
This content originally appeared on Level Up Coding - Medium and was authored by Pan Cretan
Without care caching can do more harm than good!

The purpose of this article is to give a quick introduction to PySpark query optimisation and physical planning. Through the use of a simple example we look into the physical plan and how this is affected by caching or use of checkpoints. This article will not make you an expert but it can serve as a starting point to readers less familiar with this critical aspect of data processing in Spark. There are many excellent articles in Medium such as this if you already know the fundamentals.
The examples have been run on a locally deployed Spark environment (version 3.2.1). The spark session has been created with
that allocated 2GiB (that is 2 gibibytes, i.e. 2³⁰ bytes) of RAM and 4 cores. We also set up a directory where checkpoint information can be saved. We can see in the Spark UI (localhost:4040)
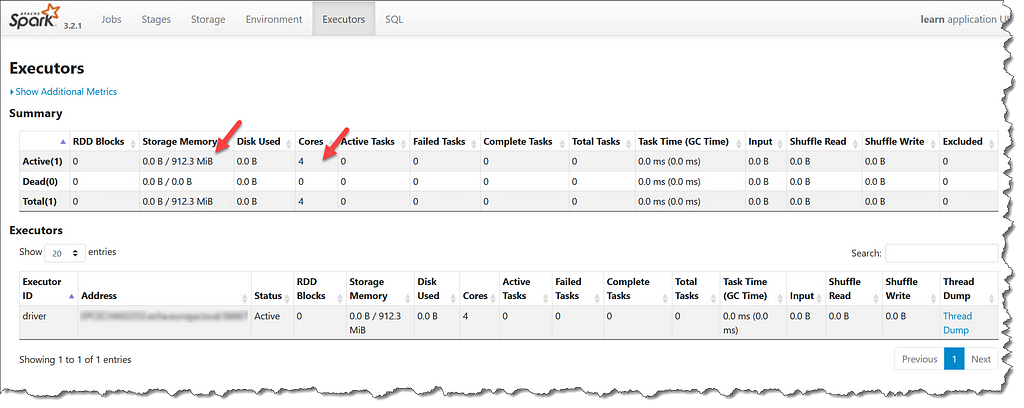
that from the 2 GiB of memory, we have available roughly 900 MiB for operational and storage memory . The operational memory is used for data transformations and the storage memory for data. By default the split between operational and storage memory is equal (this can be changed with spark.memory.storageFraction) . This is plenty of memory for our numerical experiments to ensure that no spilling to disk occurs.
The starting dataset is generated with pandas and numpy and has 100 000 rows. Once created we convert it to a PySpark data frame and replicate it 100 times. This gives us 10 million rows that is large enough for the calculations to take a few seconds.
The Spark data frame is cached fully on memory where it consumes roughly 100 MiB
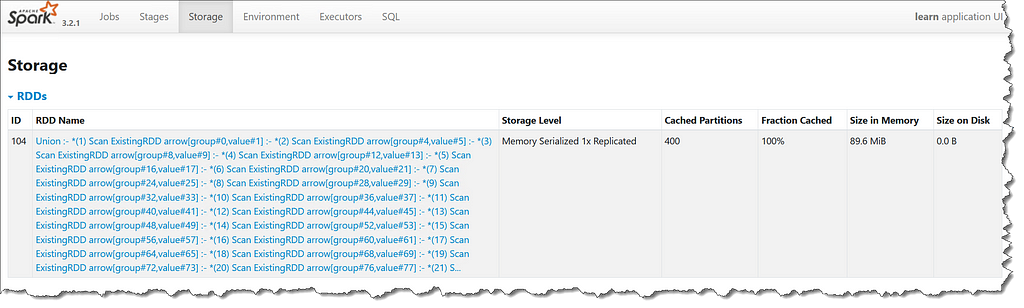
This means that all operations from now on have the starting data frame in memory, i.e. none of the union operations will be repeated. The data frame has a string column, called group, that takes five values and a double column, called value, that contains uniformly random numbers in the range [0.0, 10.0).
Experiment 1: Looking at the physical plan for an aggregation operation
The first numerical experiment uses the string column for grouping and computes the average of the second column
We time the execution with %timeit -r10 sol1(show=False) to obtain 3.71 s ± 199 ms per loop (mean ± std. dev. of 10 runs, 1 loop each). Please note the data transformation was poorly written on purpose to tease Spark. The second filter applies to the grouping variable and hence it should have been specified prior to the aggregation. The res.count() function is generally a good option for benchmarking because it performs the whole transformation compared to, for example, res.show() that may only (cleverly) trim the transformation to what is required.
If we execute once more the function with sol1()to see the physical plan and the output we obtain
Looking at the physical plan, and reading it in the usual fashion from bottom up, we see that Spark has been clever. The two filters were pooled together and applied before the aggregation. In fact, Spark performed a pre-aggregation before the exchange to save time by not exchanging the whole dataset but pre-aggregated partitions. This is supercool and shows how much work Spark is doing behind the scenes.
Experiment 2: Effect of using a checkpoint
What would happen if we squeeze a checkpoint in the middle? Lets try this using
and time it using %timeit -r10 sol2(show=False) to obtain 4.91 s ± 127 ms per loop (mean ± std. dev. of 10 runs, 1 loop each). The execution time increased by roughly 30% compared to the first numerical experiment. The resulting data frame is of course the same, but the physical plans (now two) have changed
The effect of the checkpoint is to break the logical plan into two. Now the second filter happens after the exchange and this results in longer execution times. Checkpoints can be useful in iterative algorithms and need to be used, but they need care. We are experimenting with the optimiser and we should have a good reason to do so.
Experiment 3: Effect of caching
In the third and last numerical experiment we see how caching of the intermediate data frame affects the execution time. Before doing so we first see how much time caching and clearing of cache takes by using a modified version of function sol1()
The output is again unaffected. The physical plan is also the same as in the first numerical experiment because we clear the cache prior to having the chance of using it. The execution time obtained with%timeit -r10 sol1_cache_overhead(show=False)is very similar too at 3.86 s ± 138 ms per loop (mean ± std. dev. of 10 runs, 1 loop each). From this we can conclude that the cost of caching on this occasion is negligible that is understandable by the fact that the caching happens after the aggregation. Now lets see what happens when we use caching for real
Timing the execution with %timeit -r10 sol3(show=False) gives 5.77 s ± 279 ms per loop (mean ± std. dev. of 10 runs, 1 loop each), i.e. we see an increase in execution time compared to the first numerical experiment. Looking at the physical plan we once more see that the two filters are not pooled together because the cache prevents the optimiser from pursuing this option
Caching can have more detrimental effects than disturbing the optimiser. It takes memory resources and in the end it may lead to longer execution times compared to computing the cached data frame again. Caching can be beneficial when the data frame is to be used several times, that is often the case when experimenting using the REPL. A second use case is when a machine learning model is trained, in which case the training set needs to be used repeatedly.
Tuning performance of Spark applications is an advanced topic. Spark optimises the data processing flow and generally works well out of the box. For most users interventions can be detrimental. As a data analyst I am not so experienced and I would seek the advice of a data engineer in the same way I would typically seek advice if I need to use optimiser hints when querying a database.
An Introduction to PySpark Optimisation, Physical Plan and Caching was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Pan Cretan
Pan Cretan | Sciencx (2022-06-05T14:34:52+00:00) An Introduction to PySpark Optimisation, Physical Plan and Caching. Retrieved from https://www.scien.cx/2022/06/05/an-introduction-to-pyspark-optimisation-physical-plan-and-caching/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.