
This content originally appeared on DEV Community and was authored by Chuck Choi
Introduction

We use forks to eat pasta, spoons to eat soup, and chopsticks to eat dumplings. Each silverwares have its advantages/disadvantages, hence working better than the other for the food that it interacts well with. Just like that, different data structures are better suited and perform better than the others based on the situations/use cases. They each have their pros and cons. Understanding these pros and cons can help you be a better programmer, as it will allow you to choose an appropriate data structure(s) based on the circumstances/goals you have, and it helps to drastically improve the performance of the algorithm being applied. I will be putting these blog series together on well known programming data structures in JavaScript, and link them all in one blog post in the future. Feel free to leave a comment if you have any questions!
Table of Contents
1. What Is Hash Table?
2. Hash Function
3. Implementation in JavaScript
4. Helper Functions
5. Handling Collisions
6. Big O
7. Helpful Resources
1. What is Hash Table?
Hash Table is a data structure of associative array that stores key/value paired data into buckets.
Considered being one of the most important data structures in computing, Hash Table is used in many areas of applications: password verifications, cryptography, compilers, and the list goes on. Due to its efficiency and speed in searching, insertion, and removal of data, it is a widely applicable and preferred data structure in many cases. A Hash Table is a data structure of associative array that stores data as a key/value pair into a bucket.
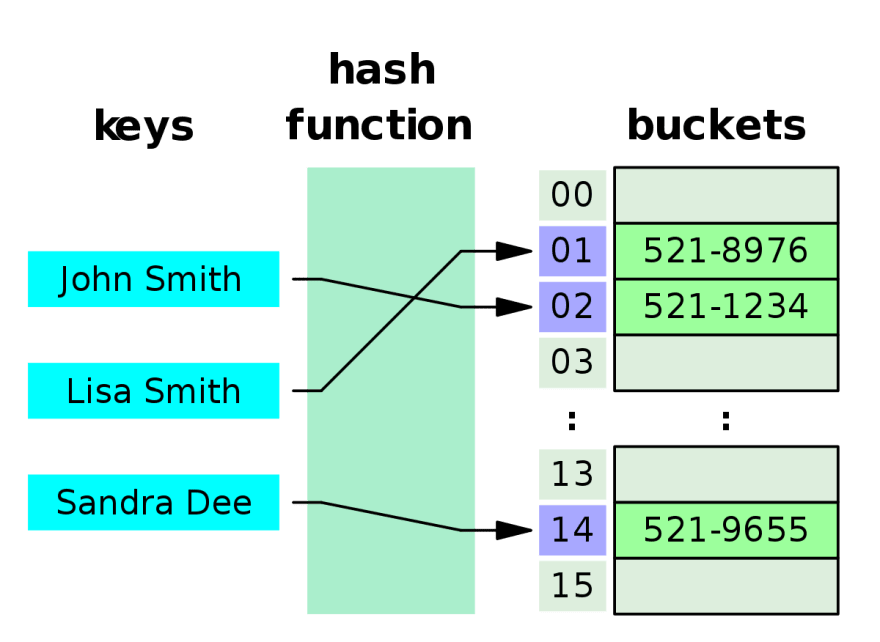
How Hash Table works is that it takes a key and a value as inputs, then runs the key through a hash function that turns it into an index. This process is called hashing. The index is used to map the value of the input into the table's bucket. The hash function is irreversible, which makes it secure and reliable. It is possible for two different keys to result in the same index though, and this is called a collision. A collision can override the previous key's placeholder if not handled. There are various ways to handle hash collisions though -- Separate Chaining being one of them which often uses Linked Lists inside the bucket to store multiple data in the same index. We will get into it later in this post. But first, let's discuss how hash function works in a nutshell.
2. Hash Function
The hashing process in computing is like hashing a potato to make hashed brown.

Hash functions, or hashing algorithms generate a fixed-length result from a given input. This process is called hashing. The fixed-length result is used in Hash Tables as an index to map the input into a hash bucket. The hashing process in computing is like hashing a potato to make hashed brown. You could think of potato as key input, grater as hash function, and shredded potato as index that is hashed out as a result of the hash function. Just like how you can't turn shredded potato back into a whole potato, hash functions are irreversible -- it's a one way algorithm.
