
This content originally appeared on DEV Community and was authored by NDREAN
We expose (lengthy) notes on Kubernetes manifests. We use them to deploy a full stack Rails app on a local Kubernetes cluster, powered by Minikube with the help of Tilt.
no Helm charts, just plain Kubernetes yaml manifests.
To orchestrate the containers with Kubernetes, you build and push images and then deploy manually on the local cluster.
We will use Tilt to orchestrate the (local) deployment: it just needs the Dockerfiles, the Kubernetes manifests, and a Tiltfile to conduct the deployment. It also automatically builds the images and recompiles them on code change: a cool tool. You can also add Starlark code.
In a following post, we will use another tool GruCloud. It is designed to go live in the cloud (you can deploy on Minikube as well). You can select the main providers, AWS EKS or GCC or Azure for example. It uses the more familiar Javascript language instead.
1. The Demo app
We want to run on Kubernetes a very simple app to visualise the load-balancing of the pods as scaled. It uses the classic full stack tooling: PostgreSQL, Redis, background job framework Sidekiq, web sockets with ActionCable, and a web server Nginx in front of Rails. It broadcasts the number of page hits and a click counter to any other connected browser. It also connects to the Kubernetes API to broadcast the existing pods-ID: on every new connection (or page refresh), the counters of the existing pods are refreshed and broadcasted.

2. Vocabulary
Deployment
We use a "Deployment" for a stateless processes. This wraps the "ReplicaSet" controller; it guarantees the number of living pods and enables rolling updates or rolling back. The pods englobe the containers. This Russian doll nesting explains the way manifests are built with matching labels.
When a pod is deployed with a Deployment, then if you try to delete a pod, a new one will be created because of the ReplicaSet. It will aim to recreate one unless you set the count to zero. You should delete the Deployment instead.
StatefulSet
Stateful processes, typically databases, should be deployed as a StatefulSet. We will use local storage here, but in real life, we would use network attached storage or cloud volumes or managed database services as databases should be clustered, for high availability and disaster recovery.
This is used because there is a master/slave relation to sync the pods, with a unique indexing. A StatefulSet comes with a PersistentVolumeClaim and a PersistentVolume.
Services
A pod needs a service to be able to communicate with the cluster's network. Every service is a load balancer, but unless described with spec.type: NodePort, all are internal services, of default type ClusterIP, meaning no access from outside the cluster.
We don't use an Ingress controller. The entry point of the app is via Nginx, thus we want the Nginx service to be external.
Ephemeral volumes with pods
We can illustrate the host based ephemeral volume emptyDir with the side-car pattern where Nginx and Rails are in the same pod. They also share the same network.
spec.volumes:
- name: shared-data
emptyDir: {}
spec.containers:
- name: nginx
image: nginx:1.21.1-alpine
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: rails
image: usr/rails-base
volumeMounts:
- name: shared-data
mountPath: /public
We then just use the 'naked' Nginx official image since the config will be passed with another volume, the ConfigMap.
We will use a separate pod for Nginx in front of Rails.
Configs
All environment variables and configs will be set by Kubernetes, thus externalised. Data is passed to the pods with volumes such as ConfigMap and Secret.
Readiness and Liveness
A pod may need a readiness and/or liveness probe. The first means that we have a signal when the pod is ready to accept traffic, and the second is when a pod is dead or alive. By default, everything is green.
For example, the readiness probe of the Rails pod sends an HTTP request to an (internal) endpoint. The method #ready is render json: { status: 200 }.
readinessProbe:
httpGet:
path: /ready
port: 3000
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 30
timeoutSeconds: 2
[K8s EVENT: Pod rails-dep-58b8b5b48b-7kxp7 (ns: test)] Readiness probe failed:
Get "http://172.17.0.9:3000/ready": dial tcp 172.17.0.9:3000: connect: connection refused
Resources
You can monitor the resources with the Kubernetes dashboard. They are:
- CPU consumption, measured in vCPU/Core: 100m <=> 0.1%.
