
This content originally appeared on HackerNoon and was authored by Shrinivasan Sankar
Anthropic, the company behind the Claude series of models, has released Claude 3.5 Sonnet. It comes at a time when we all have accepted GPT-4o to be the default best model for the majority of tasks like reasoning, summarization, etc. Anthropic makes the bold claim that their model sets the new “industry standard” for intelligence.
Additionally, it's available for free on claude.ai if you wish to give it a spin. So, we got excited and wanted to test the model and compare it against GPT-4o. This article starts with an overview of the features released with Claude 3.5 and tests it against GPT-4o on code generation, as well as logical and mathematical reasoning tasks.
Main Features
The model comes with three main features or novelties that make them claim that it beats GPT-4o in most tasks.
Improved vision tasks. The model boasts state-of-the-art performance on 4 out of 5 vision tasks as per their published results below.
2x speed. Compared to GPT-4o or its own predecessors like Claude Opus, Claude Sonnet boasts of 2X generation speed.
Artifacts — a new UI for tasks like code generation and animation.
Let's dive deeper into the features and compare them with the long-reigning King of LLMs, GPT-4o.
Getting Started
To get started we have to be logged into the claude.ai website and enable the artifacts feature. As it's an experimental feature, we need to enable it. We have to go under feature preview and enable Artifacts from there as shown below.
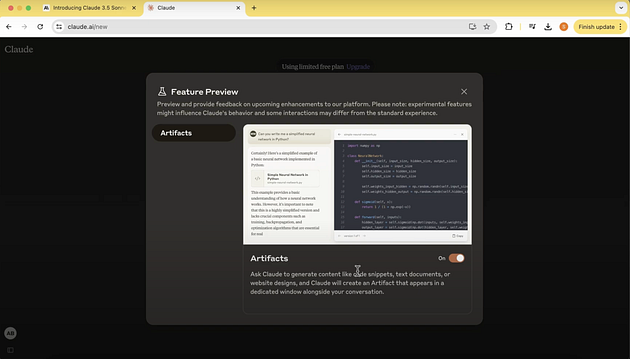
Once enabled, the model will show a dedicated window on the side for tasks that need them like coding or animations.
Vision Tasks — Visual Reasoning
To test the improved visual reasoning ability, we upload the below two plots to the Claude Sonnet model and asked the question, “What can you make out from this data?”.
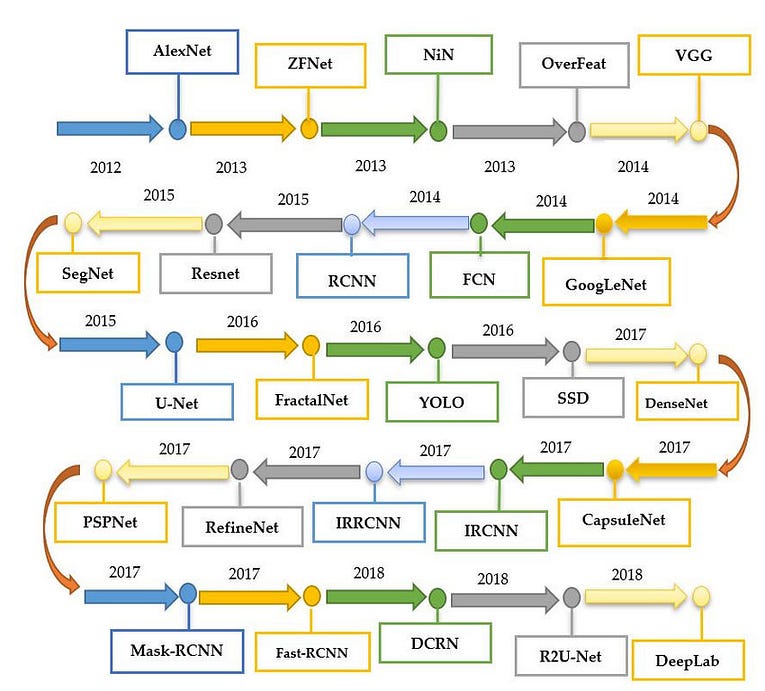
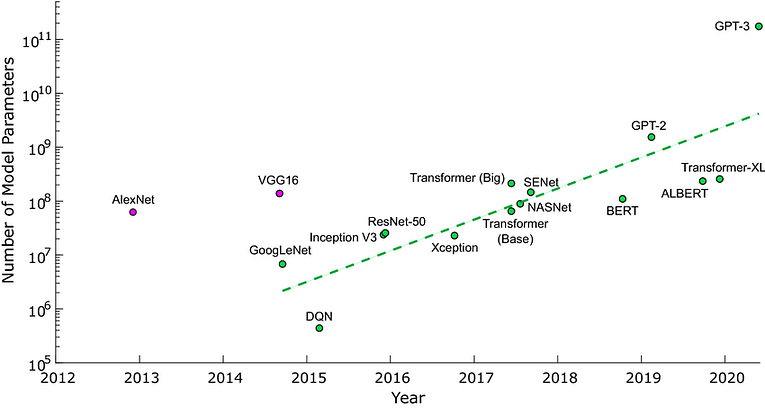
Plots as images for testing visual reasoning
The response from Claude Sonnet was astounding. It precisely summarised deep learning progress saying, “This data illustrates rapid progress in deep learning architectures and model scaling, showing a trend towards larger, more powerful models”. We got a similar response from GPT-4o as well. So, to get a better understanding of which is better, we started to compare both the models systematically in four tasks — coding, coding with UI, logical reasoning, and Math reasoning.