Here is an example of a hash function in JavaScript:
function hash (key, size) {
let hashedKey = 0;
for (let i = 0; i < key.length; i++) {
hashedKey += key.charCodeAt(i)
}
return hashedKey % size
}
Pseudocode:
- This function accepts two arguments: string
keyto hash, andsizeof hash buckets - Initialize a variable named
hashedKeyas 0 to return at the end - Iterate each of the string's characters to sum up their character codes
- After the iteration, use modulo operation (%) to find the remainder of the
hashedKey / sizeand set it as newhashedKey - Return
hashedKey
Explanation
In the above algorithm, we are initializing a variable hashedKey as 0. The value of this variable will change based on the string and be returned as a result of this function. We need a way to represent each of the letters into numbers, this way the matching string key that goes through the function will always convert to the same integer. JavaScript's string method charCodeAt() allows us to convert a string character into an integer representing the UTF-16 code unit.
With that being said, we are using a for loop to iterate every character of the key input. For each character being iterated, we are using the charCodeAt() method to convert the character and add it to hashedKey variable we defined at the beginning. Once we sum up all the integers that represents each characters, we execute an modulo operation % using the size of the bucket (second argument of the function) as a divisor. Modulo operation not only guarantees that the resulting integer is in range between 0 to the size of the bucket, but also makes the result irreversible.
This is a very simple and basic hash function that can be improved better. I recommend you to check out this blog post if you are interested in learning about different hash functions designed by mathematicians and computer scientists around the world. Now it is time to implement the hash table in JavaScript!
3. Implementation in JavaScript
class HashTable {
constructor(size=53) {
this.size = size
this.buckets = new Array(size);
}
_hash (key) {
let hashedKey = 0;
for (let i = 0; i < key.length; i++) {
hashedKey += key.charCodeAt(i)
}
return hashedKey % this.size
}
}
let table = new HashTable()
console.log(table) // HashTable {size: 53, buckets: Array(53)}
The above Hash Table class has two properties:
-
size: the number representing thesizeof the buckets, and we are using prime number 53 as a default value (choosing a prime number for the hash table's size reduces the chances of collisions) -
buckets:bucketsare the placeholders for each data (key/value pair), and we are usingArrayclass to create an empty array with size of 53 indices
And we have the _hash method similar to what we created earlier, but only difference is that it is not taking in the size as second argument since we are using the size of the object created from the Hash Table class. With this, we can create an object with buckets array that contains default size of 53 indices or a specified size.
Let's go ahead and add some methods to this Hash Table!
4. Helper Functions
set()
// adds key-value pair into hash table's bucket
set(key, value) {
let index = this._hash(key)
this.buckets[index] = [key, value];
}
Pseudocode:
- Accepts a
keyand avalue - Hashes the
key - Stores the key-value pair in the hash bucket
get()
// retrieves the value of the key from its respective bucket
get(key) {
let index = this._hash(key)
return this.buckets[index][1] // returns value of the key
}
Pseudocode:
- Accepts a
key - Hashes the
key - Retrieves the key-value pair in the hash bucket
remove()
// removes the key-value pair from the hash table's bucket
remove(key) {
let index = this._hash(key)
let deleted = this.buckets[index]
delete this.buckets[index]
return deleted
}
Pseudocode:
- Accepts a
key - Hashes the
key - Retrieves the key-value pair in the hash bucket and stores it
- Delete the key-value pair in the hash bucket (use
deleteoperator to empty the element, doesn't affect the array size) - Returns the stored key-value pair
All the helper functions in this data structure is fairly simple -- they all utilize the hash function we defined earlier to retrieve the index that is associated with the key passed, and access the array's element in that index. There's a problem with these methods though. What happens if the hash function returns the same index for two different inputs? Our hash function is fairly simple so this will happen for sure. If so, it will override the bucket that is already occupied or get method will retrieve a wrong value that we aren't looking for. How can we improve these helper methods to handle the collisions?
5. Handling Collisions

As we discussed earlier, it is possible for a hash function to produce collisions: returning the same index for multiple different keys. Unfortunately, even under the best of circumstances, collisions are nearly unavoidable. Any hash function with more inputs than outputs will necessarily have such collisions; the harder they are to find, the more secure the hash function is.
