
This content originally appeared on DEV Community and was authored by Eric See
Introduction
The recent surge interest in data-driven application has led me to attempt to build a Data-Lake on the cloud. I have always been someone to do things myself and a fan of opensource aka DIY & Opensource guy. Data science is all about how people can use this collected data and make some “learning out of it”. I will cover supervised. unsupervised & Reinforce Learning in another post. There are 5 stages company actively use the data (Analytics Continuum):
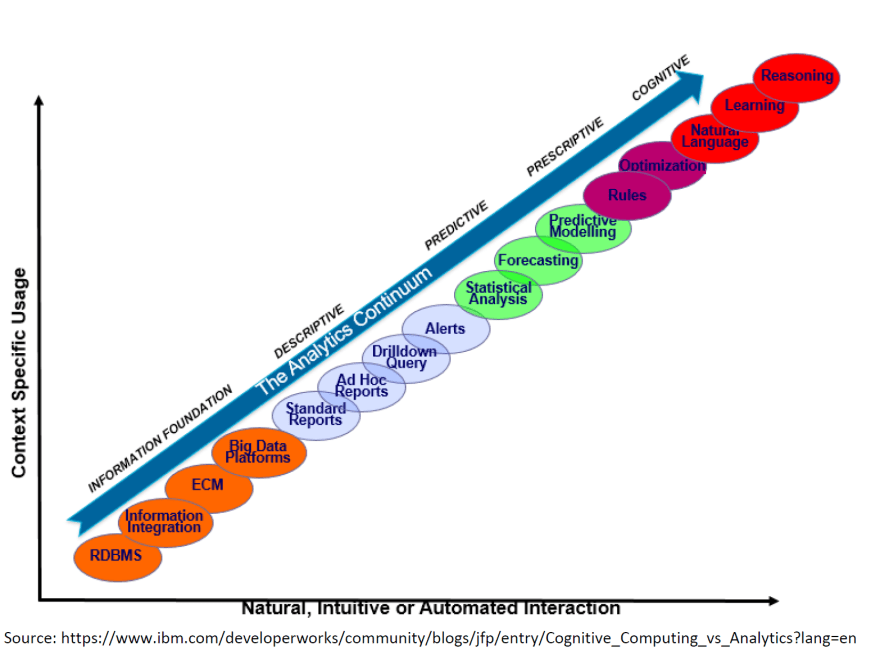
Don’t fret and lose sleep over this, data scientists are paid to do magic to bring use to the cognitive nirvana stage. Cognitive means machine behaving & thinking like human.
Data-Lake
This is what data-lake in a nutshell:
Zaloni describe it as:

or put it in simpler term:
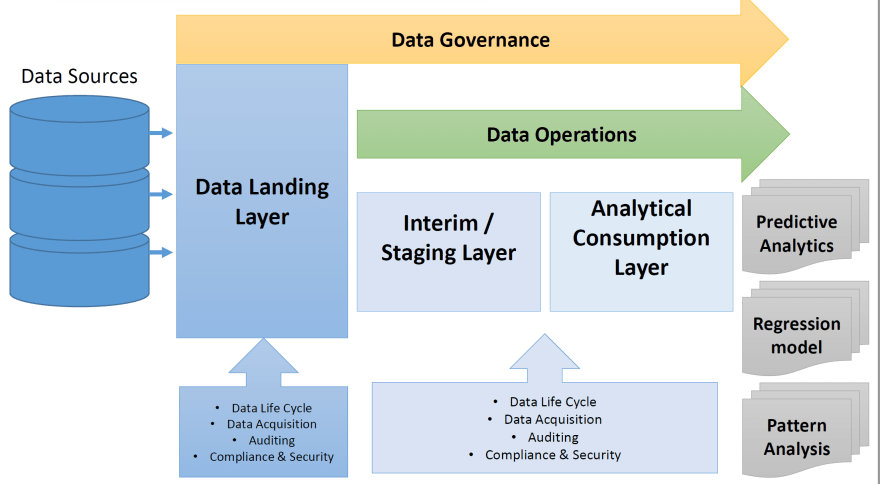
Data lifecycle: Ingestion, ETL, Modelling, & Data Publishing, Housekeeping & Retraining.
Ingestion
Install an Apache NIFI cluster in a Kubernetes cluster to ingest data from MQTT, pull data from API Endpoints. Additionally, an API Gateway is required for others to sink data. Data will be saved in STAGING zone. _STAGING _Zone can be implemented using persistent storage or database.ETL
You can install and use Apache Airflow to execute pre-populated python scripts before moving the data to the input of the Models. Again, Here we can store processed data in Document Store like Mongoor Graph-store Neo4J.Model
Model is a bunch of code taking inputs, apply mathematics and output the findings. Models can be implemented using Python Scikit -Learn and Apache Spark (graphx). Output from these models can be classified into Predictive Analytics, Regression Model, Pattern Analysis. All these are basically mathematics. Mathematics are effectively: arithmetic, calculus and geometry (2d/3d). Run these modelling codes inside the Kubernetes Cluster.Data Publishing
Effectively, the data output from the models can be used for other vendors or microservices. Data is published to Apache Kafka & persisted in a self-managed Mongo.
Insight Data can be subscribed from endpoints using API Gateway. Each customer will be given a legitimate access key to access the endpoints. Data also can be displayed in dashboard like Kibana, make available to customer. We can setup a ELK stack in Kubernetes Cluster or you can subscribed to service like AWS OpenSearch. Data output can be made to ran through workflows for checks, for instance sending email alerts to stakeholder if abnormality is found. It makes sense to use native services (AWS SES & AWS Lambda).Housekeeping
Data>Retaining period have to be cleared with scripts running in cron-jobs or AWS Lambda.Retraining
Raw data coming in have to be stores somewhere for retraining the models. We can use storage like EBS, EFS, Blob Storage in this context. For retraining and redeployment (CI/CD) of models, we can use tools like Apache MLFlow.
What’s next
Data Governance
After finishing the base pipeline, the next phase is to implement data governance. We can use Opensource Apache Altas or _Talend _ (Enterprise) here.Data Warehouse
Output from data lake can then be store in structured data warehouse (AWS Redshift) and create data-mart using Snowflake that is available in marketplace.
This content originally appeared on DEV Community and was authored by Eric See
Eric See | Sciencx (2022-03-26T05:04:00+00:00) How to create a DIY Inexpensive Cloud Data Lake. Retrieved from https://www.scien.cx/2022/03/26/how-to-create-a-diy-inexpensive-cloud-data-lake/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.