
This content originally appeared on Level Up Coding - Medium and was authored by Aritra Das

Cache is almost inevitable when you're building APIs for a system that requires high throughput with minimum response times. Every developer who works on Distributed Systems has had used some caching mechanism at some point. In this article, we will look at a design where you use a CDN to build a read-through cache, that not only optimizes your APIs but reduces your infrastructure cost as well.
Having some idea about cache and CDN would be helpful to understand this article. If you’re completely unware, I request you to read just a bit, and then come back here.
A bit of Background
At the time of writing this article, I work with Glance which is the world’s largest lock screen-based content discovery platform, and we have around 140 Million active users at this point. So you can imagine the scale at which our services have to run, and at this scale, even the simplest thing becomes super complex. And as backend developers, we are always striving to build highly optimized APIs to provide a good experience to our users. The story starts from here, how we faced a certain problem and then went about solving it. I hope you will be able to learn a thing or two about System Design at scale after reading this article.
Problem
We had to develop a couple of APIs that had the following characteristics
- The data was not going to change very often.
- The response is the same for all users, with no unexpected query params, simple straight GET APIs.
- The response data volume was ~600 Kb at max.
- We expected a very high throughput (around 50k — 60k queries/second eventually) from the APIs.
So what comes to your mind when you see this problem first? Well for me it was, just throw in an in-memory cache ( google guava may be )on the nodes (since the data volume is low), use Kafka to send invalidation messages (cause I love Kafka ? and it’s reliable), set up autoscaling for the service instances (because the traffic was not uniform throughout the day). Something in the line of like this diagram
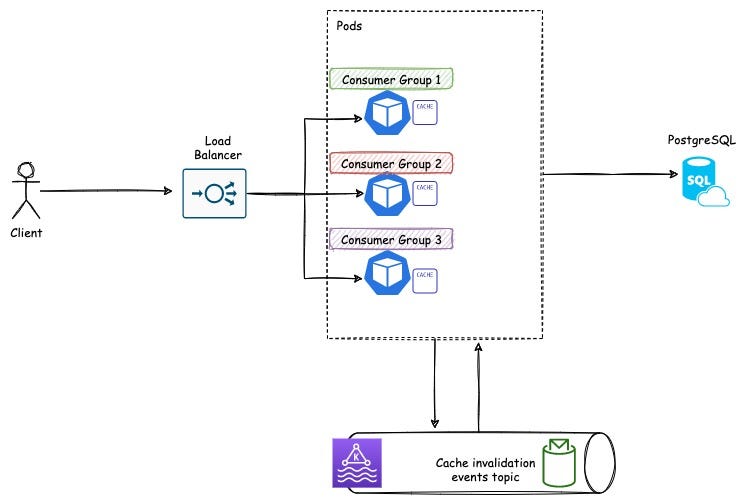
Bam! Problem solved! easy right? Well, not really, like any other design, this one also came with some flaws. For example, the design is a tiny bit complex for a simple use case, the infrastructure cost is going to go up since now we have to spawn a Kafka + Zookeeper cluster, plus to handle 50k requests/second we need to horizontally scale our service instances (Kubernetes pods for us) a lot, which translates to increased no of bare metal nodes or VMs.
Hence we looked for a simpler and cost-effective approach, and that is how we ended up developing a solution with “Read through cache using CDN”. I will discuss the details of the architecture and also the tradeoff in a while.
But before going any further let’s understand the building blocks of the design.
Read Through Cache
The standard cache update strategies are such
- Cache aside
- Read-through
- Write-through
- Write back
- Refresh ahead
I will not go into details of the other strategies and will focus on read-through only since this article is about that only. Let’s dig a bit further and understand how it works.
user1 -> just a imaginary piece of data that your’e trying to fetch
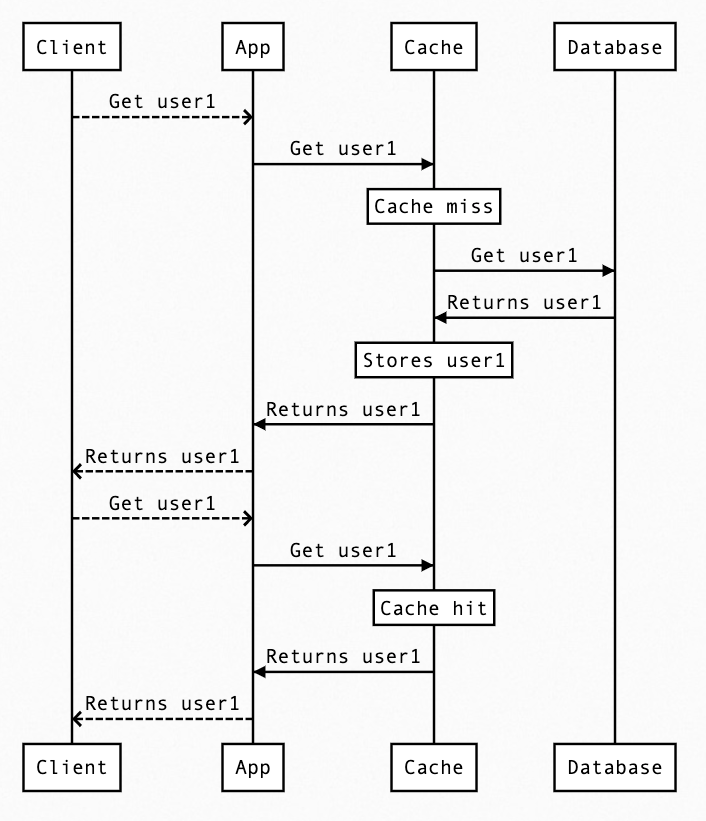
The diagram is self-explanatory, but just to summarize
- The App never interacts with DB directly but always via Cache.
