
This content originally appeared on DEV Community and was authored by Heiko Hotz

Happy new year, everyone! In 2021, the global Natural Language Processing (NLP) market size reached an estimated USD 21 Billion(!) and it is projected to grow to USD 127 Billion in 2028 at an estimated CAGR of 29.4%. To put these numbers into perspective: The estimated global revenue for AWS in 2021 is around USD 62 Billion.
Add in strategic initiatives like our partnership with Hugging Face and the continued efforts to improve our AI Language Services and it becomes clear that NLP is, and will be for a long time, one of the most important areas to cover within AWS.
In 2021 the NLP Domain has set out to successfully guide customers in their NLP journeys. We also have created resources and mechanisms to scale the field internally. In 2022 we will continue this effort by growing the NLP Domain, supporting NLP initiatives, and creating even more resources so that we as an organisation are prepared for the exciting NLP challenges to come.
NLP Customer Success Stories

Koo App Connects Millions of Voices in Their Preferred Language with AWS
When the social media revolution began, e-commerce sites mostly catered to English speakers, which left out a huge population of would-be participants. Koo, a microblogging platform based in India, noted the lack of inclusivity and made it their mission to create an app that is accessible to the entire spectrum of languages spoken in India. Koo leverages several AWS services, such as Amazon SageMaker, Aurora, EKS, and EC2 to serve millions of users on their platform.
AWS Helps Pfizer Accelerate Drug Development And Clinical Manufacturing
Also in December, AWS announced that it is working with Pfizer to create innovative, cloud-based solutions with the potential to improve how new medicines are developed, manufactured, and distributed for testing in clinical trials. To gain quick, secure access to the right information at the right time, Pfizer’s Pharmaceutical Sciences Small Molecules teams are working with AWS to develop a prototype system that can automatically extract, ingest, and process data from this documentation to help in the design of lab experiments. The prototype system is powered by Amazon Comprehend Medical (AWS’s HIPAA-eligible natural language processing (NLP) service to extract information from unstructured medical text accurately and quickly) and Amazon SageMaker, and uses Amazon Cognito to deliver secure user access control.
Updates on AWS Language Services
Double Bill: AWS announces post call analytics and live call analytics with Amazon AI Language Services.
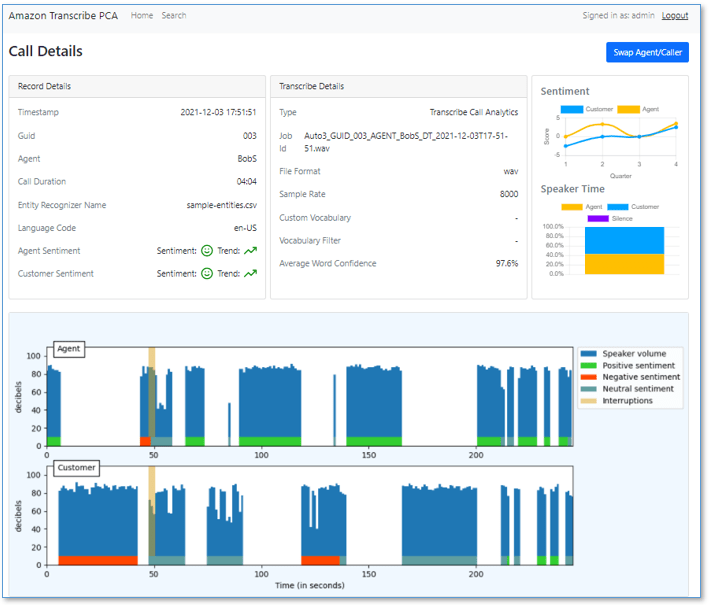
This is a huge step for AWS customers that need rich analytics capabilities to transcribe and extract insights from your contact centre communications at scale. Both functionalities were already available in Contact Lens for Amazon Connect, and now customers who don’t use Amazon Connect can use it in their existing contact centres.
Live transcriptions of F1 races using Amazon Transcribe
The Formula 1 (F1) live steaming service, F1 TV, has live automated closed captions in three different languages: English, Spanish, and French. For the 2021 season, FORMULA 1 has achieved another technological breakthrough, building a fully automated workflow to create closed captions in three languages and broadcasting to 85 territories using Amazon Transcribe.
Clinical text mining using the Amazon Comprehend Medical new SNOMED CT API
This blog post describes how to use a new feature to automatically standardize and link detected concepts to the SNOMED CT (Systematized Nomenclature of Medicine—Clinical Terms) ontology. It details how to use the new SNOMED CT API to link SNOMED CT codes to medical concepts (or entities) in natural written text that can then be used to accelerate research and clinical application building.
