
This content originally appeared on Level Up Coding - Medium and was authored by Sreejith
Tech enthusiasts..! Today, we’re exploring into the world of concurrency. In one corner, we have the traditional threads, and in the other, the young contender—virtual threads. Which one will scrape the web faster? We will explore how these techniques can transform your application into faster and more efficient versions than ever before.
Conventional threads utilize a significant amount of memory and CPU resources. When a large number of threads are created, it can lead to resource contention. Handling synchronization, context switching, and thread lifecycle in conventional threads is often complex and prone to errors. This complexity increases the likelihood of errors such as race conditions and deadlocks. More over, the heavyweight nature of conventional threads limits their scalability.
Let’s now talk about virtual threads. Virtual threads were first introduced as a preview in Java 19 and are still under development in Java 21. It’s a scalable and lightweight replacement for conventional threads that can support millions of concurrent threads without significantly burdening system resources.
Why virtual threads are not heavy weight.
Virtual threads differ significantly from operating system threads because they operate entirely in user mode. Unlike traditional threads, virtual threads do not require direct support from the operating system. Instead, they are managed by the runtime environment itself. As a result, it offers a lighter-weight alternative to OS threads, allowing for more efficient context switching. Virtual threads employ an adjustable stack technique, in contrast to traditional threads, which require fixed stack size
Build a web application:
Let’s build this Spring Boot application step-by-step.
Step 0: Setup Prometheus & Grafana
Prometheus, known for its efficient time-series database and powerful querying language, excels at collecting and storing metrics from various sources in real-time. It offers robust support for service-level monitoring, making it ideal for tracking performance metrics, resource usage, and application health.
On the other hand, Grafana complements Prometheus by providing a versatile visualization platform. With Grafana, users can create dynamic dashboards that display Prometheus metrics in visually appealing graphs, charts, and tables.
Setup Docker for Prometheus and Grafana:
docker-compose.yml:
version: '3.7'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana
container_name: grafana
ports:
- "3000:3000"
restart: unless-stopped
volumes:
- ./grafana/datasources:/etc/grafana/provisioning/datasources
prometheus.yml:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: springboot-webscrap-job
honor_labels: true
metrics_path: /actuator/prometheus
static_configs:
- targets: ['host.docker.internal:8080']
labels:
application: 'springboot-virtualthread'
datasource_grafana.yml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://host.docker.internal:9090
isDefault: true
You can access Prometheus @ http://localhost:9090
Grafana @ http://localhost:3000/?orgId=1
Step 1: Set Up the Project
To create a new Spring Boot project using Spring Initializer, visit https://start.spring.io/.
Select the following dependencies to set up your project effectively:
Spring Web for building web applications,
Spring Boot Actuator for monitoring and managing your application,
Spring AOP to incorporate @Timed annotations for aspect-oriented programming benefits,
Spring Boot DevTools for enhanced development capabilities.
Step 2: Include JSoup to scrap the websites
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
Step 3: Include prometheus dependency in pom.xml
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-core</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
Step 4: Define the data model
In Java, the record keyword was introduced as part of JDK 14 to provide a more concise way to declare simple POJO classes
public record Scrap(List<String> scrapUrls, Integer numberOfArticles) {
}Scrap is a record that automatically generates methods such as constructors and accessor methods based on its properties. It can be comparable to the Lombak annotation.
Step 5: Define Traditional Thread
@Bean
public ThreadPoolTaskExecutor traditionalThreadExecutor() {
ThreadPoolTaskExecutor traditionalExecutor = new ThreadPoolTaskExecutor();
traditionalExecutor.setCorePoolSize(10); // Set core pool size as needed
traditionalExecutor.setMaxPoolSize(20); // Set maximum pool size as needed
traditionalExecutor.setThreadNamePrefix("traditional-thread-");
return traditionalExecutor;
}
Step 6: Define Virtual Thread
@Bean
public ExecutorService virtualThreadExecutor() {
ExecutorService executor= Executors.newVirtualThreadPerTaskExecutor();
return executor;
}
Step 7: Class Definition and Mapping
At the heart of our exploration is the ScrapeController class, marked with @RestController and mapped to /scrape. This means it’s ready to handle HTTP requests related to scraping operations.
@RestController
@RequestMapping("/scrape")
public class ScrapeController {
...