- memory, measured in mega-bytes.
or use the command
kubectl describe node minikube.
VSCode Kubernetes extension parser complains (!) if you don't set up limits. You may find the correct values by retroaction. For example:
resources:
requests:
memory: "25Mi"
cpu: "25m"
limits:
cpu: "50m"
memory: "50Mi"
Scaling
If you wish to modify the number of replicas of a process, you simply run scale:
kubectl scale deploy sidekiq-dep --replicas=2
kubectl get rs -w
and you watch the ReplicaSet working.
With these measures, but not only, Kubernetes can perform horizontal autoscaling.
kubectl autoscale deploy rails-dep --min=1 --max=3 --cpu-percent=80
This means that Kubernetes can continuously determine if there is a need for more or fewer pods running.
We can use external metrics; a popular example is monitoring with Prometheus, and the usage of a Redis queue length to monitor processes like Sidekiq.
No log collector is implemented here.
Rolling update and back
You can change for example the image used by a container (named "backend" below):
kubectl set image deploy rails-dep backend=usr/rails-base-2
then, check:
kubectl rollout status deploy rails-dep
#or
kubectl get rs -w
and in case of crash looping, for example, you can roll back:
kubectl rollout undo deploy rails-dep
We can also make canary deployments by putting labels.
3. Local Kubernetes cluster with persistent volumes
We will use one image named "usr/rails-base" here. For production deployment, we would use the URL of a repository in a container registry (e.g. ECR).
This image is a two stage built image. It is used by Rails, Sidekiq and Cable, with different commands. The Nginx pod will also use it to extract the static assets, and the migration Job will use it too. It is run without root privileges. In the development mode, we won't tag it since Tilt will timestamp it.
We will also use a "local" Role (i.e. not a ClusterRole) to access to the k8 API.
All the env variables are passed with a ConfigMap or a Secret.
We will set up local volumes.
3.1 Postgres
The standard PV available on the cluster is returned by the command kubectl get storageClass on the system. This is an important topic in real life.

We will make two PVC:

and set two StatefulSet:
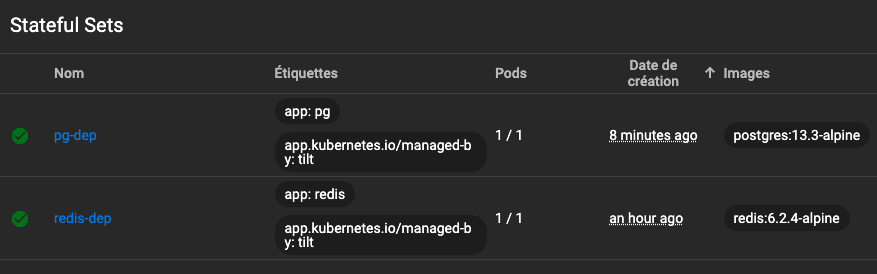
We bind a Persistent Volume (PV) ( admin role) with a Persistent Volume Claim (PVC) (dev role).
#pg-dep.yml
apiVersion: v1
kind: Service
metadata:
name: pg-svc
labels:
app: pg # <- must match with the pod
spec:
ports:
- protocol: TCP
port: 5432 # <- service port opened for Rails
selector:
# the set of pods with the name 'pg' is targeted by this service
app: pg
---
# Deployment
apiVersion: apps/v1
kind: StatefulSet
metadata:
# about the deployment itself. Gives a name of the DEPLOYMENT
name: pg-dep
labels:
app: pg
spec: # of the deployment
serviceName: pg-dep
replicas: 1
selector:
# the deployment must match all pods with the label "app: pg"
matchLabels:
# the label for the POD that the deployment is targeting
app: pg # match spec.template.labels for the pod
template: # blue print of a pod
metadata:
name: pg-pod
# label for the POD that the deployment is deploying
labels:
app: pg # match spec.selector.matchlabels
spec:
volumes:
- name: pg-pv # must match PV
persistentVolumeClaim:
claimName: pg-pvc # must match PVC
containers:
- name: pg-container
image: postgres:13.3-alpine
imagePullPolicy: "IfNotPresent"
resources:
limits:
memory: "128Mi"
cpu: "50m"
ports:
- containerPort: 5432
volumeMounts:
- mountPath: $(PGDATA)
name: pg-pv # must match pv
readOnly: false
envFrom:
- configMapRef:
name: config
- secretRef:
name: secrets
---
# we bind the resource PV to the pod
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pg-pvc
spec:
#storageClassName: standard
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Mi
and the volume:
#pg-db-pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pg-pv
labels:
app: pg
spec:
storageClassName: standard
capacity:
storage: 150Mi
accessModes:
- ReadWriteMany
hostPath: # for Minikube, emulate net. attached vol.
