
This content originally appeared on Level Up Coding - Medium and was authored by Conor Aspell

Over the past month, my old post on automatically managing your Fantasy Premier League (FPL) team has gained a lot of traction. However, I’m not happy with it as a tutorial for a few reasons.
#1 Issues with how the library returned the data lead to some unnecessary lines of code which could be improved.
#2 I used iterrows() which is pretty much always terrible and should be avoided.
#3 The Fantasy Premier League’s “Fixture Difficulty Rating” is terrible and never accurate, I want to use a better metric.
#4 It relied on using Docker and AWS ECS Fargate, this isn’t necessarily bad as they are important technologies to learn for beginner to intermediate programmers (which this blog is aimed at), however, setting up Docker on a Windows machine (the most popular OS despite my love of Linux) is a pain that shouldn’t be part of a simple and fun project like a Fantasy Football bot.
I will still leave it up as it is a useful guide to the FPL library but I’ve decided to revisit the project with the intention of making it simpler by:
· Only using Requests and Pandas libraries.
· Using AWS Lambda with a layer for Pandas.
I think this will be a big improvement as if you can do a repetitive task like switching players with Lambda, you probably should as it is the cheapest service on AWS.
I would also like to add that if you use this tutorial to manage multiple teams your account is at risk of getting banned, like the leading player of FPL did recently.
For this tutorial you will need an AWS account, an FPL account and a Python environment.
Goal:
We want to have our Fantasy Premier League team update each week without us doing anything.
Road map:
We are going to need to achieve a few things to get this to work.
1. We are going to need to get data on which players are in our team, data on Premier League teams, data on Premier League players and data on what fixtures are coming up.
2. We need to know what number gameweek is coming up and we want to know if a deadline is within 24 hours so we only make a change before the deadline.
3. We need to give a weighting to each player on our selected team based on their form, their upcoming fixtures and whatever other data we decide to use and pick one to transfer out.
4. We need to give a weighting to each player that we could potentially pick based on their form, their upcoming fixtures and whatever other data we decide to use and pick one to transfer in.
5. We need to give a weighting to each player on our selected team based on their form, their upcoming fixtures and whatever other data we decide to use and pick 11 players to start and which one is captain.
6. We need to post our team to the website using the FPL API.
7. We need to make a Lambda layer that includes Pandas.
8. We need to deploy our code to Lambda and add a trigger to run the code every day.
0. Set Up
We need to get our user id from FPL (Fantasy Premier League). If you go to the “points” section of the website you will see the url looks like this “https://fantasy.premierleague.com/entry/user_id/event/2”. The 6993864 is my teams user ID, yours will be different. We will pass in our email, password and user_id into the update team method. You can use environment variables if you want to keep the values private.

To set up your python environment, run the following commands for Windows:
python -m venv venv
source venv/Scripts/activate
pip install pandas
pip install requests
pip install datetime
Our main that will be triggered is called lambda_handler as that is the default name on AWS Lambda, event and context are mandatory fields.
def lambda_handler(event, context):
email = "your_email"
password = "your_password"
user_id = "your_user_id"
update_team(email, password,user_id)
1 & 2. Getting the Data & Checking to Run
Following this post, I made a method to help with the get requests.
def get(url):
response = requests.get(url)
return json.loads(response.content)
The API endpoint that provides the vast majority of data is “https://fantasy.premierleague.com/api/bootstrap-static/”. Once we get the response we make dataframes out of elements, teams and events. Players are typically referred to as “elements” in the API and gameweeks are events.
def get_data():
players = get('https://fantasy.premierleague.com/api/bootstrap-static/')
players_df = pd.DataFrame(players['elements'])
teams_df = pd.DataFrame(players['teams'])
events_df = pd.DataFrame(players['events'])We need to next calculate out what gameweek we are in before getting the fixtures. We will use the events_df for this as it has every gameweeks start date in it.
today = datetime.now().timestamp()
events_df = events_df.loc[events_df.deadline_time_epoch>today]
gameweek = fixtures_df.iloc[0].id
At this point, since we have todays timestamp we can add 24 hours using timedelta and see if a deadline occurs. This lets us decide whether to run the full program or exit immediately, saving running time on AWS Lambda.
if check_update(fixtures_df) == False:
print("Deadline Too Far Away")
exit(0)
def check_update(df):
today = datetime.now()
tomorrow=(today + timedelta(days=1)).timestamp()
today = datetime.now().timestamp()
df = df.loc[df.deadline_time_epoch>today]
deadline = df.iloc[0].deadline_time_epoch
if deadline<tomorrow:
return True
else:
return False
Now that we have our gameweek we can send a request to the API for the upcoming fixtures.