}
Step 8: Dependency Injection
Here, we use @Autowired to inject two thread executors: a virtual thread executor and a traditional thread executor. These are essential for managing tasks concurrently.
@Autowired
private ExecutorService virtualThreadExecutor;
@Autowired
private ThreadPoolTaskExecutor traditionalThreadExecutor;
Step 9: Scrape via traditional threads.
@Timed(value = "web.scrape.time.traditional.thread", description = "Time taken to scrape websites via traditional threads")
@PostMapping("/traditional/block/{seconds}")
public Map<String, List<String>> scrapeWebsitesUsingTraditionalThreads(@RequestBody Scrap request, @PathVariable Long seconds) {
....
}
Metrics are accessed at http://localhost:8080/actuator/prometheus. We employ the traditional thread executor to dispatch tasks. Each URL is processed using the getTopHeadlines method to fetch the top headlines.
List<String> urls = request.scrapUrls();
List<Future<Map<String, List<String>>>> futures = urls.stream()
.map(url -> traditionalThreadExecutor.submit(() -> {
//Block the thread to simulate expensive process
blockThread(seconds);
System.out.println("Handled by traditional thread: " + Thread.currentThread());
return getTopHeadlines(url, request.numberOfArticles());
}))
.collect(Collectors.toList());
Step 10: Scrape via Virtual Threads
This method processes POST requests aimed at scraping websites using virtual threads.
@Timed(value = "web.scrape.time.virtual.thread", description = "Time taken to scrape websites via virtual threads")
@PostMapping("/virtual/block/{seconds}")
public Map<String, List<String>> scrapeWebsitesUsingVirtualThreads(@RequestBody Scrap request, @PathVariable Long seconds) {
With the URLs in hand, we utilize the virtual thread executor to submit tasks. Each URL undergoes processing via the getTopHeadlines method, fetching top headlines based on the number of articles requested.
List<String> urls = request.scrapUrls();
List<Future<Map<String, List<String>>>> futures = urls.stream()
.map(url -> virtualThreadExecutor.submit(() -> {
//Block the thread to simulate expensive process
blockThread(seconds);
System.out.println("Handled by virtual thread: " + Thread.currentThread());
return getTopHeadlines(url, request.numberOfArticles());
}))
.collect(Collectors.toList());
Step 11: Handling Futures
As we await results, we traverse through futures, fetching scraped data or handling errors if any arise. This ensures robust error handling and effective retrieval of scraped headlines.
Map<String, List<String>> headlines = futures.stream().map(future -> {
try {
return future.get();
} catch (Exception e) {
Map<String, List<String>> errorMap = new HashMap<>();
errorMap.put("Error fetching content from URL", List.of(e.getMessage()));
return errorMap;
}
})
.flatMap(map -> map.entrySet().stream())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));Step 12: Scrapping websites
We utilize Jsoup to establish a connection to a URL and employ varying CSS classes (which differ depending on the website) to extract the latest headlines.
try {
Document doc = Jsoup.connect(url).get();
Elements headlines = doc.select(".indicate-hover, .summary-class, .container__headline-text, [data-testid='card-headline'], a.crd_ttl8");
int count = 0;
for (Element headline : headlines) {
if (count < numberOfArticles) {
if(!StringUtils.isBlank(headline.text())) {
topHeadlines.add(headline.text());
count++;
}
} else {
break;
}
}
topHeadlinesMap.put(url, topHeadlines);
} catch (IOException e) {
System.err.println("Error fetching URL: " + url);
e.printStackTrace();
}Step 13: Putting it together
package com.learn.webscrap.controller;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Future;
import java.util.stream.Collectors;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.learn.webscrap.model.Scrap;
import io.micrometer.common.util.StringUtils;
import io.micrometer.core.annotation.Timed;
@RestController
