
This content originally appeared on DEV Community and was authored by Sebastian Aigner
This blog post accompanies a video from our YouTube series which you can find on our Kotlin YouTube channel, or watch here directly!
Today, we are learning about advanced functions that we can use to work with and manipulate all kinds of Kotlin collections!
Checking predicates: any, none and all
Let’s warm up by having a look at a selection of functions that allow us to check conditions for our collection elements.
They’re called any, none, and all. Each of them takes a predicate – so a function that returns true or false – and checks whether the collection fits this predicate.
Let’s say we have a group of friends (which is really just a List<Person>, each featuring a name, age, and maybe a driversLicense):
data class Person(val name: String, val age: Int, val driversLicense: Boolean = false)
val friendGroup = listOf(
Person("Jo", 19),
Person("Mic", 15),
Person("Hay", 33, true),
Person("Cal", 25)
)
When we want to check if the group can travel by car, we want to check if any of them have a driver's license – so we use the any function. It returns true if there is at least one element in our collection for which the predicate returns true.
val groupCanTravel = friendGroup.any { it.driversLicense }
// true
As another example, let’s say we want to check if this group of friends is allowed to enter a club – for this, we would need to make sure that none of the folks in the group are underage!
Here, we can use the none function, which only returns true when there is not a single element in our collection that holds true for our predicate:
val groupGetsInClub = friendGroup.none { it.age < 18 }
// false
The third function in the bunch is the all function. At this point, you can probably spot the pattern – all returns true, if each and every element in our collection matches our predicate. We could use it to check whether all names in our friend group are short:
val groupHasShortNames = friendGroup.all { it.name.length < 4 }
// true
Predicates for empty collections
While on the topic, let's have a little brain teaser: How do any, none, and all behave for empty collections?
val nobody = emptyList<Person>()
// what happens here?
Let’s look at any first. There is no element that can satisfy the predicate, so it returns false:
nobody.any { it.driversLicense }
// false
The same goes for none – there is no function that can violate our predicate, so it returns true:
nobody.none { it.age < 18 }
// true
The all function, however, returns true with an empty collection. This may surprise you in the first moment:
nobody.all { it.name.count() < 4 }
But this is quite intentional and sound: You can't name an element that violates the predicate. Therefore, the predicate has to be true for all elements in the collection – even if there are none!
This might feel a bit mind-bending to think about at first, but you’ll find that this concept, which is called the vacuous truth, actually plays very well with checking conditions, and expressing logic in program code.
Collection parts: chunked and windowed
With our brain freshly teased, let’s move on to the next topic, and learn about how to break collections into parts!
The chunked function
If we have a collection that just contains a bunch of items, we can cut up the list into individual chunks of a certain size by using the chunked function. What we get back is a list of lists, where each element is a _chunk _of our original list:
val objects = listOf("?", "?", "?", "?", "⚙️", "?", "?")
println(objects.chunked(3))
// [[?, ?, ?], [?, ⚙️, ?], [?]]
In the example above, we break our list of random objects (represented with emojis) apart, using a chunk size of 3.
The first element in our result is in itself a list which contains our first three objects –
[?, ?, ?].The second element is once again a chunk, and contains the three elements that follow after that –
[?, ⚙️, ?].The last element is also a chunk – but since we ran out of elements to fill it with three items, it only contains the book stack -
[?].
In typical standard library fashion, the chunked function also provides a little bit of extra power. To immediately transform the chunks we just created, we can apply a transformation function. For example, we can reverse the order of elements in the resulting lists, without having to do another map call separately:
println(objects.chunked(3) { it.reversed() })
// [[?, ?, ?], [?, ⚙️, ?], [?]]
To summarize: the chunked function cuts our original collection into lists of lists, where each list has the specified size.
The windowed function
Closely related is the windowed function. It also returns a list of lists from our collection. Instead of cutting it up into pieces, however, this function generates a “sliding window” of our collection:
println(objects.windowed(3))
// [[?, ?, ?], [?, ?, ?], [?, ?, ⚙️], [?, ⚙️, ?], [⚙️, ?, ?]]
- The first window is once again the first three elements –
[?, ?, ?]. - The next window is
[?, ?, ?]– we simply “moved” our window of size 3 over by one, which includes some overlap.
The windowed function can also be customized. We can change both window and step size, the latter being the number of elements that the window should “slide along” for each step:
println(objects.windowed(4, 2, partialWindows = true))
// [[?, ?, ?, ?], [?, ?, ⚙️, ?], [⚙️, ?, ?], [?]]