Support for extracting data from identity documents using Amazon Textract
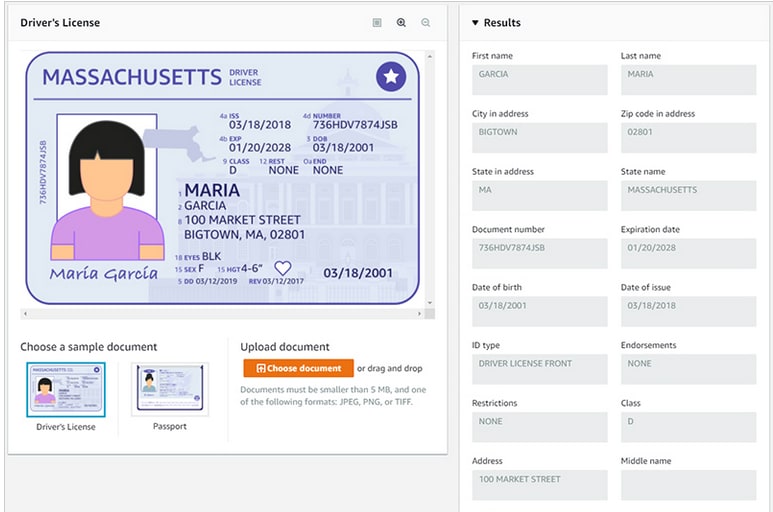
This blog post announces a new API to Amazon Textract called Analyze ID that will help you automatically extract information from identification documents, such as driver’s licenses and passports. Amazon Textract uses AI and ML technologies to extract information from identity documents, such as U.S. passports and driver’s licenses, without the need for templates or configuration. You can automatically extract specific information, such as date of expiry and date of birth, as well as intelligently identify and extract implied information, such as name and address.
Custom document enrichment in Amazon Kendra
Amazon Kendra customers can now enrich document metadata and content during the document ingestion process using custom document enrichment (CDE). Organizations often have large repositories of raw documents that can be improved for search by modifying content or adding metadata before indexing. So how does CDE help? By simplifying the process of creating, modifying, or deleting document metadata and content before they’re ingested into Amazon Kendra. This can include detecting entities from text, extracting text from images, transcribing audio and video, and more by creating custom logic or using services like Amazon Comprehend, Amazon Textract, Amazon Transcribe, Amazon Rekognition, and others.
Expedite conversation design with the automated chatbot designer in Amazon Lex
The automated chatbot designer expands the usability of Amazon Lex to the design phase. It uses machine learning (ML) to provide an initial bot design that you can then refine and launch conversational experiences faster. With the automated chatbot designer, Amazon Lex customers and partners get an easy and intuitive way of designing chatbots and can reduce bot design time from weeks to hours.
NLP on Amazon SageMaker
Build custom Amazon SageMaker PyTorch models for real-time handwriting text recognition
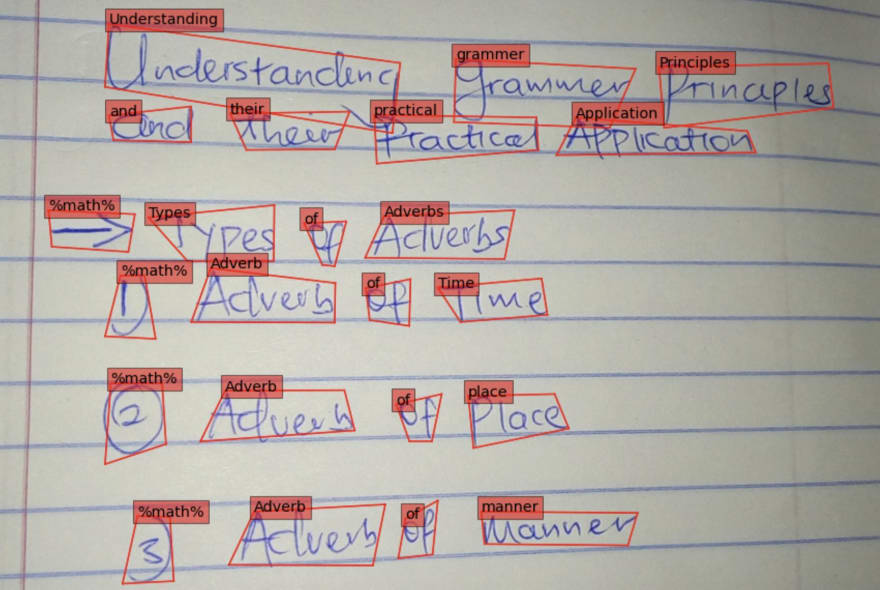
Unlike standard text recognition that can be trained on documents with typed content or synthetic datasets that are easy to generate and inexpensive to obtain, handwriting recognition (HWR) comes with many challenges. These challenges include variability in writing styles, low quality of old scanned documents, and collecting good quality labeled training datasets, which can be expensive or hard to collect. In this post, we share the processes, scripts, and best practices to develop a custom ML model in Amazon SageMaker that applies deep learning (DL) techniques based on the concept outlined in the paper GNHK: A Dataset for English Handwriting in the Wild to transcribe text in images of handwritten passages into strings.
