresponds to the HTTP requests identifies the appropriate backend servers, and ensures the reliable delivery of these (potentially modified) packets to the server. For packets sent by the server to the client, Laconic performs some simple packet rewriting using a limited amount of state. Crucially, Laconic depends on the client to keep track of which packets it has received, and it modifies ACKs from the client to inform the server about which packets need to be retransmitted. Laconic thus does not maintain any state for these packets, and it relies on client/server TCP logic for reliable end-to-end delivery and congestion control. Figure 4 shows the overall packet flow of our network stack.
\ 3.3.1 State maintained Each table entry in the connection table maintains a state machine representation of a connection. The connection state is one of the following.
\
\
\ FRONTESTABLISHED: the client has created a TCP connection with the load balancer, but a backend has not been determined; SYNSENT: The backend has been identified, but the connection hasn’t yet been fully set up; and ESTABLISHED: the connection to the backend has been set up.
\ Laconic also maintains a shallow buffer for each connection to buffer the packets received before the backend connection is established. The forwarding agent requires this buffer to construct the HTTP headers and parse information, such as the URL associated with the request.
\ At its core, the forwarding agent bridges two TCP connections and simply relays packets after appropriately rewriting the packet and ACK sequence numbers. The forwarding agent has to maintain the mapping between the sequence number spaces of the two connections. Since the load balancer can insert new header fields that will change the sequence number mappings, we maintain an array of insertion points. Each insertion point records two pieces of information: the data offset where content is inserted and the size of the inserted data. For each packet, the load balancer performs a linear scan through the array, computes the total amount of inserted data before the packet, and uses this size value as an offset to adjust the sequence and ACK numbers.
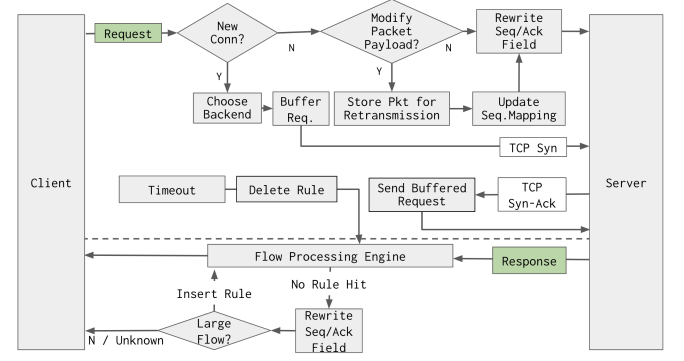
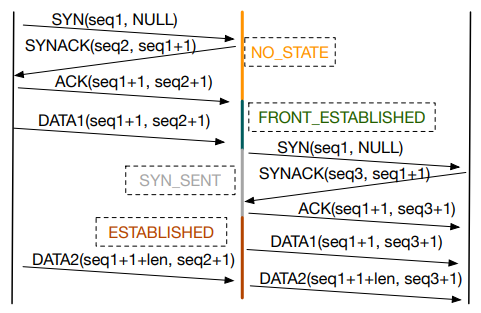
\ 3.3.2 Connection setup Figure 5 demonstrates the entire connection establishment workflow.
\ Client’s SYN received: The load balancer sends an SYNACK packet with a sequence number chosen according to the SYN cookie and the same TCP options as backend servers.
\ Client data received: Laconic buffers the packets received from the client till it can determine a backend. In particular, the load balancer will buffer client packets until it can reconstruct and parse the header fields, e.g., the hostname and the request URL. A connection table entry is created when the first client packet with payload is received.
\ Backend connection setup: After the load balancer has received sufficient client data (e.g., DATA1 in Figure 5), it can determine the backend. It then sends an SYN to the backend and completes the three-way handshake. Laconic records the sequence and ACK numbers in the connection table and then forwards the buffered client packets to the backend server, possibly after modifying any desired header. If the headers were modified, the forwarding agent holds on to the buffers until it receives the ACKs from the server; or else it releases them immediately. In the latter case, it will pass along duplicated ACKs to the client, which will then retransmit the data.
\
\
\ Relay established: From this point, the connections to the client and the backend server are established and bridged. The subsequent packets will be forwarded directly without any buffering, as we will discuss next.
