
This content originally appeared on Level Up Coding - Medium and was authored by Yeyu Huang
Use these frameworks to empower your machine-learning work

“Feature Engineering” refers to the use of domain knowledge and existing data to create new features for use in machine learning algorithms.
- Features — Information extracted from the data that is useful for outcome prediction.
- Feature Engineering — The process of processing data using professional background knowledge and skills so that features can play a better role in machine learning algorithms.
There is a popular saying in the industry: data and feature engineering determine the upper limit of the model, and the improved algorithm is only approaching this upper limit.
Feature engineering aims to improve the overall performance of machine learning models and generate input datasets that are most suitable for machine learning algorithms.
Automated Feature Engineering
In many production projects, feature engineering is done manually, and it relies on prior domain knowledge, intuition, and data manipulation. The whole process is very time-consuming, and the whole process needs to be completed again after the scene or data is changed. And “automated feature engineering” hopes to automatically generate a large number of candidate features for data set processing to help data scientists and engineers, and can select the most useful of these features for further processing and training.
Automated feature engineering is a meaningful technology that allows data scientists to spend more time on other aspects of machine learning, thereby improving work efficiency and effectiveness.
In this article, I will show you 4 popular Python libraries for automated feature engineering that every data scientist should be familiar with in this year.
1. Featuretools
To better dive into Featuretools, we need to understand below three key components:
- Entities
- Deep Feature Synthesis (DFS)
- Feature primitives
In Featuretools, we use Entity to include the contents of the original Pandas DataFrame, and EntitySet is composed of different Entities.
The core of Featuretools is Deep Feature Synthesis (DFS), which is a feature engineering method that can build new features from single or multiple Dataframes.
DFS creates features from the Feature primitives specified on the EntitySet. For example, the mean function in primitives will calculate the mean of variables when aggregated.
a) Data Preparation
Download and install the Featuretools by pip:
$ pip install featuretools
Run the following code from official demo:
import featuretools as ft
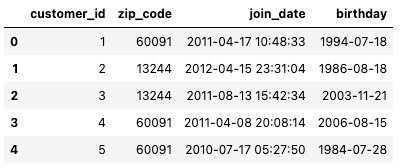
data = ft.demo.load_mock_customer()
customers_df = data["customers"]
customers_df
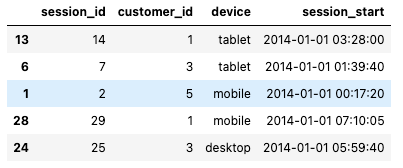
sessions_df = data["sessions"]
sessions_df.sample(5)
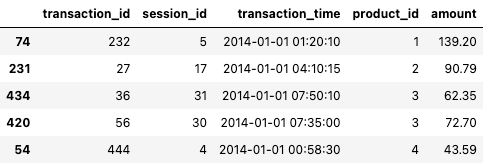
transactions_df = data["transactions"]
transactions_df.sample(5)
Below we specify a dictionary containing each Dataframe in the dataset. If the dataset has an “id” column, we pass it along with the DataFrames, as shown in the figure below.
dataframes = {
"customers": (customers_df, "customer_id"),
"sessions": (sessions_df, "session_id", "session_start"),
"transactions": (transactions_df, "transaction_id", "transaction_time"),
}Next, we define the connections between the Dataframes. In this example we have two relationships:
relationships = [
("sessions", "session_id", "transactions", "session_id"),
("customers", "customer_id", "sessions", "customer_id"),
]
b) Deep Feature Synthesis
Next, we can generate features through DFS, which requires three basic inputs: “DataFrames”, “Relationship list” and “Target DataFrame name”:
feature_matrix_customers, features_defs = ft.dfs(
dataframes=dataframes,
relationships=relationships,
target_dataframe_name="customers",
)
feature_matrix_customers
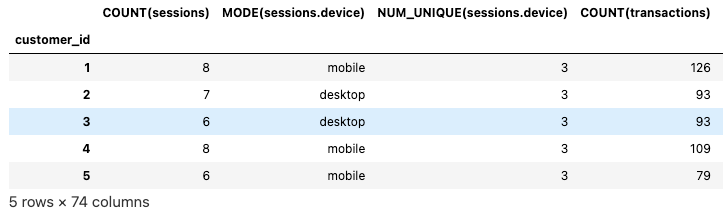
we can also use sessions as the target Dataframe to build new features.
feature_matrix_sessions, features_defs = ft.dfs( dataframes=dataframes, relationships=relationships, target_dataframe_name="sessions"
)
feature_matrix_sessions.head(5)
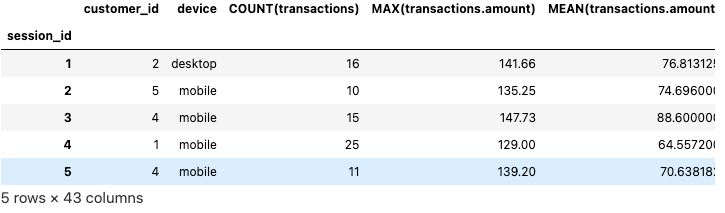
c) Visualized Output of Features
Featuretools can not only complete automatic feature generation, but it can also visualize the generated features and explain how Featuretools generated them.
feature = features_defs[18]
feature
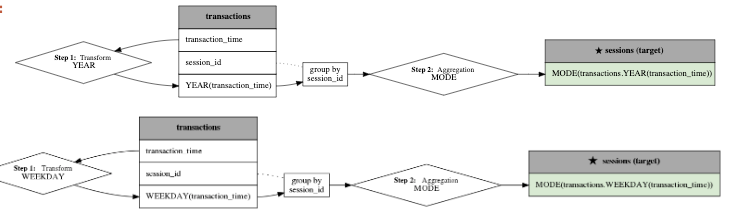
Please find more detailed information on its official website.
