
This content originally appeared on DEV Community and was authored by Tamerlan Gudabayev
Table of Contents
- Introduction to Hashing
- What is a hash table?
- Time Complexity
- Strengths and Weaknesses
- Applications
- Simple Implementation
- Conclusion
- Additional References
Introduction to Hashing
Imagine that we went back in time into the time right before the smartphone boom, and you were assigned a task to implement the contact list feature. How would you do it?
Let's forget the UI-UX aspect of the problem, and focus on the core problem. We have to map a name to a phone number. If we break this down further, we need a data structure that helps us map key-value pairs to each other.
Fortunately, smart computer scientists before us already made a data structure for this use case and it's called the hash table.
PS. This data structure is also called a hash map, it's almost the same thing.
What is a hash table?
A hash-table is a data structure that maps keys to values.
"But, TAMER, what are keys and values?"
Glad you asked.
- Key - a unique integer that we can use to index the value
- Value - value associated with the key

For example, let's us imagine we have a bunch of contacts, if we structure them in a hash table it will look something like this:
// Representation of a hash table
contacts = {
'Mike':'+ 1 222 333 xxxx',
'John':'+ 1 222 333 xxxx',
'Ann':'+ 1 222 333 xxxx',
'Luke':'+ 1 222 333 xxxx',
'George':'+ 1 222 333 xxxx',
'Liza':'+ 1 222 333 xxxx',
}
// To get a phone number
mikes_phone_number = contacts['Mike']
You may have questions such as:
"Isn't the key supposed to be an integer?"
Your right, so let's see how this works under the hood.
Gritty Details
A hash table is essentially an array, but the keys are converted into a unique integer index.
Take a look at this visualized example.
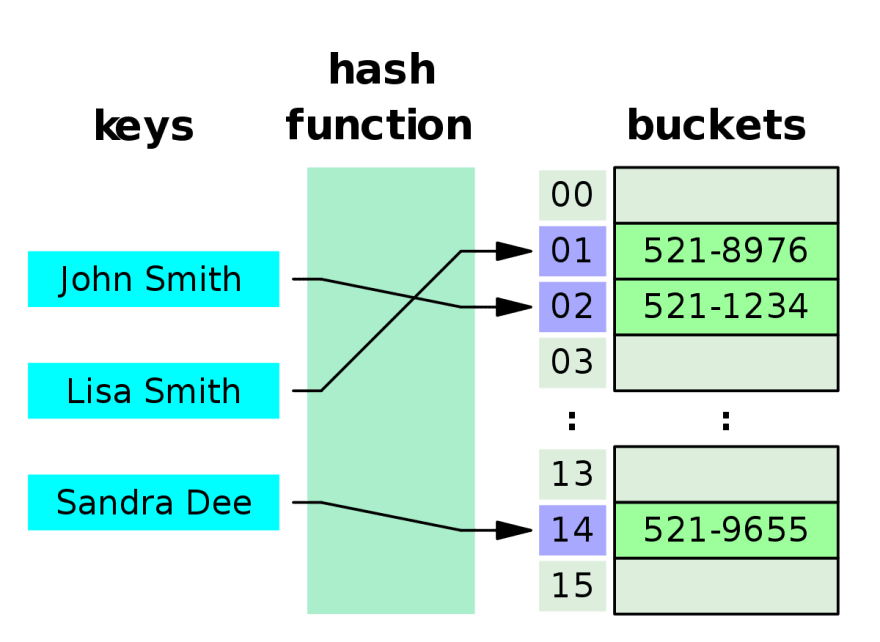
Our key "John Smith" changed into index 1, which we can use to index the array. As you can see it goes through the hash function.
What is a hash function?
At its core, a hash function is used to translate a key to a unique integer index. A simple hash function may look like this:
public function hashString(key){
sum = convert_string_to_number(key) // sum of all ascii characters
return sum % array.length
}
There are tons of different hashing functions, some good, some bad.
Good hashing functions, usually have the following properties:
- Easy to compute: it does not have to be some complicated algorithm.
- Uniform distribution: it should uniformly distribute the indexes, there shouldn't be too much clustering.
- Less collisions: collisions occur when two keys have the same hashed index, the hash function should try to avoid this as much as possible.
Even with a good hashing function, collisions are bound to occur. To combat that, we have certain methods on dealing with collisions.
Handling Collisions
The two main ways of handling collisions are:
- Chaining
- Open Addressing
Let's quickly go over each one.
Chaining
Chaining is one of the most commonly used collision resolution techniques. Basically, each element of the hash table is a linked list. To store an element in a hash table, you must store it in a specific linked list. If there are any collisions, then you simply store the elements in the same linked list.
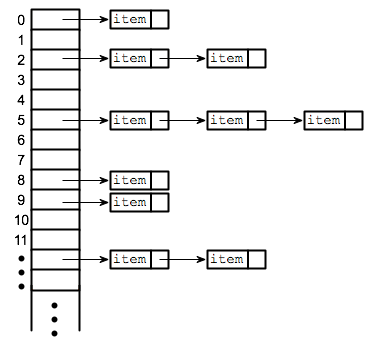
Let's go over the pros and cons of this approach.