fixtures = get('https://fantasy.premierleague.com/api/fixtures/?event='+str(gameweek))
fixtures_df = pd.DataFrame(fixtures)Before returning all the data, I want to do some cleaning first. You can inspect the “players_df” and you will notice that all the fields for “chance_of_playing_this_round” are NaN. This field will remain NaN until the player gets injured, we want to fill all NaNs with 100.
players_df.chance_of_playing_next_round = players_df.chance_of_playing_next_round.fillna(100.0)
players_df.chance_of_playing_this_round = players_df.chance_of_playing_this_round.fillna(100.0)
You will also notice that the players team name will not appear, only the teams ID.
We want the team name in the fixtures dataframe and the player dataframe to make any investigations clearer. There are a few ways to achieve this, such as doing a merge but we will do a mapping instead as it is a lot lighter and faster.
We make a dictionary from the id to the team name in the team dataframe.
teams=dict(zip(teams_df.id, teams_df.name))
Then we can map this into new columns in the players dataframe and the fixtures dataframe.
players_df['team_name'] = players_df['team'].map(teams)
fixtures_df['team_a_name'] = fixtures_df['team_a'].map(teams)
fixtures_df['team_h_name'] = fixtures_df['team_h'].map(teams)
In the teams dataframe you will notice that each team has a rating for how strong they are away and at home. In my last post I used the FDR field in the fixtures dataframe but it makes more sense to use this rating as it is more accurate. We can create a dictionary of the teams away and home strength and map it to home and away team in the fixtures dataframe.
home_strength=dict(zip(teams_df.id, teams_df.strength_overall_home))
away_strength=dict(zip(teams_df.id, teams_df.strength_overall_away))
fixtures_df['team_a_strength']=fixtures_df['team_a'].map(away_strength)
fixtures_df['team_h_strength']=fixtures_df['team_h'].map(home_strength)
The last thing in this stop we want to do is have a column in the players dataframe for how difficult their upcoming game is. We are going to do this by merging the players and fixtures dataframe twice, once on the away teams and once on the home teams, calculating the dataframe and then appending them back together.
As both players and fixtures have a field called “id”, we will drop the id from fixtures first.
fixtures_df=fixtures_df.drop(columns=['id'])
a_players = pd.merge(players_df, fixtures_df, how="inner", left_on=["team"], right_on=["team_a"])
h_players = pd.merge(players_df, fixtures_df, how="inner", left_on=["team"], right_on=["team_h"])
a_players['diff'] = a_players['team_a_strength'] - a_players['team_h_strength']
h_players['diff'] = h_players['team_h_strength'] - h_players['team_a_strength']
players_df = a_players.append(h_players)
Now we can just return the players and fixtures dataframe (we won’t need the teams dataframe) and the game week.
Here is the full code for Parts 1&2:
Part 3 — Selecting Player Out
There are 4 decisions to make each gameweek in FPL.
- Which player to transfer out.
- Which player to transfer in.
- Which players to start/sub.
- Which players to captain/vice captain
We will create 3 weightings to make each decision. These weightings are completely arbitrary and the data I use to make them in this tutorial could be completely different to what you decide to use.
As the API requires us to authenticate we will make a requests session and log in using our username and password.
session = requests.session()
data = {'login' : email, 'password' : password, 'app' : 'plfpl-web', 'redirect_uri' : 'https://fantasy.premierleague.com/'}
login_url = "https://users.premierleague.com/accounts/login/"
session.post(url=login_url, data=data)
We can now get our team using our teams id that we got in step 0.
url = "https://fantasy.premierleague.com/api/my-team/" + str(id)
team = session.get(url)
team = json.loads(team.content)
You will notice that this does not return all the data we need but it does return the players id. If we put it into a list we can use Pandas loc function to filter our players_df to return all of our players as well as all players that are not in our team using the ‘~’ operator.
players = [x['element'] for x in team['picks']]
my_team = players_df.loc[players_df.id.isin(players)]
potential_players = players_df.loc[~players_df.id.isin(players)]
The return also includes our “bank” value which will be useful in filtering out potential players.
bank = team['transfers']['bank']
Now we get to decide how to weigh our team to transfer out players. Some factors you could use are:
- The fixture difficulty we calculated earlier.
- The players form.
- The players availability.
- The players “Expected Points” calculated by FPL.