As you can see in the example above, we can also control whether our result should contain partial windows. This changes the behavior when we’ve reached the end of our input collection, and we’re running out of elements.
With partial windows enabled, we just keep sliding, and we get the last elements trickling in, in the form of smaller windows, until we get a window which once again only contains the last element from our input collection – [⚙️, ?, ?], [?].
windowed also allows us to perform an additional transformation at the end, which can modify the individual windows directly:
println(objects.windowed(4, 2, true) {
it.reversed()
})
// [[?, ?, ?, ?], [?, ⚙️, ?, ?], [?, ?, ⚙️], [?]]
Un-nesting Collections: Flatten and Flatmap
The chunked and windowed functions, along with some others all return nested collections – lists of lists. What if we want to un-nest these, turning them back into flat lists of elements? As usual, we do not need to fear, because the standard library has got us covered.
We can call the flatten function on a collection of collections. As you may suspect, the result is a single list of all the elements that were originally contained inside of our nested collections:
val objects = listOf("?", "?", "?", "?", "⚙️", "?", "?")
objects.windowed(4, 2, true) {
it.reversed()
}.flatten()
// [?, ?, ?, ?, ?, ⚙️, ?, ?, ?, ?, ⚙️, ?]
This is also a good point to talk about the flatMap function. flatMap is like a combination of first using map, and then using flatten – It takes a lambda which generates a collection from each of the elements in our input collection:
val lettersInNames = listOf("Lou", "Mel", "Cyn").flatMap {
it.toList()
}
println(lettersInNames)
// [L, o, u, M, e, l, C, y, n]
In the example above, the function that we provide creates a list for each element in our input collection, containing the letters of the original string. Next, that collection of collections gets flattened. As desired, we end up with a plain list of elements – the list of characters from the names of the original collection.
If you are doing an operation on a list, which in turn generates a collection for each one of the input elements, consider if flatMap can help you simplify your code!
Combining collections: zip and unzip
So far, we have always looked at a single collection, and what we can do with it. Let's learn about a way to combine two collections, and create a new one from them – it's time to zip!
The zip function
Assume we have two collections, where the elements at each index are somehow related. For example, this could be a list of cities in Germany, and we have another list of German license plates that correspond to those cities:
val germanCities = listOf(
"Aachen",
"Bielefeld",
"München"
)
val germanLicensePlates = listOf(
"AC",
"BI",
"M"
)
println(germanCities.zip(germanLicensePlates))
// [(Aachen, AC), (Bielefeld, BI), (München, M)]
As you can see, by zipping these two collections, we get a list of pairs, where each pair contains the elements with the same index from the original two collections.
Metaphorically, this is similar to a zipper on a jacket, where the teeth match up one by one. We zip together the elements of our collection, and we get pairs of each city and its corresponding license plate.
For an extra bit of flair, we can also call the zip function using infix notation:
println(germanCities zip germanLicensePlates)
// [(Aachen, AC), (Bielefeld, BI), (München, M)]
zip can also take a transformation function. We can pass a lambda that receives the values of the individual zipped pairs, and we can apply a transformation:
println(germanCities.zip(germanLicensePlates) { city, plate ->
city.uppercase() to plate.lowercase()
})
// [(AACHEN, ac), (BIELEFELD, bi), (MÜNCHEN, m)]
The unzip function
The standard library also contains the inverse function, called unzip, which takes a list of pairs, and splits them back into a pair of two separate lists:
val citiesToPlates = germanCities.zip(germanLicensePlates) { city, plate ->
city.uppercase() to plate.lowercase()
}
val (cities, plates) = citiesToPlates.unzip()
println(cities)
// [AACHEN, BIELEFELD, MÜNCHEN]
println(plates)
// [ac, bi, m]
The example above uses a destructuring declaration to easily access both of them.
The zipWithNext function
In a way, zipWithNext is really a specialized case of the windowed function we got to know today: Instead instead of zipping together two separate lists element by element, this function takes one collection, and zips each of its items with the one that follows it:
val random = listOf(3, 1, 4, 1, 5, 9, 2, 6, 5, 4)
println(random.zipWithNext())
// [(3, 1), (1, 4), (4, 1), (1, 5), (5, 9), (9, 2), (2, 6), (6, 5), (5, 4)]
In the example above, we're zipping together a list of numbers. If we want to check the “change” – how much the value increments or decrements each step – we can express this quite elegantly using zipWithNext. We provide a lambda that receives a pair of one number and the one that follows immediately after:
val random = listOf(3, 1, 4, 1, 5, 9, 2, 6, 5, 4)
val changes = random.zipWithNext { a, b -> b - a }
println(changes)
// [-2, 3, -3, 4, 4, -7, 4, -1, -1]
Custom aggregations: reduce and fold
We have finally arrived at the grand finale for this post – functions that help us build custom aggregations.