@RequestMapping("/scrape")
public class ScrapeController {
@Autowired
private ExecutorService virtualThreadExecutor;
@Autowired
private ThreadPoolTaskExecutor traditionalThreadExecutor;
@Timed(value = "web.scrape.time.virtual.thread", description = "Time taken to scrape websites via virtual threads")
@PostMapping("/virtual/block/{seconds}")
public Map<String, List<String>> scrapeWebsitesUsingVirtualThreads(@RequestBody Scrap request, @PathVariable Long seconds) {
List<String> urls = request.scrapUrls();
List<Future<Map<String, List<String>>>> futures = urls.stream()
.map(url -> virtualThreadExecutor.submit(() -> {
//Block the thread to simulate expensive process
blockThread(seconds);
System.out.println("Handled by virtual thread: " + Thread.currentThread());
return getTopHeadlines(url, request.numberOfArticles());
}))
.collect(Collectors.toList());
Map<String, List<String>> headlines = futures.stream().map(future -> {
try {
return future.get();
} catch (Exception e) {
Map<String, List<String>> errorMap = new HashMap<>();
errorMap.put("Error fetching content from URL", List.of(e.getMessage()));
return errorMap;
}
})
.flatMap(map -> map.entrySet().stream())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
return headlines;
}
@Timed(value = "web.scrape.time.traditional.thread", description = "Time taken to scrape websites via traditional threads")
@PostMapping("/traditional/block/{seconds}")
public Map<String, List<String>> scrapeWebsitesUsingTraditionalThreads(@RequestBody Scrap request, @PathVariable Long seconds) {
List<String> urls = request.scrapUrls();
List<Future<Map<String, List<String>>>> futures = urls.stream()
.map(url -> traditionalThreadExecutor.submit(() -> {
//Block the thread to simulate expensive process
blockThread(seconds);
System.out.println("Handled by traditional thread: " + Thread.currentThread());
return getTopHeadlines(url, request.numberOfArticles());
}))
.collect(Collectors.toList());
Map<String, List<String>> headlines = futures.stream().map(future -> {
try {
return future.get();
} catch (Exception e) {
Map<String, List<String>> errorMap = new HashMap<>();
errorMap.put("Error fetching content from URL", List.of(e.getMessage()));
return errorMap;
}
})
.flatMap(map -> map.entrySet().stream())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
return headlines;
}
public static Map<String, List<String>> getTopHeadlines(String url, Integer numberOfArticles) throws IOException {
Map<String, List<String>> topHeadlinesMap = new HashMap<>();
List<String> topHeadlines = new ArrayList<>();
try {
Document doc = Jsoup.connect(url).get();
Elements headlines = doc.select(".indicate-hover, .summary-class, .container__headline-text, [data-testid='card-headline'], a.crd_ttl8");
int count = 0;
for (Element headline : headlines) {
if (count < numberOfArticles) {
if(!StringUtils.isBlank(headline.text())) {
topHeadlines.add(headline.text());
count++;
}
} else {
break;
}
}
topHeadlinesMap.put(url, topHeadlines);
} catch (IOException e) {
System.err.println("Error fetching URL: " + url);
e.printStackTrace();
}
return topHeadlinesMap;
}
private void blockThread(long seconds) {
try {
Thread.sleep(seconds*1000);
}catch(Exception ex ) {
Thread.currentThread().interrupt();
ex.printStackTrace();
}
}
}
Step 14: Run the Application
Start your Spring Boot application and test the endpoints using a tool like Postman or curl.
· POST to `/scrape/traditional/block/1 ` to scrape using traditional threads.
· POST to `/scrape/virtual/block/1 ` to scrape using virtual threads.
{
"numberOfArticles": 1,
"scrapUrls": [
"https://www.nytimes.com/",
"https://www.bbc.com/news",
"https://cnn.com",
"https://ndtv.com"
]
}Step 15: Performance Statistics: Traditional Threads vs. Virtual Threads
To provide a comprehensive comparison, we conducted a series of tests to measure performance across several key metrics: memory usage, CPU utilization, thread creation time, and throughput.