Versus GPT-4o — Which is best?
Now that we have seen an overview let's dive deep and take the model for a ride. Let's test for code generation, logical reasoning, and mathematical reasoning.
Code Generation
For code generation, I am going to ask both models to generate code for playing the well-known Sudoku game. I prompted both the models with the exact prompt, “write python code to play the sudoku game.” With this prompt, both Claude 3.5 and GPT-4o generate code with which we can interact only from the command prompt. This is expected as we did not specify how to generate UI code. Some initial observations:
- Both models churn out bug-free code.
- Claude generates code with the feature to choose the difficulty level. But GPT-4o doesn’t!
- With the speed of code generation, Claude beats GPT-4o without a doubt
- GPT-4o tends to generate code with unnecessary packages
Code Generation with UI
As interacting with the command prompt is not for everyone, I wanted the models to generate code with UI. For this, I modified the prompt to, “write code to play a sudoku game”. This time, I removed “python” from the prompt as I felt that it would prompt it to produce just the backend code. As expected, Claude 3.5 did produce a functional UI this time as below. Though the UI was not completely robust and appealing, it was functional.

But GPT-4o, unfortunately, did not produce a similar UI. It still generated code with an interactive command prompt.
Puzzle 1 — Logical Reasoning
For the first puzzle, I asked the below question:
Jane went to visit Jill. Jill is Jane’s only husband’s mother-in-law’s only husband’s only daughter’s only daughter. what relation is Jane to Jill?
Both the models came up with a sequence of reasoning steps and answered the question correctly. So it has to be a tie between Claude 3.5 and GPT-4o in this case.
Puzzle 2 — Logical Reasoning
For the second puzzle, I asked the below question:
Which of the words is least like the others. The difference has nothing to do with vowels, consonants or syllables. MORE, PAIRS, ETCHERS, ZIPPER\
For this, both the models came up with different logical reasoning steps to come up with different answers. Claude reasoned that zipper is the only word that can function as both a noun and a verb. But others are either just nouns or adjectives. So, it identified ZIPPER as the answer. GPT-4o, on the other hand, identified MORE reasoning that it's not a concrete object or a specific type of person.
All this indicates that we need to make the prompt more specific thereby leading to a tie in this case.
Puzzle 3 — Math reasoning
Let's move on to a well-known visual reasoning puzzle that can be calculated by a formula. So I gave the below figure along with the below prompt as input to both models.
The below 3 circles all have blue dots on their circumference which are connected by straight lines. The first circle has two blue dots separating it into two regions. Given a circle with 7 dots place anywhere on its circumference, what is the maximum number of regions the circle can be divided into?
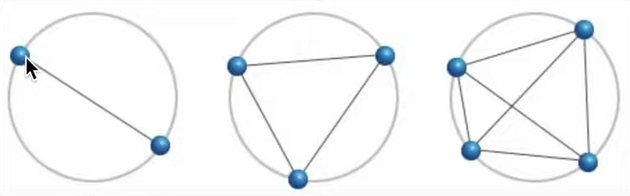
In this case, GPT-4o came up with the bang-on right answer of 57. But Claude 3.5 came up with the answer of 64 which is not quite correct. Both models gave logical reasoning steps as to why they arrived at the answer. The formatting of the math formulas in GPT-4o is preferable to that of Claude 3.5.
Our Verdict
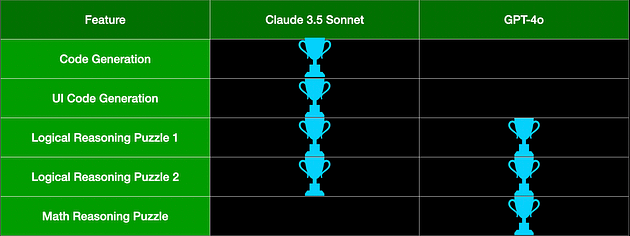
Based on our tests, we conclude that the winner with code generation tasks, be it pure-backed code or GUI code, is Claude 3.5 sonnet. It's a close tie with logical reasoning tasks. But when it comes to mathematical reasoning tasks, GPT-4o still leads the way and Claude is yet to catch up.
In terms of generation speed, Claude is no doubt the winner as it churns out text or code much faster than GPT-4o. Check out our video if you wish to compare the speed of text generation in real time.
Shout Out
If you liked this article, why not follow me on Twitter where I share research updates from top AI labs every single day of the week?
Also please subscribe to my YouTube channel where I explain AI concepts and papers visually.
\ \n
This content originally appeared on HackerNoon and was authored by Shrinivasan Sankar
Shrinivasan Sankar | Sciencx (2024-07-02T16:26:37+00:00) Claude 3.5 Sonnet vs GPT-4o — An honest review. Retrieved from https://www.scien.cx/2024/07/02/claude-3-5-sonnet-vs-gpt-4o-an-honest-review/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.