
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Srce Cde
S3 service is used to store a variety of data for various use cases. Ideally, when there is a requirement to access the data stored as an object, the object will be accessed as a whole entity. But what if you want to retrieve the subset of data from the large object? In this case, the S3 Select feature can be leveraged.

S3 select allows you to execute SQL queries to filter the content and retrieve the subset of data on CSV, JSON or Apache Parquet files located in the S3 bucket. S3 select also works with files that are compressed with GZIP and BZIP2. The output format of the SELECT statement is limited to CSV with a custom delimiter & JSON. While the SQL query is executed in the console, the amount of data returned is limited to 40 MB.
For example, an organization is providing a service with a subscription model. Now, every month the updated data of the customer get stored in S3 with subscription status in CSV form. And you have to pull the data of the customers who have canceled their subscriptions and take some action accordingly.
In an ideal scenario, you will download the whole file/object, filter it and work on it. While you download or access the whole entity then you end up paying for more data transfer costs for the data which you will anyways filter it. Additional effort & time will go into data filters and additional storage.
With S3 select you can query the subset of data that you actually need. Hence, reduced data transfer costs, faster retrieval, and less effort & time go into data filtering.
Above is one of the very simple use cases that we discussed. As a next step, let’s query the object via the S3 console for the demo.
Hands-On
I have this setup where I have a customer (CSV) file in one of my S3 buckets.

The CSV file contains some random data like CustomerID, Genre, Age Annual_Income, Spending_Score, and subscription.

Now, let’s say we want to fetch the data where the subscription status of the customer is FALSE and the spending score is greater than 50. To query the data using S3 Select, select the CSV file → Actions → Query with S3 Select
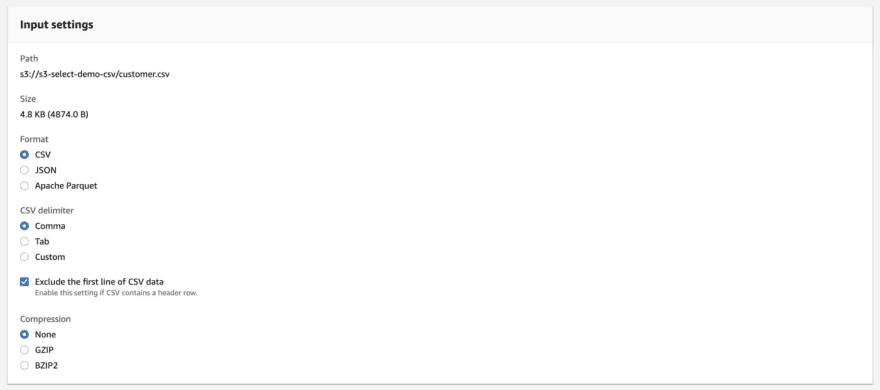
In the next screen, configure the Input settings like Format of the input file (which is CSV in my case), CSV delimiter & Compression if any. If the CSV file contains the header then check the Exclude the first line of CSV data
Under SQL query, write the SQL query in the editor. Here, we want to fetch the data where the subscription status of the customer is False and the spending score is greater than 50. For that, write the below query and click on Run SQL query
SELECT * FROM s3object s WHERE CAST(s.Spending_Score as INTEGER) > 50 AND s.subscription = ‘False’

For a detailed step-by-step tutorial and the implementation please refer to the below video.
If you have any questions, comments, or feedback then please leave them below. Subscribe to my channel for more.
References
This content originally appeared on DEV Community 👩💻👨💻 and was authored by Srce Cde
Srce Cde | Sciencx (2023-01-18T14:45:08+00:00) SELECT * FROM S3 | Query data via S3 Select. Retrieved from https://www.scien.cx/2023/01/18/select-from-s3-query-data-via-s3-select/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.