\ 3.3.3 Packet processing We discuss how the forwarding agent relays packets by appropriately modifying the sequence and ACK numbers. With HTTP 1.1 [17], a persistent connection can convey multiple HTTP requests over the same TCP connection. As a result, content insertion or modification at different points of a TCP flow is required to support the modification of multiple requests.
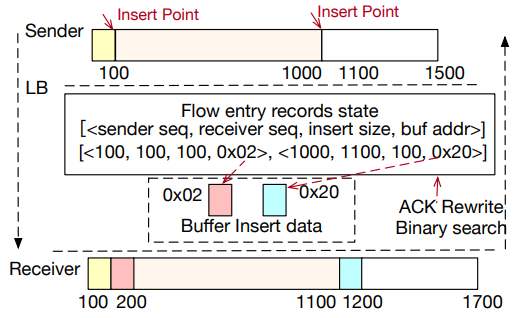
\ Figure 6 shows an example of a TCP connection handled by the load balancer. The sender sends a sequence of requests over multiple packets resulting in a flow of size 1500 bytes to the receiver. Laconic determines two locations where we need to perform content insertions. For simplicity, we designate the sequence number space starting from zero. The insertion locations are at 100B and 1000B (where "B" stands for bytes) when viewed from the sender side and at 100B and 1100B when viewed from the receiver.
\ When the load balancer performs an insert, it records the insertion point’s sequence number in the flow’s entire sequence space, as viewed by the sender and the receiver. Further, it splits the original packet at the insertion point and transmits the original packet fragments and the inserted content as separate packets.
\ Laconic appropriately rewrites the ACK numbers in the presence of multiple insertions and handles retransmissions of inserted data. There are several cases to consider. If the receiver’s ACK is far beyond the inserted location (i.e., if the ACK number is higher than 1200 +𝑀𝑇𝑈 in our example), we simply use the last offset stored in the connection table and rewrite the ACK using this offset. If the ACK is between two insertion points (i.e., it is in the range of (201 + 𝑀𝑇𝑈 , 1100) in our example), we use the offset of the previous insertion point to calculate the ACK sent to the sender. If the ACK number is exactly at an insertion point and if multiple such duplicate ACKs have been received, then the load balancer retransmits the inserted content. The last case is that the ACK number is exactly after an insertion point (e.g., 201 or 1201 in our example), in which case we suppress the ACK instead of relaying it and triggering duplicate ACK processing on the sender. In the case of packets containing SACKs (selective acknowledgments), Laconic performs the ACK number transformations on every SACK block.
\ ACK packets are also used as the signal to garbage collect all the buffers buffered at the load balancer. The load balancer will check the ACKs against the stored buffers and release those that have been ACKed.
\ Note that the ACK number transformations ensure that the sender can use duplicate ACKs to detect and retransmit lost packets. The forwarding agent is responsible for the reliable delivery of only the inserted content, with the sender responsible for the reliability of all other content.
3.4 Lightweight synchronization for shared data
We now present the design of efficient synchronization for the load balancer’s data structures, e.g., the connection table. Ideally, we would employ a scheme such as receive-side scaling (RSS), which would allow each NIC core to have exclusive and lock-free access to its shard and avoid sharing data structures across NIC cores. This is hard in the context of both L4 and L7 LBs, as the connection table state would be accessed by traffic from both directions, and RSS would inevitably map the forward and reverse directions to different cores. Thus, Laconic’s connection table needs to provide good scalability with concurrent accesses of per-flow states from multiple NIC cores.
\ The load balancer records the states of each flow in a connection table, which is used to select a backend server and update the IP and port attributes in a packet header. At a high level, the flow state recorded by Laconic in the connection table could be categorized into three kinds:
\ • Decision of the backend server assignment.
\ • Timeout information of connection.
\ • TCP state and seq/ack number mapping.
\ For each category of state, Laconic uses different strategies in the design of the connection table to accommodate its access pattern.