path: "/tmp/data"
3.2 Webserver Nginx
We use the web server image and set an external service for the Nginx deployment since this is the entry-point of the app.
#nginx-dep.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dep
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: usr/nginx-ws
imagePullPolicy: "Always"
name: frontend
ports:
- containerPort: 9000
resources:
limits:
cpu: "32m"
memory: "16Mi"
volumeMounts:
- mountPath: "/etc/nginx/conf.d" # mount nginx-conf volume to /etc/nginx
readOnly: true
name: nginx-conf
volumes:
- name: nginx-conf
configMap:
name: nginx-conf # place ConfigMap `nginx-conf` on /etc/nginx
items:
- key: myconfig.conf
path: default.conf
--------
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer # NodePort # LoadBalancer # <- external service
selector:
app: nginx
ports:
- protocol: TCP
# port exposed by the container
port: 80
# the port the app is listening on targetPort
targetPort: 9000
nodePort: 31000
This illustrates the use of a ConfigMap volume to pass the Nginx config via a mountPath into the pod source
#nginx-conf.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-conf
data:
myconfig.conf: |
upstream puma {
server rails-svc:3000;
keepalive 1024;
}
access_log /dev/stdout main;
error_log /dev/stdout info;
server {
listen 9000 default_server;
root /usr/share/nginx/html;
try_files $uri @puma;
access_log off;
gzip_static on;
expires max;
add_header Cache-Control public;
add_header Last-Modified "";
add_header Etag "";
location @puma {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $http_host;
proxy_set_header Host $http_host;
proxy_pass_header Set-Cookie;
proxy_redirect off;
proxy_pass http://puma;
}
location /cable {
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
proxy_pass "http://cable-svc:28080";
}
error_page 500 502 503 504 /500.html;
error_page 404 /404.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
3.3 Redis
For the Redis store, we didn't pass a config here. We should have used a ConfigMap.
#redis-dep.yml
apiVersion: v1
kind: Service
metadata:
name: redis-svc
spec:
ports:
- port: 6379
targetPort: 6379
name: client
selector:
app: redis
--------
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-dep
labels:
app: redis # match spec.template.labels
spec:
serviceName: redis
selector:
matchLabels:
app: redis
replicas: 1
template:
metadata:
name: redis-pod
labels:
app: redis # # match spec.selector.matchLabels
spec:
containers:
- name: redis
image: redis:6.2.4-alpine
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 6379
command: ["redis-server"]
resources:
limits:
cpu: "50m"
memory: "50Mi"
readinessProbe:
exec:
command:
- redis-cli
- ping
initialDelaySeconds: 20
periodSeconds: 30
timeoutSeconds: 3
volumeMounts:
- name: data
mountPath: "/data"
readOnly: false
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "standard"
resources:
requests:
storage: 100Mi
and the PersistentVolume:
#redis-pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: data
labels:
# type: local
app: data
spec:
storageClassName: hostpath
capacity:
storage: 150Mi
accessModes:
- ReadWriteMany
hostPath: # for Minikube, to emulate net. attached vol.