Achieve 35% faster training with Hugging Face Deep Learning Containers on Amazon SageMaker
This post shows how to pretrain an NLP model (ALBERT) on Amazon SageMaker by using Hugging Face Deep Learning Container (DLC) and transformers library. We also demonstrate how a SageMaker distributed data parallel (SMDDP) library can provide up to a 35% faster training time compared with PyTorch’s distributed data parallel (DDP) library.
Amazon SageMaker Training Compiler can accelerate training by up to 50%
State-of-the-art NLP models consist of complex multi-layered neural networks with billions of parameters that can take thousands of GPU hours to train. Optimizing such models on training infrastructure requires extensive knowledge of DL and systems engineering; this is challenging even for narrow use cases. SageMaker Training Compiler is a capability of SageMaker that makes these hard-to-implement optimizations to reduce training time on GPU instances. The compiler optimizes DL models to accelerate training by more efficiently using SageMaker machine learning (ML) GPU instances.
Amazon SageMaker Serverless inference for intermittent usage patterns

Amazon SageMaker Serverless Inference is a purpose-built inference option that makes it easy for you to deploy and scale ML models. Serverless Inference is ideal for workloads which have idle periods between traffic spurts and can tolerate cold starts. Serverless endpoints automatically launch compute resources and scale them in and out depending on traffic, eliminating the need to choose instance types or manage scaling policies. This takes away the undifferentiated heavy lifting of selecting and managing servers. Serverless Inference integrates with AWS Lambda to offer you high availability, built-in fault tolerance and automatic scaling.
Community content
Setting up a text summarisation project on Amazon SageMaker
This tutorial serves as a practical guide for diving deep into text summarisation. It was born out of a customer engagement where the customer wanted to know how to go about setting up a text summarisation project. While there are many impressive demos on text summarisation out there, they are not well suited for actually experimenting with different models and hyperparameters. To do that, organisations need to set up their own experimentation pipeline. The tutorial is divided into the several steps to build up this pipeline:
- Using a no-ML “model” to establish a baseline
- Generating summaries with a zero-shot model
- Training a summarisation model
- Evaluating the trained model
Building a language models from scratch
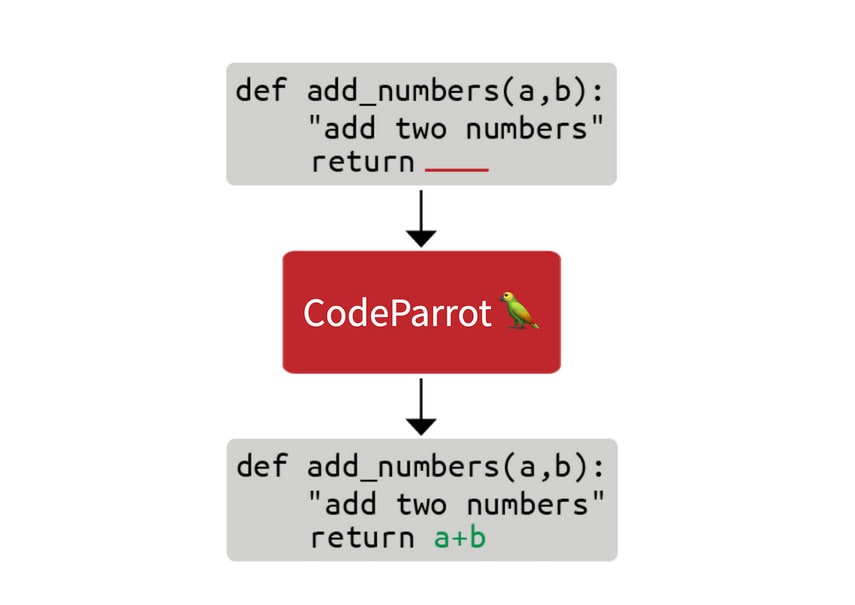
This blog post takes a look at what it takes to build the technology behind GitHub CoPilot, an application that provides suggestions to programmers as they code. In this step by step guide, we'll learn how to train a large GPT-2 model called CodeParrot, entirely from scratch. CodeParrot can auto-complete your Python code - give it a spin here.
A 2021 NLP Retrospective
Much has happened in the field of Natural Language Processing (NLP) in the past year and this blog post reflects on some of the NLP highlights of 2021.
Stay in touch with NLP on AWS
Our contact: aws-nlp@amazon.com
Email us about (1) your awesome project about NLP on AWS, (2) let us know which post in the newsletter helped your NLP journey, (3) other things that you want us to post on the newsletter. Talk to you soon.
This content originally appeared on DEV Community and was authored by Heiko Hotz
Heiko Hotz | Sciencx (2022-01-06T11:25:04+00:00) AWS – NLP Newsletter December 2021. Retrieved from https://www.scien.cx/2022/01/06/aws-nlp-newsletter-december-2021/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.