There are multiple ways to handle collisions though, and the two common techniques are Separate Chaining and Linear Probing.
Separate Chaining: If there is only one hash code pointing to an index of array then the value is directly stored in that index. If hash code of second value also points to the same index though, then we replace that index value with a linked list or array and all values pointing to that index are stored in the list. Same logic is applied while retrieving the values, we will have to iterate all the elements inside a bucket if the bucket stores multiple key-value pairs. In short, separate chaining creates a list-like object inside a bucket to store multiple data with collisions.
Linear Probing: Linear Probing technique works on the concept of keep incrementing the hashed index until you find an empty bucket. Thus, Linear Probing takes less space than Separate Chaining , and perform significantly faster than Separate Chaining (since we don't have to loop through lists inside buckets).
Although Separate Chaining is significantly less efficient than Linear Probing, it is easier to implement. Here's how we can improve the helper methods we defined by utilizing Separate Chaining (we will use Array instead of Linked List for simplicity):
set()
// adds key-value pair into hash table's bucket
set(key, value) {
let index = this._hash(key)
if(!this.buckets[index]) {
this.buckets[index] = [];
}
this.buckets[index].push([key, value]);
}
Pseudocode:
- Accepts a
keyand avalue - Hashes the
key - If the hash bucket is empty, set it as an empty array
- Push the key-value pair in the array inside the bucket
get()
// retrieves the value of the key from its respective bucket
get(key) {
let index = this._hash(key)
if(this.buckets[index]) {
for(let i = 0; i < this.buckets[index].length; i++) {
if(this.buckets[index][i][0] === key) {
return this.buckets[index][i][1]
}
}
}
return undefined
}
Pseudocode:
- Accepts a
key - Hashes the
key - If the bucket is truthy, iterate each key-value pair inside the bucket
- If the
keymatches the pair, return thevalueof the pair - return
undefinedif the bucket is empty
remove()
// removes the key-value pair from the hash table's bucket
remove(key) {
let index = this._hash(key)
if(this.buckets[index]) {
for(let i = 0; i < this.buckets[index].length; i++) {
if(this.buckets[index][i][0] === key) {
return this.buckets[index].splice(i, 1)
}
}
}
}
Pseudocode:
- Accepts a
key - Hashes the
key - If the bucket is truthy, iterate each key-value pair inside the bucket
- If the
keymatches the pair, remove the pair and return it
6. Big O

-
Space Complexity:
- O(n)
- Space complexity of this data structure is linear: as the size of the buckets increase, so does the space
-
Set/Get/Remove:
- Average: O(1) Time Complexity
- Worst Case: O(n) Time Complexity
- All these helper methods use hash function to look up the indices. Hash function takes constant time, but the time complexity can get linear with buckets with multiple elements due to collisions. More items will mean more time to look inside the bucket, hence taking linear time (O(n))
7. Helpful Resources
Online Course (Udemy Course)
Check out this Udemy course named JavaScript Algorithms and Data Structures Masterclass! It is created by Colt Steele, and I referenced his code for the data structure implementation part of this blog post. Personally, I didn't know where to start with algorithms and data structures especially coming from a non-tech background. This course is very well structured for beginners to build a foundation on these topics.
Visual Animation (VisuAlgo)
Data structures can be difficult to comprehend for some people just by looking at the code/text. The instructor in the course above uses a website named VisuAlgo that has visual representation of algorithms and data structures through animation.
Data Structure Cheat Sheet (Interview Cake)
Also, here's a really well-summarized cheat sheet/visualizations on data structures.
CS50's Hash Tables Lesson (YouTube Video)
I came across this YouTube video thanks to one of the DEV Community users Alex @tinydev
! It's part of Harvard's CS50 course, and they do a great job explaining Hash Tables.
This content originally appeared on DEV Community and was authored by Chuck Choi
Chuck Choi | Sciencx (2021-08-16T22:28:31+00:00) Data Structure Series: Hash Table. Retrieved from https://www.scien.cx/2021/08/16/data-structure-series-hash-table/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.