- The players “Influence, Creativity, Threat Index” calculated by FPL.
- The players transfers in/out for the gameweek.
- Position.
- A team playing twice in a gameweek.
If you wanted to you could collect other data like betting data, weather data for the location of the game (bad weather typically means fewer goals) or FIFA player ratings.
I will use the players fixture difficulty, form, availability and I’ll give goalkeepers extra points as I don’t want to swap goalkeepers during the season. I will also use a subtractive method, giving all players 100 points and taking points away for positive metrics and adding more points for negatives.
I will also avoid using iterrows as it is too slow and we will get charged if Lambda runtime goes above 1 million ms a month (impossible if this is the only thing you are doing on Lambda but its always good to optimise).
def calc_out_weight(players):
players['weight'] = 100
players['weight']-= players['diff']/3
players['weight']-= players['form'].astype("float")*10
players['weight']+= (100 - players['chance_of_playing_this_round'].astype("float"))*0.2
players.loc[players['element_type'] ==1, 'weight'] -=10
players.loc[players['weight'] <0, 'weight'] =0
return players.sample(1, weights=players.weight)
I returned a player based on weighted randomness but you could just return the worst player to transfer out.
This is what my dataframe looks like, Son, Schmeical and Lloris all have a 0% chance of being transferred out with Zaha being the most likely to be transferred out, however, as it is weighted randomness, Alexander-Arnold is recommended to be transferred out (Liverpool have a tough game against Chelsea this week).
Part 4 — Deciding Player In
We want to now drop the player from our team and filter out potential players that cost too much, play in different positions or play for invalid teams (we already have 3 players from that team).
position = player_out.element_type.iat[0]
out_cost = player_out.now_cost.iat[0]
budget = bank + out_cost
dups_team = my_team.pivot_table(index=['team'], aggfunc='size')
invalid_teams = dups_team.loc[dups_team==3].index.tolist()
potential_players=potential_players.loc[~potential_players.team.isin(invalid_teams)]
potential_players=potential_players.loc[potential_players.element_type==position]
potential_players = potential_players.loc[potential_players.now_cost<=budget]
We now want to weight the potential players, its similar to what we did before in that you can use whatever data you want to weigh the players but I will use the same data as before but with an additive method this time.
def calc_in_weights(players):
players['weight'] = 1
players['weight'] += players['diff']/3
players['weight'] += players['form'].astype("float")*10
players['weight'] -= (100 - players['chance_of_playing_this_round'].astype("float"))*0.2
players.loc[players['weight'] <0, 'weight'] =0
return players.sample(1, weights=players.weight)
Again I’m choosing a random player based on their weight, it might be better just to pick the top player.
These are the top defenders recommended to be transferred in, Mings is the player selected by weighted randomness (Aston Villa are at home to Brentford).
The final weighting will be to decide the starting players and the captain/vice captain. We first add the new player into our starting team and then call the function.
player_in = calc_in_weights(potential_players)
my_team = my_team.append(player_in)
my_team = calc_starting_weight(my_team)
Part 5 — Deciding Our Starters
We could just use the same method to get the incoming player to weight our team but I would rather put more emphasis on an easy game than form for our starters, we also need to return a data frame sorted by weight.
def calc_starting_weight(players):
players['weight'] = 1
players['weight'] += players['diff']/2
players['weight'] += players['form'].astype("float")*5
players['weight'] -= (100 - players['chance_of_playing_this_round'].astype("float"))*0.2
players.loc[players['weight'] <0, 'weight'] =0
return players.sort_values('weight', ascending=False)
Selecting our final team is a little complicated as we need to have just 1 goalkeeper and at least 3 defenders (2–6–2, 2–5–3 are invalid formations). I decided to just have always have just 3 defenders and run only 3–4–3 and 3–5–2 formations.
goalies = my_team.loc[my_team.element_type==1]
defenders = my_team.loc[my_team.element_type==2]
outfied_players = my_team.loc[my_team.element_type>2]
captain = outfied_players.id.iat[0]
vice_captain = outfied_players.id.iat[1]
starters = goalies.head(1).append(defenders.head(3)).append(outfied_players.head(7))
subs = goalies.tail(1).append(defenders.tail(2)).append(outfied_players.tail(1))
For captain, I decided to make the best midfielder or striker the captain, in this case it is Son (Tottenham are at home to Watford).
