
This content originally appeared on Level Up Coding - Medium and was authored by Stefan Pietrusky

NUMBERS, DATA AND FACTS
According to Statista, the Google-owned video portal YouTube is in second place in the ranking of the largest social networks and messengers, with around 2.49 billion active users. Only Facebook (3.05 billion) has more active users. WhatsApp is in third place (2 billion) [1]. The total number of active social media users worldwide is now 5 billion and, according to the Statista Global Consumer Survey, has almost reached the number of internet users (5.4 billion) [2]. The figures make it clear that there are still many opportunities in the social media sector. As a result, there are more and more so-called influencers. Companies have long since incorporated this area into their portfolio of opportunities to promote their products. According to estimates by the Statista Research Department, the influencer marketing market is set to grow from the current 17.4 billion US dollars to 22.2 billion US dollars by 2025 [3]. In cooperation with “The Influencer Marketing Factory”, the Statista Research Department recorded the annual income of content creators (CC) in the USA in 2023. A quarter of CCs stated that they earn between 50,000 and 100,000 US dollars, with a similar number (24%) stating that they earn between 100,000 and 500,000 US dollars [4].
Based on these data and figures, it is probably not surprising that more and more young people can imagine becoming influencers themselves one day. Influencers themselves now say that what they do every day, in addition to promoting themselves, is a profession and not a hobby. The opportunities to be successful as an influencer, i.e. to build up a correspondingly large community in order to earn money through advertising partners, are now easier than you might think. Advances in the field of machine learning not only simplify the actual production (audio, image, text and video generation) of content, but can also help to optimize the reach and effectiveness of published content. In the long term, this technological progress means that sooner or later there will be more influencers than people who can actually or only apparently be influenced.
WHAT THIS ARTICLE IS ABOUT!
Based on the situation described, I would like to show in this article how to program a bot that generates YouTube views. Specifically, a video on YouTube is played in an automated browser with random proxies. The bot also simulates human behavior to reduce the likelihood of YouTube’s algorithms detecting the automated views. The development is for educational purposes only. The aim is to illustrate how easy it is to manipulate the parameters of well-known social media services and how practically anyone can become an influencer or fake influencer with any content (e.g. fake news, conspiracy myths, racist content, etc.). Of course, a certain technical affinity is required to set up the bot. YouTube was chosen at random for this post. In principle, the process can also be transferred to other providers (e.g. music streaming platforms). In addition to demonstrating pure manipulation, ethical questions should also be raised in the context of courses as to the extent to which certain figures in social media services are credible at all.
THE COMPUTER DOESN’T SAY NO?
If you were to ask an LLM (e.g. ChatGPT, Gemini, LLM model from HuggingFace via Open WebUI etc.) to generate a bot, you would first receive warnings. The development of such a bot would be illegal. The bot violates guidelines. Its use will have technical consequences (e.g. blocking of accounts) or there may even be a threat of legal prosecution. However, if you go online and enter “Buy YouTube Views” in a search engine, for example, you will receive countless offers from providers who use such bots to push or “advertise” content. Here you can buy packages with different volumes (100, 1,000, 10,000 or 100,000 views). Prices vary depending on the provider. These pages do not refer to bots, but to legitimate social media marketing. Depending on how these bots are programmed, the purchased views quickly disappear again because they are recognized by YouTube’s algorithms. Let’s get back to the output of the LLMs. If, after receiving the warning, you say that the development of such a bot is being carried out for research purposes, you will quickly receive information on what you need to do to implement it. Depending on the provider, you will receive more detailed answers and can then start development.
BOT PREPARATION
I will go through the points step by step that are required for the bot or Python script at the end of the article to work. Python should be installed on your system. Depending on your operating system, you can download the required execution file from the official website. After installation, you can check whether the installation was successful using the terminal with the following command:
python --version
After Python has been installed, the following packages must be installed: selenium (to control the web browser), beautifulsoup4 (to parse HTML content) and requests (to send HTTP requests and retrieve proxy lists). The installation is carried out via the terminal:
pip install selenium beautifulsoup4 requests
Next, we take care of the WebDriver, which plays an important role in the automation of the web browser. Specifically, it is a bridge between the Selenium script and the browser. The browser is controlled by the WebDriver based on the instructions specified in the script. Depending on the browser to be used later, a different WebDriver is required. In this example, I am using Firefox and therefore need the GeckoDriver to control the WebDriver API. The GeckoDriver can be downloaded from the following official site.