2. TSFresh
TSFresh is an open-source Python library with powerful time series data feature extraction functions. It applies typical algorithms of statistics, time series analysis, signal processing, and nonlinear dynamics along with reliable feature selection methods to complete time series feature extraction.
TSFresh automatically extracts 100 features from the time series. These features describe basic factors from the time series, such as the number of peaks, and average or maximum values, or more complex factors, such as time-reversed symmetric statistics.
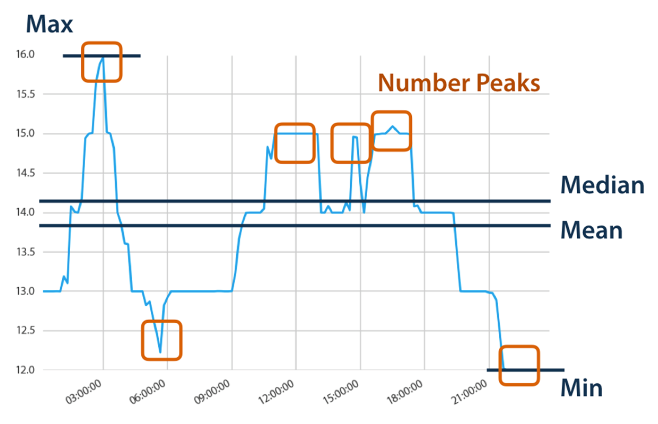
Following its documentation, you can easily test its performance by below codes with example data:
$ pip install tsfresh
# example data download
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
timeseries, y = load_robot_execution_failures()
# feature extraction
from tsfresh import extract_features
extracted_features = extract_features(timeseries, column_id="id", column_sort="time")
Please find more detailed information on its official website.
3. Featurewiz
Featurewiz is another very powerful library of automated feature engineering tools that combines two different techniques that work together to help find the best features:
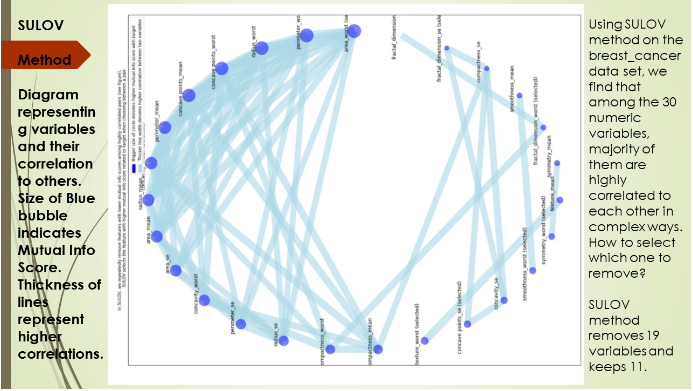
a) SULOV
Searching for the uncorrelated list of variables (SULOV):
This method searches the uncorrelated list of variables to identify valid variable pairs, it considers the variable pair with the lowest correlation and maximum MIS (Mutual Information Score) rating for further processing.
b) Recursive XGBoost
The variables identified in SULOV in the previous step are recursively passed to XGBoost, and the features most relevant to the target column are selected through XGBoost, combined, and added as new features, and this process is iterated until all valid features are generated.

A simple code demo is as below:
from featurewiz import FeatureWiz
features = FeatureWiz(corr_limit=0.70, feature_engg='', category_encoders='', dask_xgboost_flag=False, nrows=None, verbose=2)
X_train_selected = features.fit_transform(X_train, y_train)
X_test_selected = features.transform(X_test)
features.features # the selected feature list #
# automated feature generation
import featurewiz as FW
outputs = FW.featurewiz(dataname=train, target=target, corr_limit=0.70, verbose=2, sep=',',
header=0, test_data='',feature_engg='', category_encoders='',
dask_xgboost_flag=False, nrows=None)
Please find more detailed information on its official website.
4) PyCaret
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that accelerates experimentation cycles and increases productivity.
Unlike the other frameworks in this article, PyCaret is not a dedicated automated feature engineering library, but it includes functionality for automatic feature generation.
Simple code on its internal example data:
$ pip install pycaret
# load dataset
from pycaret.datasets import get_data
insurance = get_data('insurance')
# setup
from pycaret.regression import *
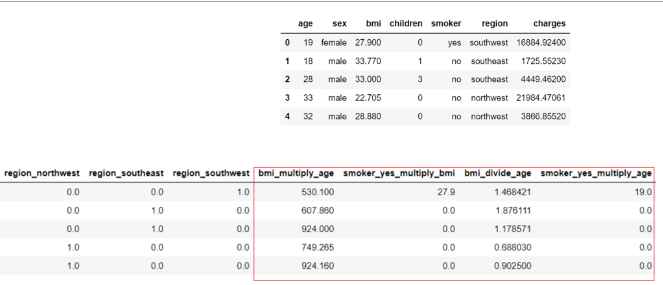
reg1 = setup(data = insurance, target = 'charges', feature_interaction = True, feature_ratio = True)
The below table contains the features that were generated automatically:
That’s it.
Hope you find something useful in this article, thanks for reading!
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
4 Python Libraries for Automated Feature Engineering That You Should Use in 2023 was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Yeyu Huang
Yeyu Huang | Sciencx (2023-01-23T02:18:54+00:00) 4 Python Libraries for Automated Feature Engineering That You Should Use in 2023. Retrieved from https://www.scien.cx/2023/01/23/4-python-libraries-for-automated-feature-engineering-that-you-should-use-in-2023/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.