path: "/data"
3.4 Rails
Again, all ENV vars and credentials will be set within Kubernetes. We will use two volumes, a ConfigMap for the ENV vars and a Secret for credentials:
#config.yml
#rails-dep.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: config
data:
POSTGRES_HOST: "pg-svc" # <- name of the service that exposes the Postgres pod
POSTGRES_DB: "kubedb"
RAILS_ENV: "production"
RAILS_LOG_TO_STDOUT: "true"
RAILS_SERVE_STATIC_FILES: "false"
REDIS_DB: "redis://redis-svc:6379/0"
REDIS_SIDEKIQ: "redis://redis-svc:6379/1"
REDIS_CACHE: "redis://redis-svc:6379/2"
REDIS_CABLE: "redis://redis-svc:6379/3"
The credentials need to be converted with echo -n 'un-coded-value' | base64). This can be documented with a manifest.
#secrets.yml
apiVersion: v1
kind: Secret
metadata:
name: secrets
type: Opaque
data:
POSTGRES_USER: cG9zdGdyZXM= # postgres
POSTGRES_PASSWORD: ZG9ja2VycGFzc3dvcmQ= # dockerpassword
RAILS_MASTER_KEY: NWE0YmU0MzVjNmViODdhMWE5NTA3M2Y0YTRjYWNjYTg=
The manifest of the Rails deployment and its service:
#rails-dep.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: rails-dep
labels: # must match the service
app: rails
spec:
replicas: 1
selector:
matchLabels: # which pods are we deploying
app: rails
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
metadata:
labels: # must match service and replicaset matchlabel
app: rails
spec:
containers:
- name: backend
image: usr/rails-base
imagePullPolicy: "Always"
command: ["bundle"]
args: ["exec", "rails", "server", "-b", "0.0.0.0"]
ports:
- containerPort: 3000
resources:
limits:
cpu: "150m"
memory: "256Mi"
envFrom:
- configMapRef:
name: config
- secretRef:
name: secrets
readinessProbe:
httpGet:
path: /ready
port: 3000
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 30
timeoutSeconds: 2
--------
apiVersion: v1
kind: Service
metadata:
name: rails-svc
labels:
app: rails
spec:
selector:
app: rails
type: ClusterIP # default type
ports:
- protocol: TCP
# port exposed by the service
port: 3000
# the port the app is listening on targetPort
targetPort: 3000
name: http
3.5 Cable and Sidekiq
The deployment of the "cable" is identical except for the args for the command and port. It has its service to expose the cable pod.
The "worker" deployment is also based on the same image, with its own "command" and "args" but no service is required for the worker since it communicates with Rails via a Redis queue.
Cable
#cable-dep.yml
spec:
containers:
- name: cable
image: usr/rails-base
imagePullPolicy: "Always"
command: ["bundle"]
args: ["exec", "puma", "-p", "28080", "./cable/config.ru"]
ports:
- containerPort: 28080
envFrom:
- configMapRef:
name: config
- secretRef:
name: secrets
resources:
limits:
cpu: "150m"
memory: "256Mi"
--------
apiVersion: v1
kind: Service
metadata:
name: cable-svc
labels:
app: cable
spec:
selector:
app: cable
type: ClusterIP # default type
ports:
- protocol: TCP
# port exposed by the service
port: 28080
# the port the app is listening on targetPort
targetPort: 28080
name: http
Sidekiq:
#sidekiq-dep.yml
spec:
containers:
- name: sidekiq
image: usr/rails-base
imagePullPolicy: "Always"
command: ["bundle"]
args: ["exec", "sidekiq", "-C", "./config/sidekiq.yml"]
envFrom:
- configMapRef:
name: config
- secretRef:
name: secrets
resources:
limits:
cpu: "150m"
memory: "256Mi"
We can add a liveness probe by using the gem sidekiq_alive.
3.6 Calling the Kubernetes API
As a normal user, we have an admin-user Service Account and an associated Cluster Role Binding. Within a pod, by default everything is closed, so we need to set a ServiceAccount credential with the RBAC policy, with Role, RoleBinding and ServiceAccount to the Sidekiq deployment.
