
This content originally appeared on DEV Community and was authored by Leonardo de Sá
Introdução
Neste artigo, você irá entender o que é o Node.JS, e a sua principal funcionalidade que é indispensável para qualquer desenvolvedor compreender o funcionamento da linguagem, chamada de Event Loop.
O que é o Node.js
Node.js, ou simplesmente Node, é um software de código aberto baseado no interpretador V8 do Google e que permite a execução do código javascript do lado do servidor de forma simples, rápida e performática.
Interpretador do Node
O Interpretador é um software especializado que interpreta e executa javascript. O Node utiliza o Interpretador V8, que tem como proposta acelerar o desempenho de uma aplicação compilando o código Javascript para o formato que a máquina irá entender antes de executá-lo.
Call Stack
É uma pilha de eventos, esses eventos podem ser uma função disparada pelo código. Por isso o event-loop fica monitorando para que, toda vez que uma função for disparada, ele deverá executá-la somente uma coisa por vez.
Vamos ver um exemplo:

Aqui temos um exemplo bem simples para entendermos como funciona a stack. Basicamente a função generateCarDescription é chamada recebendo o nome do carro e sua versão, e retorna uma sentença com os parâmetros concatenados. A função generateCarDescription depende da função generateNameAndVersion, que é responsável por unir as informações de nome e versão.
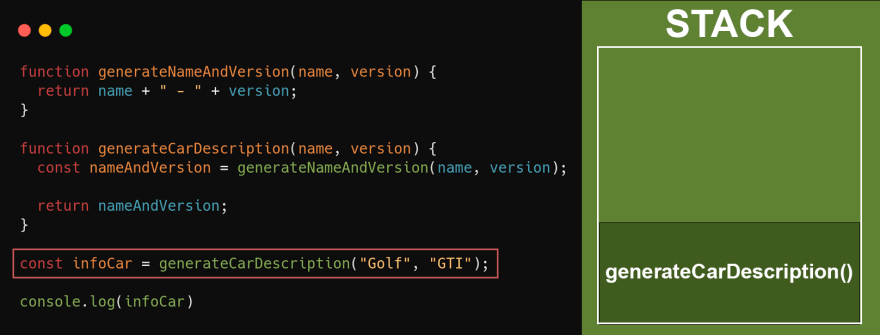
Quando a função generateCarDescription é invocada, ela depende da função generateNameAndVersion para atribuir o valor do nome e versão do carro na variável nameAndVersion e, quando ela for chamada, ela será adicionada na stack como no exemplo abaixo:

Após a execução da funcão generateCarDescription, logo em seguida a variável nameAndVersion irá receber o retorno da função generateNameAndVersion que foi imediatamente adicionada na stack, até que sua execução finalize e o retorno seja feito. Após o retorno, a stack ficará assim:

A última etapa será retornar a variável nameAndVersion, que contém o nome e versão do veículo. Isso não irá alterar em nada na stack. Quando a função generateCarDescription terminar, as demais linhas serão executadas. No nosso exemplo será o console.log() imprimindo a variável infoCar. E por fim, será adicionado o console.log() quando tudo acima já estiver sido executado.

Como a stack só executa uma função por vez, de acordo com o tamanho da função e o que será processado, isso irá ocupar mais tempo na stack, fazendo com que as próximas chamadas esperem mais tempo para serem executadas.
I/O - Operação bloqueante e não bloqueante
I/O se refere, principalmente, à interação com o disco do sistema e a integração com a libuv.
Operação bloqueante é a execução do código no processo do Node precisa esperar até que uma operação seja concluída. Isso acontece porque o event loop é incapaz de continuar executando alguma tarefa, enquanto uma operação bloqueante está sendo executada.
Todos os métodos I/O na biblioteca padrão do Node tem uma versão assíncrona, que, por definição, são não-bloqueantes, e aceitam funções de callback. Alguns métodos também têm suas versões bloqueantes, que possuem o sufixo Sync no nome. Para maiores Informações sobre I/O, acesse: I/O
Single-Thread
O Node é uma plataforma orientada a eventos, que utiliza o conceito de thread única para gerenciar a stack. Quem é single thread é o v8 do Google, responsável por rodar o código do Node, a stack faz parte do v8, ou seja, ela é single thread, que executa uma função de cada vez.
Multi-Threading
Para trabalhar com operações paralelas, e obter um ganho de desempenho, o Node e sua stack por si só são incapazes de resolver múltiplas operações ao mesmo tempo, por isso, ele conta com uma lib chamada de libuv, que é capaz de gerenciar processos em background de I/O assíncrono não bloqueantes.
Exemplo de uma função assíncrona sendo executada:
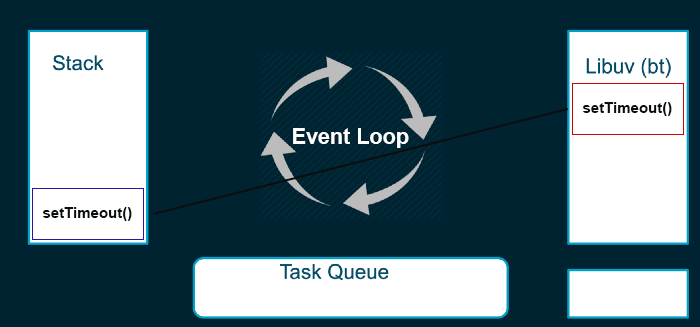
Nesse exemplo, a função setTimeout() é executada na stack e jogada para uma thread, enquanto ela vai sendo processada e administrada pela libuv. A stack continua executando as próximas funções e, quando terminar o processamento, a função de callback será adicionada na Task Queue para ser processada quando a stack estiver vazia.