\ Backend Assignment: Once the backend is chosen for a specific client connection, the assignment will stick to the connection through its lifetime, meaning that the vast majority of accesses to this state would be read-only. Therefore, Laconic chooses to design its connection table based on Cuckoo hashing [33], which provides predictable and constant-time lookups. Cuckoo hashing achieves this property by limiting an entry’s position to two hashed locations within the table, but it might have to periodically shuffle the entries to accommodate new insertions. We now discuss how we can eliminate the use of locks during the lookup and still achieve correctness. For read operations, Laconic uses a version-counter-based approach to prevent the lookup operations from reading concurrent write operations: before and after Laconic reads the hash table slot with a matching key, a version counter is read from the table entry. A mismatched version number indicates that a concurrent write has been performed on the entry, in which case Laconic will retry the read operation. With this approach, no lock is held during a lookup operation to the connection table. To further improve concurrency, Laconic’s connection table adopts the optimistic locking scheme in [33] to reduce the critical section during entry shuffles triggered by inserts and minimize the amount of time a write operation needs to hold locks.
\ Flow Timeout: Tracking the last access time of each flow is important for Laconic to correctly time out and remove entries of old flows and reclaim its resources. However, recording the access time for the per-flow state could impact scalability. This is because the entry needs to be updated for every access, effectively making every single access a concurrent update, typically performed while holding a lock. To mitigate the potential inefficiencies caused by such implicit writes, Laconic uses a “blind write” to update the timestamp during the lookup operation. If a later version number check reveals that the record has been updated and is now storing state for a different flow, Laconic will not attempt to revert the update and simply retries the timestamp update. With this approach, Laconic could spuriously update the TTL of a different record, thereby delaying its garbage collection, but it also ensures that a received packet would always bump up the corresponding flow’s TTL.
\ TCP state and seq/ack number mapping: For L7 load balancing, Laconic needs to maintain the TCP state (LISTEN, SYN-SENT, ESTABLISHED, etc.) and the mapping of seq/ack number between the client side and server side. However, with the help of RSS, state transitions of the TCP state machine of a single connection will always be performed on the same NIC core. Therefore, Laconic updates the state machine without acquiring any locks. We observe that the access of the seq/ack number mapping follows a consumer/producer pattern, so we use lock-free mechanisms for appending to and reading from this list.
3.5 Acceleration with Hardware Engine
3.5.1 Capabilities of Flow Processing Engine On offpath SmartNICs, the hardware flow processing engine can significantly accelerate packet processing. Conceptually, it works similarly as a switch with the Reconfigurable MatchAction Table (RMT) architecture. Multiple match-action tables can exist in the hardware, and match-action rules for various packet fields of a packet can be inserted dynamically. We now describe how Laconic can take advantage of these capabilities. We describe two key constructs available in flow processing engines that together aid in offloading packet-processing logic.
\ On-NIC rules: For NICs equipped with the flow processing engine, DPDK provides a RTE_FLOW interface to insert and delete rules into the NIC. These rules have two fields: a match field and an action field.
\ For the match field, the application can specify fields from packet headers to match against, such as IP/MAC address and TCP/UDP port numbers. This allows the application to match packets with specific values for those fields.
\ For the action field, applications can specify two types. The first type is fate actions, which determines the packet’s final destination, such as dropping it or moving it to a different queue. The second type includes non-fate actions such as packet counting and rewriting headers, including TCP port, IP address, and sequence numbers. Header updates can change a specific field or add a predetermined constant value. The flow processing engine can also set an expiry time for a rule and notify the application if no packet matches the rule after a certain time.
\ Hairpin queue: Hairpin queue is a feature first introduced in DPDK 19.11 [12]. It is similar to a loopback interface, but it operates on the network-facing ports of the NIC. The hairpin queues are a pair of connected RX and TX queues.
\ Benefits: With a combination of on-NIC rules and hairpin queues, we can dramatically reduce the involvement of general-purpose cores in the load-balancing datapath. Specifically, if we were to insert rules to match packets with known flows, specify the appropriate actions to rewrite the packet contents (e.g., the sequence number and ACK number fields), and send it out through a hairpin queue, then most of the packet-processing logic of our network stack can be offloaded to the NIC flow processing engine. Furthermore, latency can be improved since all the forwarding data path is inside the NIC pipeline and bypass computing cores.
\ Challenges: However, there are two types of challenges for utilizing the flow processing engine.