Part 6 — Uploading the Changes
To upload our changes we need to make a “payload” and send it to a url. The payload should look like this:
{'transfers': [{'element_in': 176, 'element_out': 125, 'purchase_price': 50, 'selling_price': 50}], 'chip': None, 'entry': '6993864', 'event': 3}- Element in is our player in’s id.
- Element out is our player out’s id
- Purchase price is our player in’s price
- Selling Price is our player out’s price.
- Entry is our teams’ id.
- Event is the game week.
We will also need some headers for the request:
headers = {'content-type': 'application/json', 'origin': 'https://fantasy.premierleague.com', 'referer': 'https://fantasy.premierleague.com/transfers'}transfers = [{"element_in" : int(player_in.id.iat[0]), "element_out" : int(player_out.id.iat[0]),"purchase_price": int(player_in.now_cost.iat[0]), "selling_price" : int(player_out.now_cost.iat[0])}]transfer_payload = { "transfers" : transfers,"chip" : None,"entry" : id,"event" : int(gameweek)}url = 'https://fantasy.premierleague.com/api/transfers/'
session.post(url=url, data=json.dumps(transfer_payload), headers=headers)
To post our starting team, the payload should look like this:
'picks': [{'element': 353, 'is_captain': False, 'is_vice_captain': False, 'position': 1}, {'element': 288, 'is_captain': False, 'is_vice_captain': False, 'position': 2}...{'element': 63, 'is_captain': False, 'is_vice_captain': False, 'position': 15}], 'chip': None}Some positions are reserved for certain positions i.e. goalkeepers at 1 and 12 and defenders at 2, 3 and 4. We also need to know the id of our captain and vice captain, I just set it to the 2 best midfielders/forwards.
captain = outfied_players.id.iat[0]
vice_captain = outfied_players.id.iat[1]
I decided to do a nested loop to build the payload where the outer loop gets the starters by position, builds their entry and then a second loop to get the subs and append them.
picks =[]
count = 1
for i in range(1,5):
players = starters.loc[starters.element_type==i]
ids = players.id.tolist()
for ide in ids:
if ide == captain:
player = {"element" : ide, "is_captain" : True, "is_vice_captain" : False, "position" : count}
elif ide == vice_captain:
player = {"element" : ide, "is_captain" : False, "is_vice_captain" : True, "position" : count}
else:
player = {"element" : ide, "is_captain" : False, "is_vice_captain" : False, "position" : count}
picks.append(player.copy())
count+=1
ids = subs.id.tolist()
for ide in ids:
player = {"element" : ide, "is_captain" : False, "is_vice_captain" : False, "position" : count}
picks.append(player.copy())
count+=1
team_sheet = {"picks" : picks,"chip" : None}
headers = {'content-type': 'application/json', 'origin': 'https://fantasy.premierleague.com', 'referer': 'https://fantasy.premierleague.com/my-team'}
url = 'https://fantasy.premierleague.com/api/my-team/'+str(id) + '/'
session.post(url=url, json=team_sheet,headers=headers)
Here is the full code for our lambda.
Part 7 — Making a Lambda layer
AWS Lambda is a function as a service offering, by design its meant to be the fastest, lightest, cheapest way to get code running on the cloud. However, this means that there is a limited number of python packages installed, this does not include requests or pandas.
If you have a Linux machine its possible to build a layer locally and push it to AWS but for Windows the easiest way is to go to Cloud9 hit “Create Environment” > Give your environment a name and hit “Next Step” > Leave all the defaults and hit “Create Environment”.
It takes a while to start up but once it does go to the terminal in the bottom half of the screen and run the following bash commands.
mkdir folder
cd folder
virtualenv v-env
source ./v-env/bin/activate
pip install pandas
pip install requests
deactivate
Then run these commands to create the layer
mkdir python
cd python
cp -r ../v-env/lib64/python3.7/site-packages/* .
cd ..
zip -r panda_layer.zip python
aws lambda publish-layer-version --layer-name pandas --zip-file fileb://panda_layer.zip --compatible-runtimes python3.7
Finally, you should go back to Cloud9 and delete the environment.
Part 8 — Deploying the Lambda
Navigate to the Lambda page and hit “Create Function”. Give your function a name and select the runtime as python 3.7.