Task queue
Algumas funções são enviadas para serem executadas em outra thread, permitindo que a stack siga para as próximas funções e não bloqueie nossa aplicação.
Essas funções que são enviadas para outra thread precisam ter um callback, que é uma função que será executada quando a função principal for finalizada.
Os callbacks aguardam a sua vez para serem executados na stack. Enquanto esperam, eles ficam em um lugar chamado de task queue. Sempre que a thread principal finalizar uma tarefa, o que significa que a stack estará vazia, uma nova tarefa é movida da task queue para a stack, onde será executada.
Aqui temos um exemplo para facilitar:

O Event Loop é responsável por buscar essas tarefas de background, e executá-las na stack.
Micro e macro tasks
O Event Loop é formado por macro tasks e micro tasks. As macro tasks que serão enfileiradas no background, e que quando forem processadas, terão um callback dentro da task queue que será chamado quando a stack estiver vazia. dentro de cada ciclo, o event loop irá executar primeiramente as micro tasks disponíveis. As micro tasks vão sendo processadas, até que a fila de microtask esteja esgotada, assim que todas as chamadas de micro tasks forem feitas, então no próximo ciclo, o callback da macro task que está na task queue será executado. Ou seja, dentro de um mesmo ciclo, as micro tasks, serão executadas antes das macro tasks.
Macro tasks
Vou citar alguns exemplos de funções que se comportam como macro tasks: setTimeout, I/O e setInterval.
Micro tasks
Alguns exemplos conhecidos de micro tasks são as promises e o process.nextTick. As micro tasks normalmente são tarefas que devem ser executadas rapidamente após alguma ação, ou realizar algo assíncrono sem a necessidade de inserir uma nova task na task queue.
Vamos tentar entender melhor com alguns exemplos, coloquei algumas anotações para facilitar o entendimento:

Ao executar o código acima, teremos o seguinte resultado de priorização:

Você deve estar se perguntando o porquê não está sendo executado em ordem, vou tentar explicar com as anotações que fiz no código.
[A]: Executado diretamente na stack, dessa forma ele é síncrono, então o restante do código irá aguardar o resultado para ser executado.
[B]: Enfileirado como uma tarefa futura, prioridade macro task, será executado apenas no próximo loop.
[C]: Enfileirado como uma tarefa futura, prioridade micro task, será executado imediatamente após todas as tarefas/tasks do loop atual e antes do próximo loop.
[D]: Executado diretamente na stack, dessa forma ele é síncrono, então o restante do código irá aguardar o resultado para ser executado.
Conclusão
Nesse artigo vimos o que é o Node e como ele funciona “por baixo dos panos”, espero que vocês tenham entendido com clareza e que essa visão ajude vocês a escreverem códigos melhores e de uma maneira que tire maior proveito desse funcionamento. Aconselho também a leitura complementar dos links de referências que irão facilitar o entendimento.
Links relacionados
https://nodejs.org/pt-br/docs/guides/blocking-vs-non-blocking/
https://imasters.com.br/front-end/node-js-o-que-e-esse-event-loop-afinal
https://fabiojanio.com/2020/03/12/introducao-ao-node-js-single-thread-event-loop-e-mercado/
https://oieduardorabelo.medium.com/javascript-microtasks-e-macrotasks-fac33016de4f
https://www.youtube.com/watch?v=8aGhZQkoFbQ
This content originally appeared on DEV Community and was authored by Leonardo de Sá
Leonardo de Sá | Sciencx (2021-09-17T23:18:44+00:00) Entendendo o Node.js e seu funcionamento. Retrieved from https://www.scien.cx/2021/09/17/entendendo-o-node-js-e-seu-funcionamento/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.