The reduce function
Let’s set the scene with a small callback – in the previous post, we learned about functions like sum, average, count, and functions to receive the minimum and maximum elements inside a collection. All of these reduce our collection to a single value.
It's possible that we find ourselves in a situation where there’s no out-of-the-box function for how we want to generate a single value for our collection. For example, we may want to multiply all numbers in a list, instead of summing them.
In this case, we can rely on the reduce function as a more generic version for aggregating a collection:
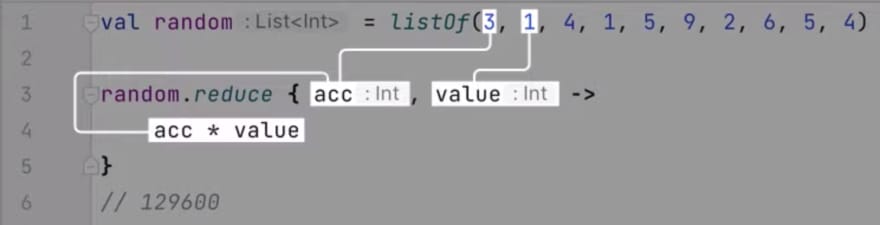
val random = listOf(3, 1, 4, 1, 5, 9, 2, 6, 5, 4)
val multiplicativeAggregate = random.reduce { acc, value -> acc * value }
println(multiplicativeAggregate)
// 129600
As seen in the example above, we call the reduce function with a lambda block which receives two parameters:
- An accumulator, which has the same type as our collection, and
- An individual item from our collection.
The task of the lambda function is to return a new accumulator. Each invocation, one after the other, receives not only the current element, but also the result of the previous calculation, inside the accumulator.
- The function starts with the first element of our collection in the accumulator.
- Then it runs our operation – in this example, we multiply the accumulator (which right now is the first number) with the current element (which is the second number).
- We’ve calculated a new value, which will be stored in the accumulator, and used when our function is called once more with the third element
This cycle repeats, and we continue to gradually build up the final result in our accumulator. One might even say we’re accumulating that result!
Once we’ve gone through all the elements in our collection, reduce returns the final value that’s inside the accumulator.
As you can see, with reduce, we can hide a lot of mechanics for aggregating our collection behind one function call, and stay true to Kotlin’s concise nature.
The fold function
But we can actually go beyond this, and can take this versatility one step further – with the fold operation. Remember – when we used reduce, the iteration starts with the first element of our input collection in the accumulator.
With the fold function, we get to specify our own accumulator – and in fact, it can even have a different type than the items in our input collection! As an example, we can take a list of words, and multiply the number of their characters together using fold:
val fruits = listOf("apple", "cherry", "banana", "orange")
val multiplied = fruits.fold(1) { acc, value ->
acc * value.length
}
println(multiplied) // 1080
The underlying mechanism is the same – the lambda passed to the fold function gets called with an accumulator and a value, and calculates a new accumulator. The difference is that we specify the initial value of the accumulator ourselves.
(Note that we pass 1 as an initial value for our accumulator, and not 0. That’s because for multiplication, 1 is the neutral element)
Both fold and reduce come in a number of other flavors, as well:
– the sibling functions reduceRight and foldRight change the order of iteration
-
reduceOrNullallows you to work with empty collections without throwing exceptions. -
runningFoldandrunningReducedon’t just return a single value representing the final state of the accumulator, but instead return a list of all the intermediate accumulator values as well.
That's it!
This concludes my overview of some advanced collection operations in Kotlin – I hope you found this post useful, and have learned something new!
Maybe you can find a point in your code where a predicate, some zipping, chunking or windowing could come in handy! Or maybe you want to explore by defining your own aggregations functions based on the reduce or fold functions.
To get reminded when new Kotlin content is released, follow us here on dev.to/kotlin, and make sure to follow me on Twitter @sebi_io.
Also, use this opportunity sure to find the subscribe button and notification bell on our YouTube channel!
Take care!
This content originally appeared on DEV Community and was authored by Sebastian Aigner
Sebastian Aigner | Sciencx (2021-06-14T17:49:10+00:00) Advanced Kotlin Collection Functionality. Retrieved from https://www.scien.cx/2021/06/14/advanced-kotlin-collection-functionality/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.