If we want to call the Kubernetes API (the endpoint of kubectl get ...) to get data from the cluster within our app, we can:
- directly access to the REST API. The credentials are present in each pod so that we can read them; within a thread or Sidekiq job, we execute a
CURLcall to theapiserver, whose result is parsed and filtered:
`curl --cacert #{cacert} -H "Authorization: Bearer #{token}" https://kubernetes.default.svc/api/... `
Note that the
cacertis at the TLS level, not at the HTTPS level.
- do it from within a pod by tunnelling with
kubectl proxy. Since we need an endpoint, we need to run a side-car pod with a Kubernetes server. This solution is "more expensive", a Kubernetes server is a 55 Mb image runningkubectl proxy --port 8001. You run a side-car k8 server with Sidekiq and call the endpoint from a Job:
URI.open(http://localhost:8001/api/v1/namespaces/{namespace}/pods)
Note that you may take profit from using the gem
Ojfor speeding up the JSON parsing.
We now can run "async" Ruby code to fetch the data within a thread.

Then to render in the browser, we broadcast the result through a web socket and the listener will mutate a state to render (with React).
4. Run this with TILT
We have Docker, the Kubernetes CLI and Minikube installed. A normal workflow is to build and push images from Dockerfiles, and then let Kubernetes pull and run the manifests that use the images. We can let Tilt do all this for us and be reactive to changes in the code.
Note that as a Rails user, you may have the gem "tilt" present, so alias
tiltwith "/usr/local/bin/tilt".
Launch Minikube
We may want to namespace the project so that you can isolate different versions or modes (staging, prod) and also clean everything easily. We used the utilities kubectx, kubens to set the namespace.
kubectl create namespace test
# use the utility "kubens" from "kubectx" to assign a namespace
kubens stage-v1
# check:
kubens # => "stage-v1" marked
kubectl config get-contexts # => Minikube marked
A good practice is to apply:
kind: Namespace
apiVersion: v1
metadata:
name: stage-v1
and then use namespace: stage-v1 in the metadata of each kind.
Now the project is isolated within a namespace, we can launch Minikube with minikube start.
List of files
Our files are:
/app
/config
/public
...
/dckf
|_ _builder.Dockerfile
|_ _alpine.Dockerfile
|_ _nginx.Dockefile
Tiltfile
/kube
|_ config.yml
|_ secrets.yml
|_ nginx-config.yml
|_ pg-pv.yml
|_ postgres-dep.yml
|_ redis-pv.yml
|_ redis-dep.yml
|_ rails-dep.yml
|_ sidekiq-dep.yml
|_ cable-dep.yml
|_ nginx-dep.yml
|_ migrate.yml
Deploy
To deploy on the Minikube cluster, once we have built and pulled the images, we run the following commands against all our manifests ❗ in an orderly manner: first run the configs (and secrets) needed by the others processes.
kubectl apply -f ./kube/config.yml
kubectl apply -f ./kube/secrets.yml
...
kubectl apply -f ./kube/rails-dep.yml
...
kubectl apply -f ./kube/migrate.yml
minikube service nginx-svc #<- our app entry point
We will automate all this with Tilt. The Tilt engine will read a Tiltfile and build the full project. It only needs the code (the Dockerfiles and the Kubernetes manifests) and one command.
In this Tiltfile, we describe all the actions we want Tilt and Kubernetes to perform: building images, running manifests and managing dependencies. The one below is a very basic image builder and runner.