- On a cache miss, the cache will read from DB and enrich the cache storage.
- On a cache hit, data is served from the cache.
You can see, the DB is reached very infrequently and the response is fast since the caches are mostly in-memory (Redis/ Memcached). A lot of problems solved already ?
CDN
The definition of CDN on the internet is “A content delivery network (CDN) is a globally distributed network of proxy servers, serving content from locations closer to the user, and is used to serve static files such as images, videos, HTML, CSS files”. But we are going to go against the stream and serve dynamic content (JSON response, not JSON file) using CDN.
Also, there are generally two kinds of CDNs conceptually
- Push CDN: You are responsible to upload data to the CDN servers
- Pull CDN: The CDN will pull data from your servers (origin servers)
We are going to use Pull CDN since with the push approach I have to take care of retry, idempotency, and other stuff, which is an additional headache for me and doesn’t really add any value for this use case.
CDN as Read-through Cache
The idea is simple, we put the CDN as the caching layer between users and the actual backend services.
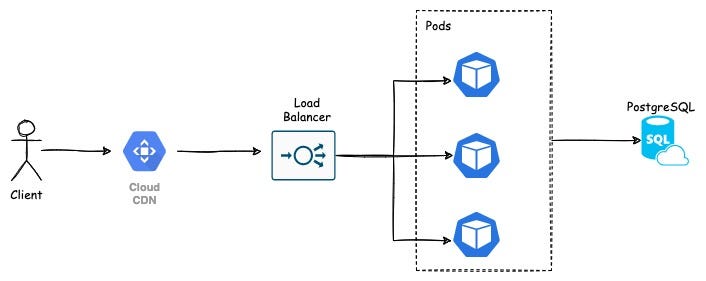
As you can see the CDN sits between the client and our backend service, and thus becomes the cache. In data-flow sequence looks like this
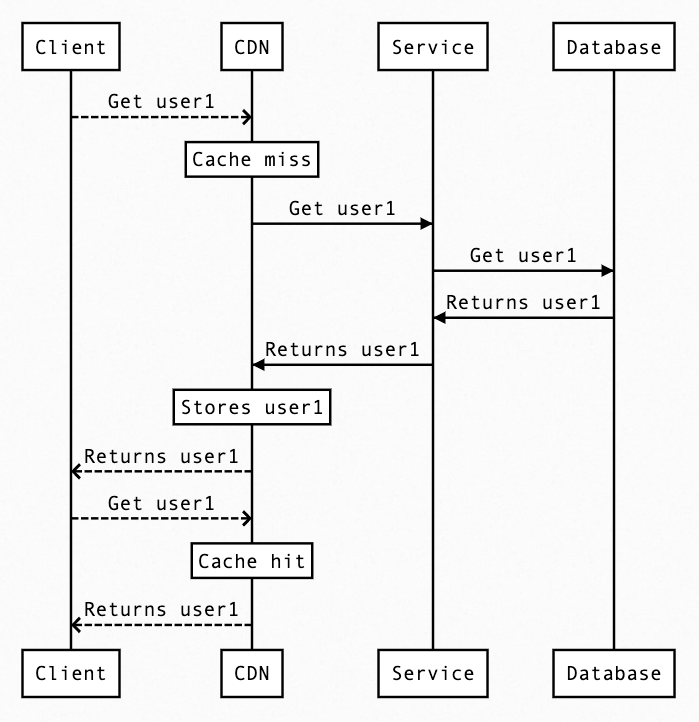
Let’s dig a bit deeper into this since this is the crux of the design
Abbreviations to be used
T1 -> Time instace 1 + some milli seconds
T2 -> Time instace 1 + 1 minute+ some milli seconds
TTL -> Time to live
Origin server -> Your actual backend service in this case
- T1: Client makes a call to get user1.
- T1: The request lands on the CDN.
- T1: The CDN sees it does not have the user1 related key present in its cache-store.
- T1: The CDN reaches out to the upstream, which is your actual backend service, to fetch user1.
- T1: The backend service returns user1 as a standard JSON response.
- T1: CDN receives the JSON, and now it needs to store that.
- So now it needs to decide what should be the TTL for this data, how does it do that?
- There are generally two ways to do that, either the origin server specifies how long the data should be cached or there is a constant value set on the CDN config, it uses that time to set the TTL.