Test Environment:
· CPU: Intel Core i7–9700K
· Memory: 16 GB DDR4
· Java Version: OpenJDK 20
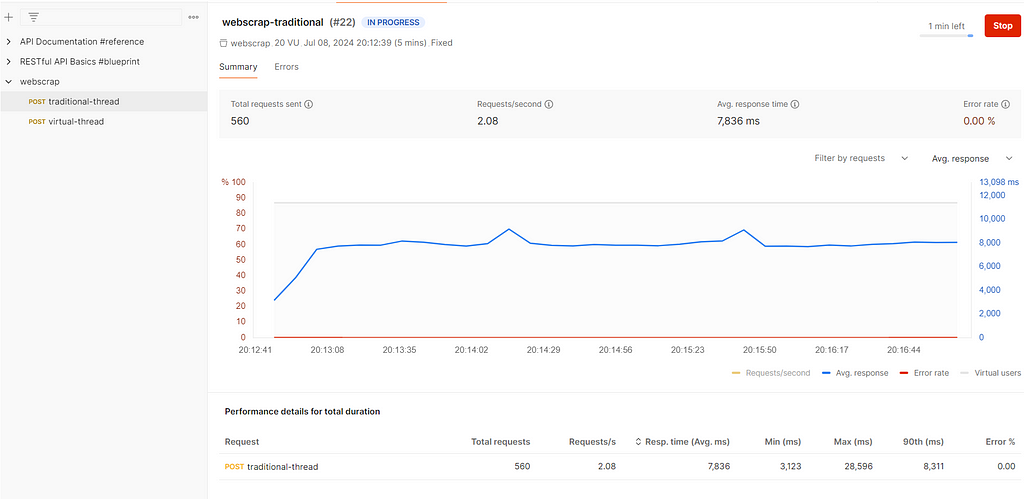
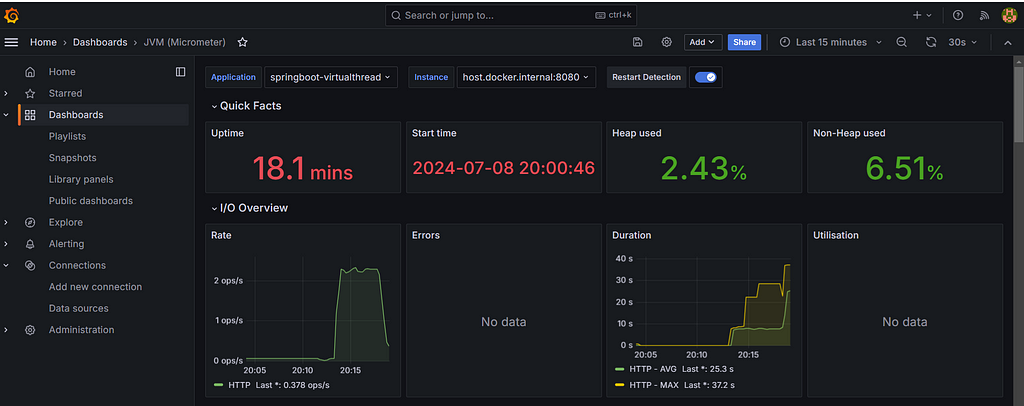
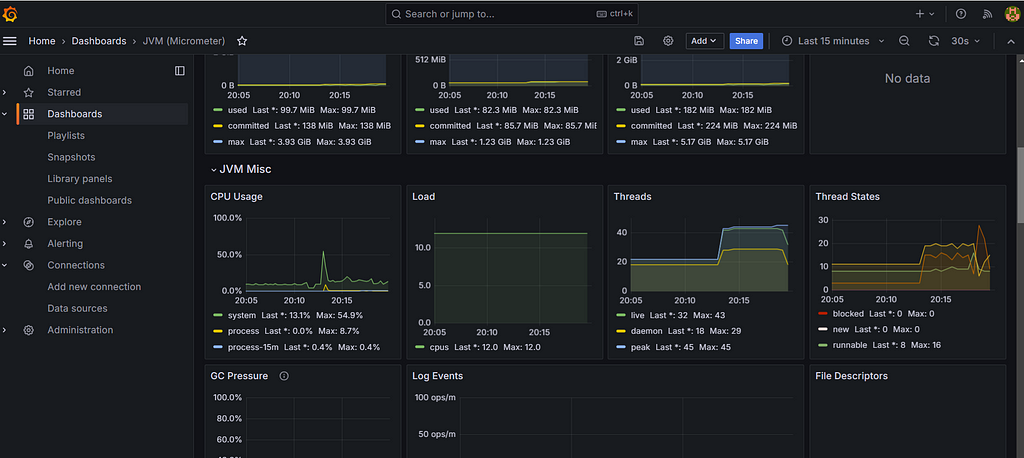
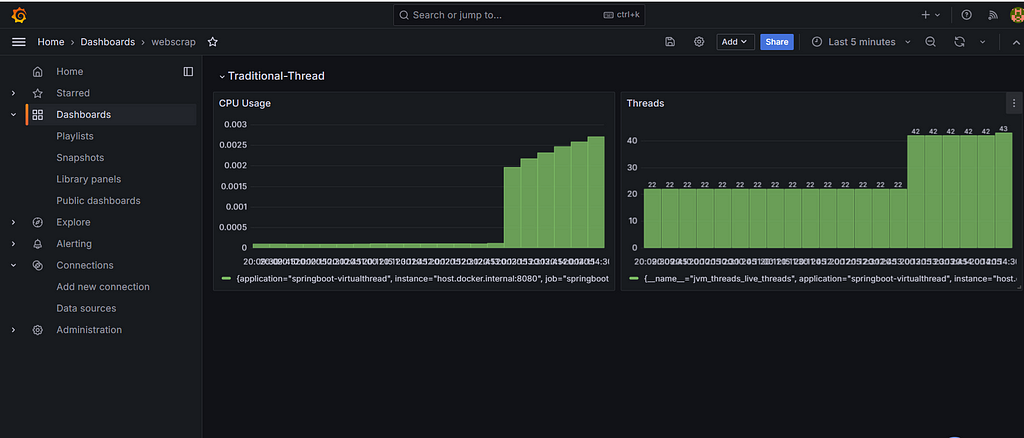
Virtual Thread:
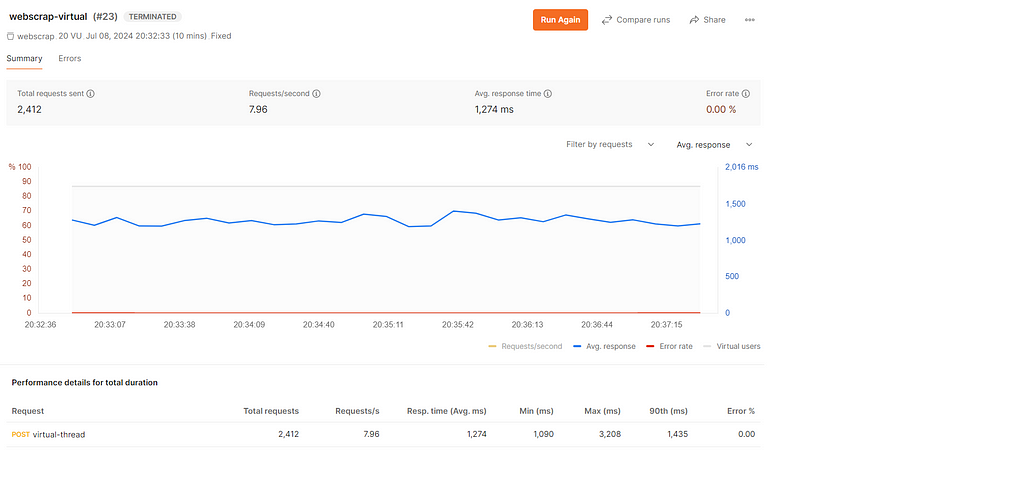
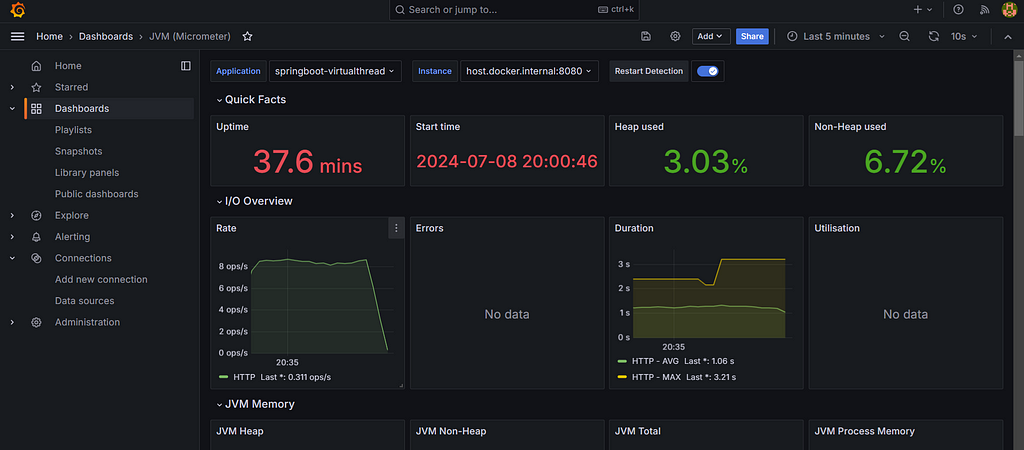
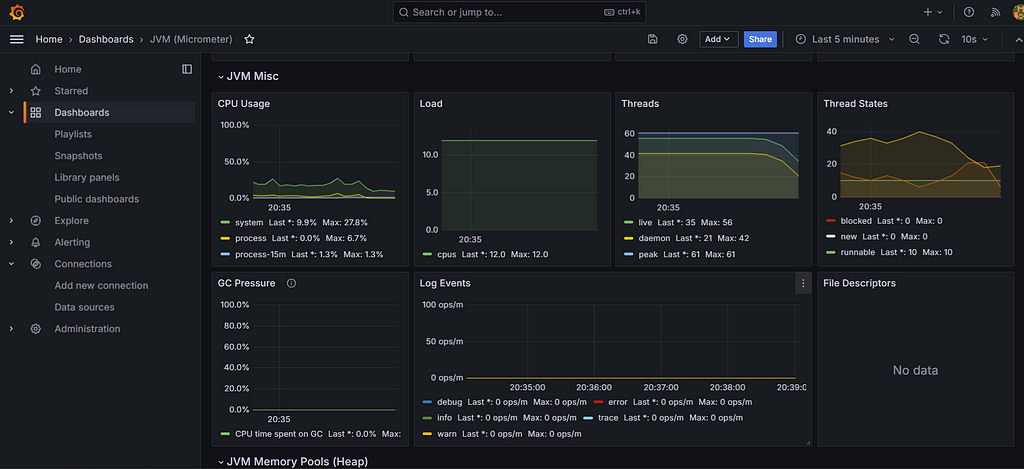
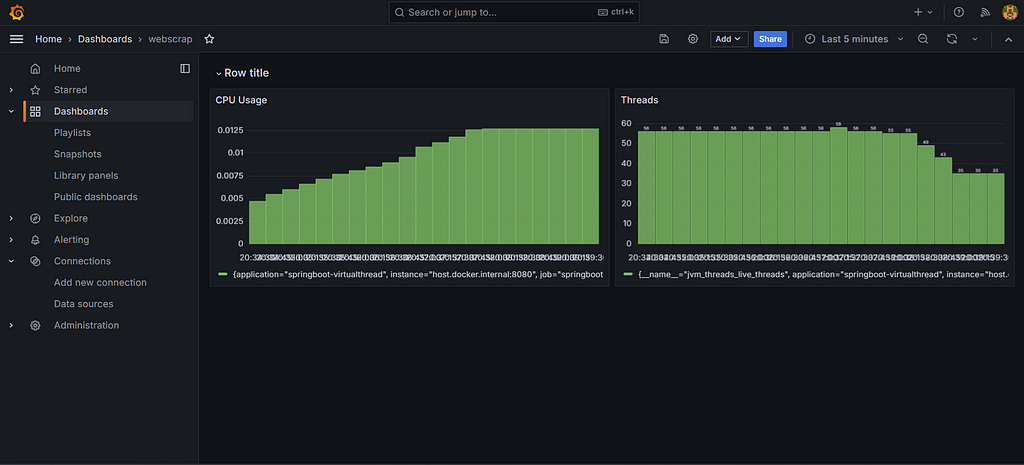
Conclusion:
In our tests, Virtual Threads outperformed Traditional Threads across all metrics. They exhibited lower memory usage, more stable CPU utilization, faster thread creation times, and higher throughput. This makes them an ideal choice for modern applications that require high concurrency and efficiency.
So, tech enthusiasts, it’s time to embrace the future. Virtual Threads are not just a new flavor — they are the new standard for building fast, efficient, and scalable applications. The next time you dive into web scraping or any concurrent task, remember: the Virtual Threads are here to take your applications to the next level.
Enhancing Web Scraping with Virtual Threads was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Sreejith
Sreejith | Sciencx (2024-07-14T17:24:17+00:00) Enhancing Web Scraping with Virtual Threads. Retrieved from https://www.scien.cx/2024/07/14/enhancing-web-scraping-with-virtual-threads/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.