#Tilfile
# apply configs and create volumes
k8s_yaml(['./kube/config.yml','./kube/secrets.yml','./kube/nginx-config.yml','./kube/pg-db-pv.yml',
])
# apply databases adapters
k8s_yaml(['./kube/postgres-dep.yml','./kube/redis-dep.yml'])
# <- building images and live changes
docker_build( 'builder', # <- Bob
'.',
dockerfile="./dckf/builder.Dockerfile",
build_args={
"RUBY_VERSION": "3.0.2-alpine",
"NODE_ENV": "production",
"RAILS_ENV": "production",
"BUNDLER_VERSION": "2.2.25"
},
live_update=[sync('./app','/app/app/')],
)
docker_build('usr/rails-base', #<- uses Bob
'.',
build_args={
"RUBY_VERSION": "3.0.2-alpine",
"RAILS_ENV": "production",
"RAILS_LOG_TO_STDOUT": "true",
},
dockerfile='./docker/rails.Dockerfile',
live_update=[sync('./app','/app/app/')],
)
docker_build("usr/nginx-ws", # <- uses Bob
".",
dockerfile="./dckf/nginx-split.Dockerfile",
build_args={
"RUBY_VERSION": "3.0.2-alpine", "RAILS_ENV": "production"
},
live_update=[sync('./app','/app/app/')]
)
# -> end images
# dependencies
k8s_resource('sidekiq-dep', resource_deps=['redis-dep'])
k8s_resource('rails-dep', resource_deps=['pg-dep', 'redis-dep'])
k8s_resource('cable-dep', resource_deps=['redis-dep'])
k8s_resource('nginx-dep', resource_deps=['rails-dep'])
# apply processes
k8s_yaml(['./kube/rails-dep.yml', './kube/sidekiq-dep.yml', './kube/cable-dep.yml', k8s_yaml('./kube/nginx-dep.yml'])
# <- creates manual/auto action button in the Tilt GUI
# migration
k8s_resource('db-migrate',
resource_deps=['rails-dep','pg-dep'],
trigger_mode=TRIGGER_MODE_MANUAL,
auto_init=False
)
k8s_yaml('./kube-split/migrate.yml' )
# auto (&manual) display pods in GUI
local_resource('All pods',
'kubectl get pods',
resource_deps=['rails-dep','sidekiq-dep','cable-dep','nginx-dep']
)
# ->
allow_k8s_contexts('minikube')
k8s_resource('nginx-dep', port_forwards='31000')
Notice the two stage build: the image is only build once even if reused four times. Notice also the live_update to synchronise the code between the host and the container.
To run this:
tilt up
or all in one (unless you need to create the Postgres database): run the Docker daemon (open -a Docker on OSX)
minikube start && kubectl create ns test && kubens test && tilt up
Then we need to migrate (see below), and with our settings, we can navigate to http://localhost:31000 to visualise the app.
For a quick clean up, run (as docker-compose down):
tilt down
#or
kubectl delete ns test
Dependencies ordering
We specified resources dependencies with k8s_resource.
Migration Job
The topic of performing safe migrations is a very important subject of its own (new migration on old code, old migration with new code).
Every time you stop Minikube and Tilt, you need to run a migration. You can an initContainer that waits for the db, or a Job.
#migrate.yml
apiVersion: batch/v1
kind: Job
metadata:
name: db-migrate
spec:
template:
spec:
restartPolicy: Never
containers:
- name: db-migrate
image: usr/rails-base
imagePullPolicy: IfNotPresent
command: ["bundle", "exec", "rails", "db:migrate"]
envFrom:
- secretRef:
name: secrets
- configMapRef:
name: config
You can run k8s_yaml('./kube/migrate.yml') to apply this.
Alternatively, you can do this programatically with Tilt with k8s_resource where you specify the needed dependencies, and then apply with k8s_yaml.
Below is an example of the manual custom db-migrate action. With the two last flags, we have an action button in the GUI to trigger this migration when ready.
k8s_resource('db-migrate',
resource_deps=['rails-dep','pg-dep'],
trigger_mode=TRIGGER_MODE_MANUAL,
auto_init=False
)
k8s_yaml('./kube-split/migrate.yml' )

[K8s EVENT: Pod db-migrate-vh459 (ns: test)] Successfully pulled image "/rails-base" in 1.481341763s
Migrating to CreateCounters (20210613160256)
== 20210613160256 CreateCounters: migrating ===================================
-- create_table(:counters)
-> 0.4681s
== 20210613160256 CreateCounters: migrated (0.4694s) ==========================
If needed, run kubectl delete job db-migrate to be able to run the job.