- It’s better to give control to the origin server to set the TTL, that way we have the ability to control the TTL the way we like or have conditional TTL.
- Now the question raises how does the origin server specify the TTL. Cache-control headers to the rescue. The response from the origin server can contain cache-control headers like cache-control: public, max-age:180 . This translates to this data can be publicly cached and it’s valid for 180 seconds.
- T1: Now the CDN sees this and caches the data with a TTL of 180 seconds.
- T1: CDN responds to the caller with the user 1 JSON.
- T2: Another client requests for user1.
- T2: The request lands on the CDN.
- T2: The CDN sees it have the user1 key present in its store, so it does not reach out to the origin server and returns the cached JSON response.
- T3: The cache expires on CDN after 180 seconds.
- T4: Some client requests for user1, but since the cache is empty the flow again starts from Step 3. And this keeps on repeating.
Not necessarily you have to keep the TTL to 180 seconds only. Choose the TTL based on how long you can serve stale data and be okay with it. And if this raises the question why can’t you invalidate the cache on data change, then wait I will answer that shortly in the downsides section.
Implementation
Till now I have mostly talked about the design and didn’t really go into the actual implementation. The reason being the design is pretty simple to be implemented in any setup. For us, our CDN was on Google cloud, and the Kubernetes cluster where the backend services run, is on Azure, so we made the setup according to our need. You might choose to do it on Cloudflare CDN for example, hence not going into implementation and keeping it abstract. But just for the curious minds, this how our production setup looks like.
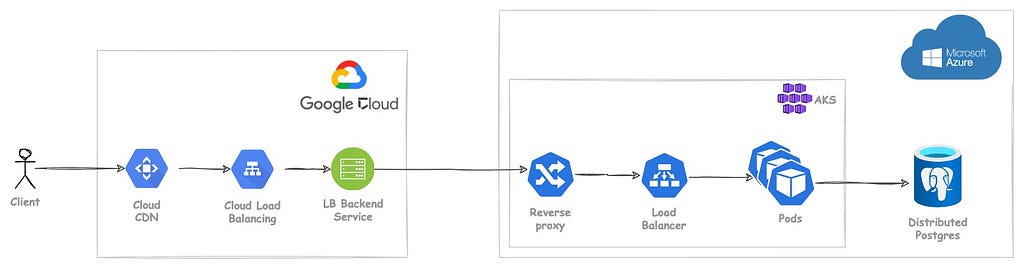
It’s okay if you don’t understand this, if you have understood the concepts, building this would be a piece of cake.
Here’s a wonderful doc from folks at Google Cloud to get you started.
Ok, we are approaching the end now, and any design is incomplete with pros and cons analysis. So let’s analyze the design a bit and see how it helps and how it does not.
Pros of the design
- Simplicity: This design is super simple, easy to implement and maintain.
- Response time: You already know that CDN servers are geographically positioned to optimize the data transfer, and because of that, our response time also became super fast. For example, how does 60ms (Neglecting the TCP connection establishment time) sound like?
- Reduced load: Since the actual backend servers now receive ~ 1 request/ 180 seconds, the load is super low.
- Infrastructure cost: If we didn’t do this, then to handle this kind of load we would have to scale our infrastructure a lot, which comes with a significant cost. But at Glance we were already heavily invested in CDN since we are a content platform, so why not use that. Cost increase to support these APIs now is insignificant now.
The downside of the design
- Cache Invalidation: Cache invalidation is one of the hardest things to get right, in computer science, and with the CDN becoming the cache it’s even harder. Any impromptu cache invalidation on CDN is an expensive process and generally does not happens in real-time. In case your data changes, since we can’t invalidate the cache on CDN, your clients might get stale data for some bit of time. But that again depends on the TTL you set, if your TTL is in hours, then you can invoke cache invalidation on CDN too. But if the TTL is in seconds/ minutes it would be problematic. Also, keep in mind that not all CDN providers expose API to invalidate the CDN cache.
- Less control: Since the requests do not land up on our servers now, there would be this feeling that as a developer you don’t have enough control over the system ( or maybe I am just a control freak ? ). And observability might take a slight hit, you can always set up logging and monitoring on the CDN but that generally comes with a cost.
A few words of wisdom
Any design in a Distributed World is slightly subjective and always has some tradeoffs. It’s our duty as developers/ architects to weigh in the tradeoffs and choose the design that works for us. Having said that no design is concrete enough to continue forever, so given the constraints, we have chosen a certain design, and depending on how it works for us we might evolve it further as well.
Thanks for reading!
I am Aritra Das, I am a Developer, and I really enjoy building complex Distributed Systems. Feel free to reach out to me on Linkedin or Twitter for anything related to tech.
Happy learning…
Building a read-through cache using CDN was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Aritra Das
Aritra Das | Sciencx (2021-07-19T01:25:47+00:00) Building a read-through cache using CDN. Retrieved from https://www.scien.cx/2021/07/19/building-a-read-through-cache-using-cdn/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.