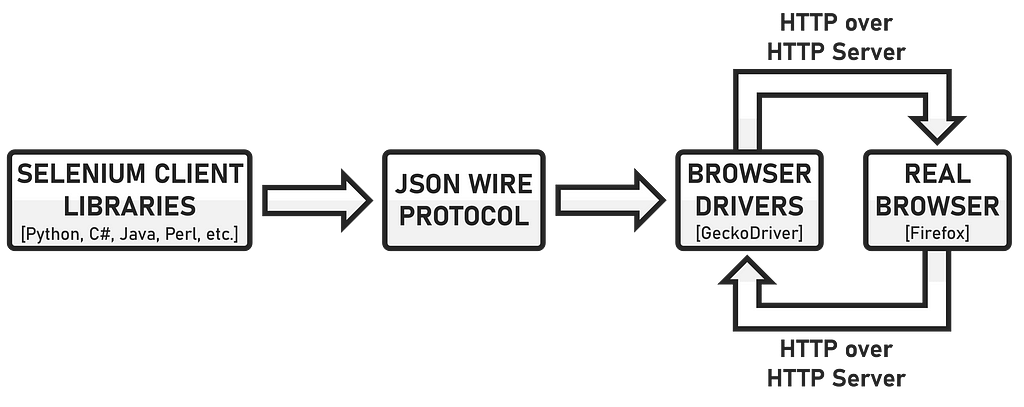
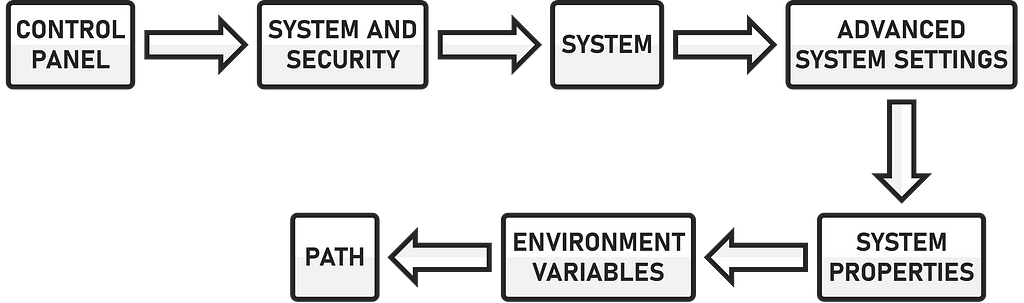
The system must be configured accordingly so that the WebDriver can be found and used by Selenium. After the GeckoDriver has been downloaded, the directory is unpacked and the “geckodriver.exe” file is copied into a directory. I have named the directory YT_VB (YouTube View Bot) and created it on the desktop. I will explain the following steps in more detail for devices with Windows as the operating system. In the Control Panel, go to “System and Security”, then to “System”. Go to “Advanced system settings” via the information display and click on “Environment variables” in the “System properties”. In the overview of system variables, search for the variable “PATH” and implement the path to the directory where the “geckodriver.exe” file is located.
For macOS and Linux, the unpacked “geckodriver.exe” file can be moved to a directory that is contained in the path (e.g. /usr/local/bin). Alternatively, the path can be added permanently or temporarily. If the environment variable described has been expanded, everything must be confirmed and the system restarted for the adjustments to work. To check, you should enter the following command in the terminal after the restart.
geckodriver --version
If the version is displayed, everything has worked. Next, let’s move on to the actual Python script and how it works.