Using local_resource
If we want to list automatically the Rails pods, we add a "local_resource" in the Tiltfile. As such, it will be run automatically when Rails is ready. This will also add a button in the UI that we can rerun on demand.
local_resource('Rails pods',
"kubectl get pods -l app=rails -o go-template --template '{{range .items}}{{.metadata.name}}{{\"\n\"}}{{end}}' -o=name ",
resource_deps=['rails-dep']
)
Tilt UI
The Tilt UI comes in two flavours:
- a terminal, essentially an easy log collector
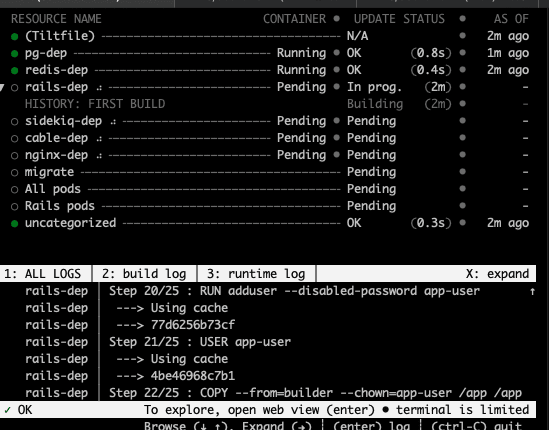
- a nice GUI at "http://localhost:10350" from which you can for example easily read the logs or trigger rebuilds.

Kubernetes dashboard
To enable the Kubernetes dashboard, run:
minikube addons list
minikube addons enable dashboard
minikube addons enable metrics-server
The command minikube dashboard shows the full state of the cluster. Just select the namespace. We can see the logs for each pod, and the resource consumption, globally and per process.

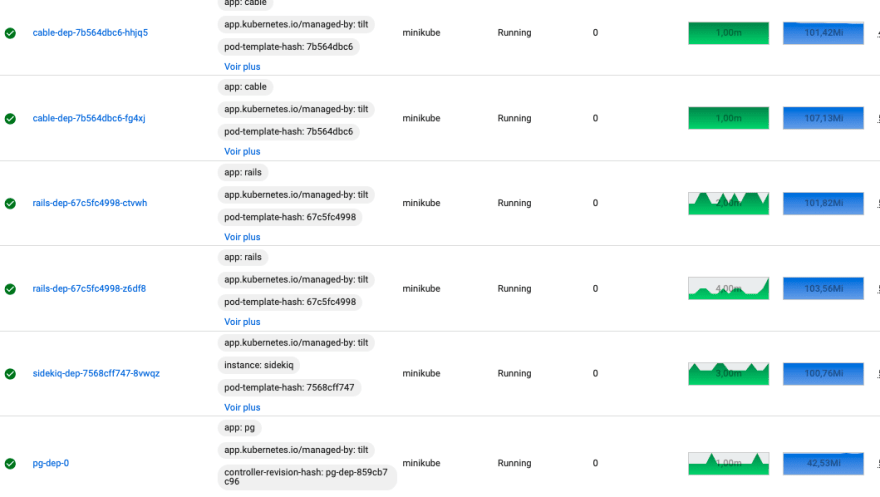
Resources with kubectl
The command:
kubectl describe node minikube
gives the details of the resource usage of the cluster.

HPA
Once we have the measures, we can start to autopilot selected processes with HorizontalPodAutoscaler.
We can run the command kubectl autoscale
local_resource('hpa',
'kubectl autoscale deployment rails-dep --cpu-percent=80 --min=1 --max=3',
resource_deps=['rails-dep'],
trigger_mode=TRIGGER_MODE_MANUAL,
auto_init=False
)
or apply the manifest:
#rails-hpa.yml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: rails-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: rails-dep
minReplicas: 1
maxReplicas: 3
#targetCPUUtilizationPercentage: 80
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
with
k8s_yaml('./kube/rails-hpa.yml')
k8s_resource('rails-hap', resource_deps=['rails-dep'])
We can use simple load tests to check.
