
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Franck Pachot
You can use a SQL database to implement a queue for event-driven design. And you can use a Distributed SQL database to keep it scalable. Here is an example on YugabyteDB (Open Source, PostgreSQL-compatible).
First, as I see you asking why using a SQL database and not a purpose-built queuing service, let me give a reason for that. You rarely dequeue just for the fun of it, like I'm doing here. In real life, you have a queue of jobs to process, and their processing will probably update some database. Having the queue in the database avoids remote service calls and keeps this transactional: if the job processing doesn't complete, it stays on the queue, where you can also update a status. You sill have the advantages of asynchronous processing, without adding more complexity. You want to de-couple to be resilient if one component fails? With a Distributed SQL database, all this continues to work when a node is down, resilient to failure.
Range sharded queue table
Here is my job queue table:
create extension if not exists pgcrypto;
create table job_queue (
primary key(id asc),
id text default gen_random_uuid(),
payload jsonb
) split at values (
('20000000-0000-0000-0000-000000000000'),
('40000000-0000-0000-0000-000000000000'),
('60000000-0000-0000-0000-000000000000'),
('80000000-0000-0000-0000-000000000000'),
('a0000000-0000-0000-0000-000000000000'),
('c0000000-0000-0000-0000-000000000000'),
('e0000000-0000-0000-0000-000000000000')
) ;
I use only an id as the primary key, which I generate from a UUID (to be unique and easy) but as a text (because I'll define ranges). Generally, you should store an UUID as uuid datatype, but this is an exception.
I define range sharding (asc) and split it into 8 tablets here.
Fanout view to distribute reads and writes
My goal is to pick-up an job id, to lock it, process its payload, and delete it from the queue. I want to process multiple ones in parallel, then I'll select ... for update skip lock so that it takes the first one not being processed by another thread. To distribute this pick-up, I want to start from a random id. The following view returns all rows, but starting at a random place because the UNION ALL branches are concatenated in order:
create or replace view job_fanout as
with fanout as (
select gen_random_uuid()::text id
),
queue as (
select * from job_queue where id >= (select fanout.id from fanout)
union all
select * from job_queue where id < (select fanout.id from fanout)
)
select * from queue;
I'll query this with limit 1 so that most of the time only the first branch is executed. The union all is there to wrap around if we are at the end if the id range.
Dequeuing with FOR UPDATE SKIP LOCKED LIMIT 1
Each thread will pick-up one id from this queue, process it, and remove it from the queue:
cat > /tmp/dequeue.sql <<'CAT'
begin transaction isolation level read committed;
select id from job_fanout for update skip locked limit 1
\gset
select pg_sleep(1);
delete from job_queue where id=':id';
commit;
CAT
To simulate a long processing, I pg_sleep(1) so that each execution takes on second. My goal is that I can run multiple threads concurrently, and each will not take more than one second because there's no contention on the de-queuing mechanism.
Test data
For my test, I insert one million jobs:
insert into job_queue(payload)
select to_jsonb(row( generate_series(1,1000000) , now() ));
Check the scalability
I check, with my ybwr.sql script, that reading one row from the job_fanout view reads from one table only:
\! curl -s https://raw.githubusercontent.com/FranckPachot/ybdemo/main/docker/yb-lab/client/ybwr.sql | grep -v '\watch' > ybwr.sql
\i ybwr.sql
yugabyte=> execute snap_reset;
ybwr metrics
--------------
(0 rows)
yugabyte=> select id from job_fanout for update skip locked limit 1;
id
--------------------------------------
99bd0f77-a1be-4182-85c4-952b947fd489
(1 row)
yugabyte=> execute snap_table;
rocksdb_seek | rocksdb_next | rocksdb_insert | dbname / relname / tserver / tabletid / leader
--------------+--------------+----------------+-------------------------------------------------------------------------------------------------------------------------------------------------
1 | | | yugabyte job_queue range: [DocKey([], [80000000-0000-0000-0000-000000000000]), DocKey([], [a0000000-0000-0000-0000-000000000000])) L 10.0.0.141
(1 row)
This has read 99bd0f77-a1be-4182-85c4-952b947fd489 from the tablet that ranges from 80000000-0000-0000-0000-000000000000 to a0000000-0000-0000-0000-000000000000 with only one seek() into the LSM-Tree. Multiple threads would have read different tablets, seek to different place in each tablet, and if the row was already locked by a concurrent thread, would have read the next one. This is the most efficient access to a random row.