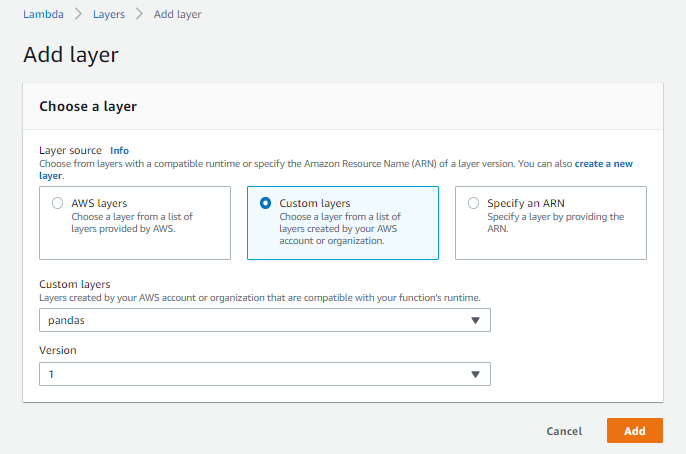
At the bottom of the page you will see “Layers”, click “Add a layer”, navigate to “Custom Layers”, select “Pandas” and version “1”.
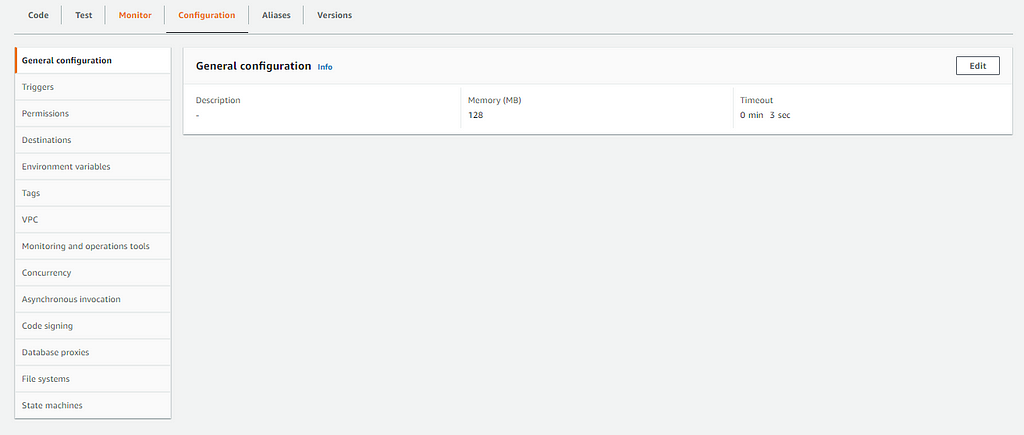
Next, go to configuration > general configuration and edit the timeout to 15 minutes (the maximum).
You can paste your code into the console or else you can put it in a zip file and upload it or you could even deploy it using the AWS CLI. Hit “Deploy”.
When the changes have deployed, hit “Test”, and name your test event. Hit “Test” again. If the deadline is not within the next 24 hours you should get a message like this:
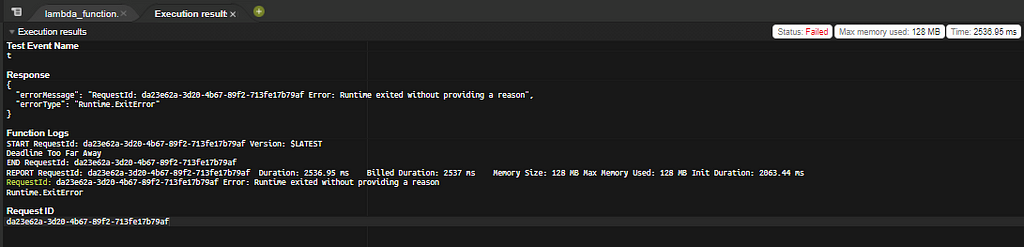
If the deadline is within 24 hours, you should get a success message instead.
The very last thing to do is to set it to trigger every 24 hours.

Select “Add Trigger” > “Event Bridge”. Then fill in the form as in the image below.

And then hit “Add”.
The Lambda will now run once a day and only make changes in the 24 hours leading up to a deadline.
Conclusion
This was a fun project and I recommend trying it if you are a beginner/intermediate developer interested in learning more about Pandas in Python.
If you found this useful feel free to give this a clap or follow me on Medium or LinkedIn.
UPDATED: Automatically Manage your Fantasy Premier League Team with Python and AWS Lambda. was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Conor Aspell
Conor Aspell | Sciencx (2021-08-22T21:01:43+00:00) UPDATED: Automatically Manage your Fantasy Premier League Team with Python and AWS Lambda.. Retrieved from https://www.scien.cx/2021/08/22/updated-automatically-manage-your-fantasy-premier-league-team-with-python-and-aws-lambda/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.