Pros
- Simple to implement
- Hash table never fills up, we can always add more elements to the chain
- Less sensitive to the hash function or load factors
- It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted
Cons
- The cache performance of chaining is not good as keys are stored using a linked list. Open addressing provides better cache performance as everything is stored in the same table
- Wastage of Space (Some Parts of the hash table are never used)
- If the chain becomes long, then search time can become O(n) in the worst case
- Uses extra space for links
Open Addressing
Unlike chaining, all elements in a hash table are stored directly on it. When a new entry is being inserted, an index will be generated, and if it's unoccupied only then the entry record is inserted. If the index is occupied, then it will regenerate the index in some probe sequence until it finds an unoccupied slot.
There are three main probe sequences:
- Linear Probing
- Quadratic Probing
- Double Hashing
Let's take a deeper look at each
Linear Probing
Linear probing is when the interval between successive probes is fixed (usually to 1).
index = index % hashTableSize
index = (index + 1) % hashTableSize
index = (index + 2) % hashTableSize
index = (index + 3) % hashTableSize
Linear probing is simple, but it has its flaws:
- Primary Clustering: many consecutive elements form groups and it starts taking time to find a free slot or to search for an element.
- Secondary Clustering: Secondary clustering is less severe, two records only have the same collision chain (Probe Sequence) if their initial position is the same
Quadratic Probing
Quadratic probing is similar to linear probing but instead of a fixed interval, we take the squared interval.
index = index % hashTableSize
index = (index + pow(1, 2)) % hashTableSize // 1^2
index = (index + pow(2, 2)) % hashTableSize // 2^2
index = (index + pow(3, 2)) % hashTableSize // 3^2
Double Hashing
Double hashing is similar to linear probing and the only difference is the interval between successive probes. Here, the interval between probes is computed by using two hash functions.
index = (index + 1 * indexH) % hashTableSize;
index = (index + 2 * indexH) % hashTableSize;
Now that we have covered the different methods of implementing open addressing, let's look its pros and cons.
Pros
- Open addressing is used when the frequency and number of keys are known.
- Open addressing provides better cache performance as everything is stored in the same table.
- In Open addressing, a slot can be used even if an input doesn’t map to it.
- No links in Open addressing, thus saving space.
Cons
- Open Addressing requires more computation.
- In open addressing, table may become full.
- Open addressing requires extra care to avoid clustering and load factor.
Time Complexity
Let's look at the average case for hash tables.
- Space — O(n)
- Insertion — O(1)
- Search — O(1)
- Deletion — O(1)
PS. Keep in mind that all of these in worst case can be O(n).
Strengths and Weaknesses
Now that we have covered all the gritty details of hash tables, let's go over their strengths and weaknesses.
Strengths
- Fast searches. Search take O(1) time on average.
- Flexible keys. Most data types can be used for keys, as long as they're hashable.
Weaknesses
- Slow worst-case searches. Search take O(n) time in the worst case.
- Unordered. Keys aren't stored in a special order. If you're looking for the smallest key, the largest key, or all the keys in a range, you'll need to look through every key to find it.
- Single-directional searches. While you can search the value for a given key in O(1) time, searching the keys for a given value requires looping through the whole dataset—O(n) time.
- Not cache-friendly. Many hash table implementations use linked lists, which don't put data next to each other in memory.
Applications
- Associative arrays: Hash tables are commonly used to implement many types of in-memory tables. They are used to implement associative arrays (arrays whose indices are arbitrary strings or other complicated objects).
- Database indexing: Hash tables may also be used as disk-based data structures and database indices (such as in dbm).
- Caches: Hash tables can be used to implement caches i.e. auxiliary data tables that are used to speed up the access to data, which is primarily stored in slower media.
- Object representation: Several dynamic languages, such as Perl, Python, JavaScript, and Ruby use hash tables to implement objects.
- Hash Functions are used in various algorithms to make their computing faster
Simple Implementation
We are gonna implement a simple hash table using JavaScript.
class HashTable {
constructor() {
this.values = {};
this.length = 0;
this.size = 0;
}
calculateHash(key) {
return key.toString().length % this.size;
}
add(key, value) {
const hash = this.calculateHash(key);
If (!this.values.hasOwnProperty(hash)) {
this.values[hash] = {};
}
if (!this.values[hash].hasOwnProperty(key)) {
this.length++;
}
this.values[hash][key] = value;
}
search(key) {
const hash = this.calculateHash(key);
if (this.values.hasOwnProperty(hash) && this.values[hash].hasOwnProperty(key)) {
return this.values[hash][key];
} else {
return null;
}
}
}
//create object of type hash table
const ht = new HashTable();
//add data to the hash table ht
ht.add("Canada", "300");
ht.add("Germany", "100");
ht.add("Italy", "50");
//search
console.log(ht.search("Italy"));
PS. You would almost never have to implement your own hash tables, in JavaScript, objects are essentially hash tables. Java and many other languages have their own internal implementation that you can directly use.
Conclusion
Hash tables are by far one of the most commonly used data structures, they are also used in lots of coding interview problems. So by the end of this post, I hope you learned the beauty of hash tables and it's gritty details. If you got any questions, feel free to leave them down below in the comments.
Additional References
To learn more about hashes I recommend these resources:
- https://www.hackerearth.com/practice/data-structures/hash-tables/basics-of-hash-tables/tutorial/
- https://www.programiz.com/dsa/hash-table
- https://www.freecodecamp.org/news/what-is-hashing/
This content originally appeared on DEV Community and was authored by Tamerlan Gudabayev
Tamerlan Gudabayev | Sciencx (2021-05-09T09:10:20+00:00) Data Structures: Hash Tables. Retrieved from https://www.scien.cx/2021/05/09/data-structures-hash-tables/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.