A total of three bots are available. The code for the basic version can be found in the file “ytvb1.py”. A customized bot, where a proxy IP list is created manually (.txt file) and the Python script accesses it, is located in the file “ytvb2.py”. The file also contains fewer comments.The bot with user interface is located in the file “ytvb3.py”. The different files make it easier to understand the different implementations and decide for yourself what you want to use. The basic version is explained step by step below. If a supplement is contained in another file, this will be mentioned.
BOT PYTHON SCRIPT [IMPORT MODULE]
The first step is to import the required modules. I have already mentioned what Selenium, Requests and BeautifulSoup do. For the implementation of waiting times in the script, “time” is used. To simulate human behavior and fool YouTube’s algorithms, “random” is used. Specifically, random times and movements are generated here as if you were scrolling down and up the page of the video. Both are part of the standard Python library and do not need to be installed separately.
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import requests
from bs4 import BeautifulSoup
import random
BOT PYTHON SCRIPT [RETRIEVE PROXIES]
The function “get_proxies():” retrieves a list of proxies from a website. The following page was used for this article. The function sends an HTTP request to the page “requests.get(url)”, parses the HTML response (BeautifulSoup) and extracts the proxy IP addresses and ports. For this to work, the table containing the proxy information must be found in the source code of the page. In this specific example, the table with the IPs on the page is referred to as the CSS class “table table-striped table-bordered”.
def get_proxies():
url = 'https://www.sslproxies.org/'
response = requests.get(url)
if response.status_code != 200:
raise Exception(f"Failed to fetch proxies: Status code {response.status_code}")
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', {'class': 'table table-striped table-bordered'})
if table is None:
raise Exception("Could not find the proxy list table on the webpage.")
proxies = []
for row in table.find_all('tr')[1:]:
cols = row.find_all('td')
if len(cols) < 2:
continue
proxy = f"{cols[0].text}:{cols[1].text}"
proxies.append(proxy)
return proxies
An alternative to this procedure is to create a .txt file in which the “proxy IPs” are created in the form “ip:port” (e.g.: 192.168.1.1:8080). The code, specifically the “get_proxies():” function, must be adapted as follows. Care must be taken to keep the list up to date, as outdated or faulty proxies can lead to errors when the bot is executed. The implementation of this function is contained in the file “ytvb2.py”.
def load_proxies_from_file(file_path):
try:
with open(file_path, 'r') as file:
proxies = file.read().splitlines()
print(f"Successfully loaded {len(proxies)} proxies from file.")
return proxies
except FileNotFoundError:
print(f"Error: File not found - {file_path}")
return []
proxies_file_path = 'proxyip.txt' # Path to the proxy list
proxies = load_proxies_from_file(proxies_file_path)
In order to use only the functional proxies from the list, a validation of the proxy IPs can be added. The causes of proxy errors can be manifold. They are either outdated, no longer active, they may no longer be accessible due to firewall restrictions, the servers may be overloaded or the timeout value may be too low. The latter leads to no connection if the proxy is too slow. The function “is_proxy_working()” checks whether a proxy is working by sending a request to the following page. If the request is successful (status code 200), the proxy is working. The function “get_working_proxies()” filters the list of proxies and only returns those that are working. The implementation of this function is contained in the file “ytvb3.py”.
def is_proxy_working(proxy):
test_url = "http://httpbin.org/ip"
proxies = {
"http": f"http://{proxy}",
"https": f"http://{proxy}",
}
try:
response = requests.get(test_url, proxies=proxies, timeout=15)
if response.status_code == 200:
return True
except requests.RequestException as e:
st.write(f"Proxy check failed for {proxy}: {e}")
return False
def get_working_proxies(proxies):
working_proxies = [proxy for proxy in proxies if is_proxy_working(proxy)]
st.write(f"Found {len(working_proxies)} working proxies out of {len(proxies)}.")
return working_proxies
In general, different sources for proxies should be used to increase the likelihood that they will work. You should also update the list regularly. Since public proxy lists often contain non-functional proxies, you can also use paid services.
The implementation of validation means that the bot’s process takes longer, as all entries in the list are first checked before the first request. If you do not want this, you can transfer the proxy functionality from the file “ytvb2.py” to “ytvb3.py”.