The execution plan shows this as well:
yugabyte=# explain (costs off, analyze) select id from job_fanout for update skip locked limit 1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
--------
Limit (actual time=4.004..4.006 rows=1 loops=1)
-> LockRows (actual time=4.004..4.004 rows=1 loops=1)
-> Subquery Scan on job_fanout (actual time=4.003..4.003 rows=1 loops=1)
-> CTE Scan on queue (actual time=3.999..3.999 rows=1 loops=1)
CTE fanout
-> Result (actual time=0.016..0.016 rows=1 loops=1)
CTE queue
-> Append (actual time=3.997..3.997 rows=1 loops=1)
-> Index Scan using job_queue_pkey on job_queue (actual time=3.997..3.997 rows=1 loops=1)
Index Cond: (id >= $1)
InitPlan 2 (returns $1)
-> CTE Scan on fanout (actual time=0.018..0.019 rows=1 loops=1)
-> Index Scan using job_queue_pkey on job_queue job_queue_1 (never executed)
Index Cond: (id < $2)
InitPlan 3 (returns $2)
-> CTE Scan on fanout fanout_1 (never executed)
Planning Time: 0.185 ms
Execution Time: 4.068 ms
Peak Memory Usage: 96 kB
(19 rows)
Read committed
I check the effective isolation level to be sure that I've started YugabyteDB with --yb_enable_read_committed_isolation=true:
yugabyte=# show yb_effective_transaction_isolation_level;
yb_effective_transaction_isolation_level
------------------------------------------
read committed
(1 row)
With 500 threads processing each job in 1 second
I'll run the dequeue.sql script I've created above, from pgbench to run it from 500 threads, for 1000 seconds. As each job takes 1 second (pg_sleep(1)), I can expect that it processes 500000 jobs. Of course, I'm saturating my small client VM here and it will take longer but my goal is to be sure that the average latency is not far from one second.
pgbench -T 1000 -c 500 -nf /tmp/dequeue
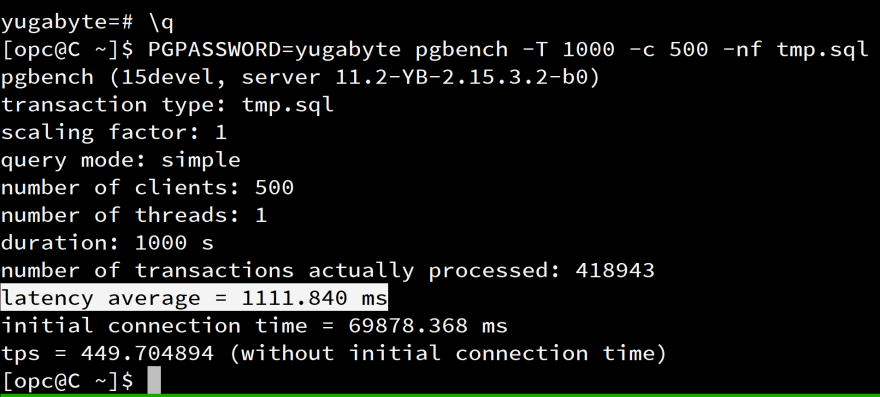
418943 have been processed with an average of 1.1 seconds which shows the scalability: dequeuing from 500 threads did not increase the response time.
With 15 threads processing the SELECT FOR UPDATE
The remaining jobs (1000000-418943=581057) can be processed from 15 threads taking 38783 job each. Here it doesn't matter because I'll run that without pg_sleep() and without delete to verify the scalability of the SELECT FOR UPDATE only.
cat > /tmp/dequeue.sql <<'CAT'
begin transaction isolation level read committed;
select id from job_fanout for update skip locked limit 1;
commit;
CAT
pgbench -t 38783 -c 15 -nf /tmp/dequeue.sql
While this is running, I can check that read operations are distributed:

On this cluster, I locked 1500 transactions per second staying at single-digit latency (9.9 milliseconds):
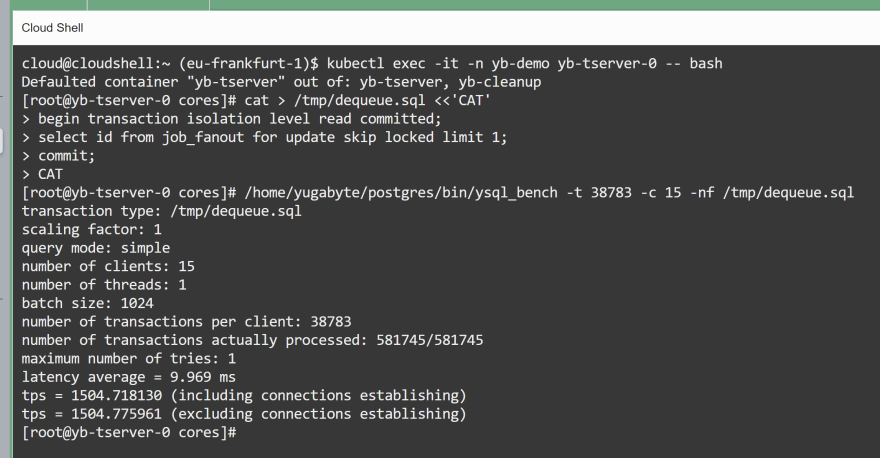
You can run the same with the DELETE statement and see that all jobs are processed without "row not found" error, and no retries.
This solution has the advantage that the fan-out mechanism is only declared in a view, and the scalability controlled by the tablet splitting, which can be changed online. The application just dequeues without the need to provide a bucket number. I used a UUID here but the same can be done with a composite primary key where the first column is the fan-out number and the other a generated number.
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Franck Pachot
Franck Pachot | Sciencx (2022-12-02T15:49:46+00:00) Scalable Job Queue in SQL (YugabyteDB). Retrieved from https://www.scien.cx/2022/12/02/scalable-job-queue-in-sql-yugabytedb/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.