\ The first type is a functional challenge: current SmartNICs do not support a range match operation, which would be useful in the context of Laconic for matching a range of sequence numbers. And the match-action rule can not be performed on the selective acknowledgment (SACK) blocks in the case where a receiver is signaling holes in the received sequence number space.
\ The second type is a performance-related challenge: rule insertions and deletions can both be expensive in terms of latency. On the BlueField-2, the cost of a non-blocking rule insertion with batching is 25 microseconds in our tests, whereas the cost of a blocking rule insertion is substantially higher at 305 microseconds. These measurements indicate that rule updates should be performed sparingly, especially in the context of short flows, and that rule insertion costs should be overlapped with other tasks, through the use of non-blocking rule insertions.
\ 3.5.2 Using Flow Processing Engine We now describe how Laconic uses the flow processing engines.
\ What functionalities to offload? We first note that the flow processing engines do not have advanced parsing capabilities. Therefore, request processing logic that operates on content sent from the client to the server (e.g., parsing HTTP headers, requests, etc.) is not offloaded but rather performed on a SmartNIC ARM core.
\

\ Finally, for these offloaded flows, packet rewriting is performed only on packets sent from the server to the client; packets sent from the client to the server, which is a small portion of the traffic load, are handled on the SmartNIC ARM cores. We made this choice based on the limitation that Bluefield-2 cannot rewrite the SACK option in TCP headers. We also observed by experiment that disabling SACK incurs a dramatic loss in TCP flow performance.
\ When to offload? We now describe the life cycle of flow rules from insertion to deletion. Once a server response exceeds the size threshold, a general-purpose core inserts a rule to match and modify packets sent from the server to the client. This rule matches the TCP 5-tuple corresponding to the server-to-load balancer connection, with the action of updating the sequence and ACK numbers associated with the packet using the correct offsets. This rule insertion is performed using a non-blocking operation so as to reduce the overhead associated with performing the operation. Due to the non-blocking operation, subsequent packets from the server could still be sent to a generic ARM core if the insertion hasn’t been completed, but correctness is ensured as both the ARM core and the flow processing engine are performing the same operation.
\ To delete the rules, the SmartNIC cores continuously check the client ACKs as to whether the entire server response has been received or not. ACK packets from clients are continued to be handled by ARM cores instead of the flow processing engines. If the entire response has been received, then the SmartNIC core initiates the process of removing the packet update rule in preparation for having a clean connection for the next client request. The rule deletion operations are first conveyed to a dedicated core, which batches outstanding rule deletions and then performs them synchronously. By delegating this to a dedicated thread and batching such operations, we reduce the overhead of blocking rule updates. Finally, when the next client request is received, the receiving core first checks (and possibly waits) for the condition that the prior rule associated with the connection has been removed before processing the client request.
\ Achieve RSS with the engine: We implement a custom RSS using the engine, which greatly simplified the need for handling concurrent access to shared data structures from different cores. Traditional RSS that operates on a flow’s 5-tuple is insufficient as the client to LB, and the server to LB segments correspond to different 5-tuples, and RSS would steer the packets received from the two directions into two different cores. Thus in Section 3.4, we propose lightweight synchronization for shared data. We can eliminate the synchronization mechanisms if packets from a given client-server connection are processed by the same core in either direction of the packet flow.
\ Specifically, we pre-install a set of rules to steer incoming packets to cores solely based on the port numbers in the TCP header. We partition the port number space into multiple shards and assign each shard to a processing core. We insert a rule into the flow processing engine for each allocated TCP port number so that client packets with the source port number and server packets with the destination port number are sent to the assigned core. This ensures that packets from the same client-server connection are always processed by the same core. By doing so, we can eliminate the need for synchronization in accessing the flow table, and each core can have its own shard of the connection table. Note that this method is only needed for short flows whose packet processing is not offloaded to the engine, which also helps avoid load imbalance issues that may occur when processing large elephant flows using the same NIC core.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\
This content originally appeared on HackerNoon and was authored by Load Balancer
Load Balancer | Sciencx (2025-02-14T16:39:39+00:00) This Tiny Chip Can Handle Internet Traffic Faster—If You Let It Do Things Its Own Way. Retrieved from https://www.scien.cx/2025/02/14/this-tiny-chip-can-handle-internet-traffic-faster-if-you-let-it-do-things-its-own-way/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.