5. Misc files
Cheat sheet
# waiting pods checking
kubectl get pods -w -o wide
# follow the logs of a pod
kubectl logs rails-nginx-dep-1231313 -c rails -f
# delete a deployment (pod+svc+replicaset) or job
kubectl delete deploy rails-dep
kubectl delete job db-migrate
# launch a browser
minikube service rails-nginx-svc # !! OSX !!
# launch the Kubernetes dashboard
minikube dashboard
# ssh into the VM (user docker, private key)
minikube ssh
# generate a token which grants admin permissions:
kubectl --namespace kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
# ssh
ssh -i ~/.minikube/machines/minikube/id_rsa docker@$(minikube ip)
# get programmatically info
kubectl get service nginx-svc -o jsonpath='{.spec.ports[0].nodePort}'
# execute a command in a pod with several containers (name it with "-c")
kubectl exec it -rails-nginx-dep-1234 -c rails -- irb
irb(main):001:0> require 'socket'; Socket.gethostname
=> "rails-nginx-dep-55bc5f77dc-48wg4"
# execute a command in a pod
kubectl exec -it pg-dep-0 -- psql -w -U postgres
kubectl exec -it redis-dep-0 -- redis-cli
# rolling update by setting a new image to a deployment
kubectl set image deployment/rails-dep usr/rails-base2
# check
kubectl rollout status deployment/rails-dep
# undo in case of a problem
kubectl rollout undo depoyment/rails-dep
Builder
ARG RUBY_VERSION=3.0.2-alpine
FROM ruby:${RUBY_VERSION:-3.0.1-alpine} AS builder
ARG BUNDLER_VERSION
ARG NODE_ENV
ARG RAILS_ENV
RUN apk -U upgrade && apk add --no-cache \
postgresql-dev nodejs yarn build-base tzdata
ENV PATH /app/bin:$PATH
WORKDIR /app
COPY Gemfile Gemfile.lock package.json yarn.lock ./
ENV LANG=C.UTF-8 \
BUNDLE_JOBS=4 \
BUNDLE_RETRY=3 \
BUNDLE_PATH='vendor/bundle'
RUN gem install bundler:${BUNDLER_VERSION} --no-document \
&& bundle config set --without 'development test' \
&& bundle install --quiet
RUN yarn --check-files --silent --production && yarn cache clean
COPY . ./
RUN bundle exec rails webpacker:compile assets:clean
Rails Dockerfile
FROM builder AS bob
FROM ruby:${RUBY_VERSION:-3.0.2-alpine}
ARG RAILS_ENV
ARG NODE_ENV
ARG RAILS_LOG_TO_STDOUT
RUN apk -U upgrade && apk add --no-cache libpq tzdata netcat-openbsd \
&& rm -rf /var/cache/apk/*
# -disabled-password doesn't assign a password, so cannot login
RUN adduser --disabled-password app-user
USER app-user
COPY --from=bob --chown=app-user /app /app
# COPY --from=builder /app /app
ENV RAILS_ENV=$RAILS_ENV \
RAILS_LOG_TO_STDOUT=$RAILS_LOG_TO_STDOUT \
BUNDLE_PATH='vendor/bundle'
WORKDIR /app
RUN rm -rf node_modules
Web-server Dockerfile
#_nginx-ws.Dockerfile
FROM ndrean/builder AS bob
FROM nginx:1.21.1-alpine
COPY --from=bob ./app/public /usr/share/nginx/html
Simple load test
You can run a simple load test:
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://localhost:31000; done"
If we have a domain, we can also use the "ab" Apache Bench: we test here how fast the app can handle 1000 requests, with a maximum of 50 requests running concurrently:
ab -n 100 -c 10 https://my-domain.top/
[sources]:
Happy coding!
This content originally appeared on DEV Community and was authored by NDREAN
NDREAN | Sciencx (2021-08-20T22:09:25+00:00) Rails on Kubernetes with Minikube and Tilt. Retrieved from https://www.scien.cx/2021/08/20/rails-on-kubernetes-with-minikube-and-tilt/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.