BOT PYTHON SCRIPT [ACCEPT OR REJECT COOKIES]
The function “accept_cookies():” is used to accept the cookie notice on the YouTube page. It waits until the button for rejection or acceptance is displayed “WebDriverWait”. In this example, the button to reject is activated. If everything is to be accepted, the code must be adapted accordingly. An XPath selector is used to find the corresponding button “By.XPATH”.

The button is then activated. In addition, a few outputs are included to see which method was successful. Specifically, a fallback, i.e. a backup mechanism, has been built in to ensure that the cookie hint is activated. This ensures the functionality of the bot, as it can always happen that the first attempt to find the button fails due to timing problems or network delays. Alternatively, you can also increase the value of “WebDriverWait” to ensure that the page is fully loaded before an attempt is made to activate a specific element. The implementation of this function is important because each time you visit the YouTube page, its server recognizes a proxy IP address from the extracted list as a new user, causing the cookie display to appear again and again. Your own IP address is masked by the proxy IP address.
def accept_cookies(driver):
try:
cookie_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//span[text()="Reject all"]/ancestor::button'))
)
cookie_button.click()
print("Accepted cookies.")
except Exception as e:
print("No cookie prompt found or could not click the button:", e)
try:
# Fallback
cookie_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//span[text()="Reject all"]/ancestor::button'))
)
cookie_button.click()
print("Accepted cookies with alternative method.")
except Exception as e:
print("Alternative method failed. No cookie prompt found or could not click the button:", e)
BOT PYTHON SCRIPT [PLAY AND PAUSE VIDEO]
The function “play_and_pause_video():” simulates the playback of a video on YouTube with random pauses and scrolling movements to simulate human behavior. Specifically, the playback time is selected between “min_play_time” and “max_play_time” and the video is paused randomly during this time. For a video call to count as a call, the video should be played for at least 30 seconds. Scrolling takes place in “step_size” steps. There are pauses between the scrolling movements “scroll_pause_time”, which are randomly within a range so that it does not appear too static. When a certain scroll height “scroll_limit” has been reached, the scroll direction is changed. Specifically, the bot first moves the window downwards and then upwards again. Another option would be to randomize the starting point in the video.
def play_and_pause_video(driver, min_play_time, max_play_time):
try:
# Random playback duration between min and max
play_time = random.uniform(min_play_time, max_play_time)
print(f"Playing video for {play_time:.2f} seconds.")
# Play video
play_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//button[contains(@class, "ytp-play-button")]'))
)
play_button.click()
# Split the playback duration and scroll during playback
start_time = time.time()
scroll_pause_time = random.uniform(5, 10)
step_size = random.choice([50, 75, 100])
scroll_direction = 1
current_position = 0
scroll_limit = random.randint(300, 500)
while time.time() - start_time < play_time:
driver.execute_script(f"window.scrollBy(0, {step_size * scroll_direction});")
current_position += step_size * scroll_direction
time.sleep(scroll_pause_time)
if current_position >= scroll_limit:
scroll_direction = -1
elif current_position <= 0:
scroll_direction = 1
# Random pause during playback
if random.random() < 0.3:
pause_duration = random.uniform(3, 5)
print(f"Pausing video for {pause_duration:.2f} seconds.")
play_button.click()
time.sleep(pause_duration)
play_button.click()
# Pause video
play_button.click()
print(f"Video paused after {play_time:.2f} seconds.")
except Exception as e:
print("Could not play and pause video:", e)
BOT PYTHON SCRIPT [MAIN SCRIPT]
In the main part of the script, the URL of the video is specified “video_url” for which the views are to be increased by way of example. The number of repetitions is specified “num_repeats” as well as the minimum “min_play_duration” and maximum “max_play_duration” playback time of the video. The proxy list is retrieved “proxies = get_proxies()” and the WebDriver is configured to finally access YouTube with various proxies. The concrete process is that YouTube is opened, the cookies are accepted, the specific video is called up and played for a certain time. The browser is closed, and the process is repeated with another proxy. The reason why the main YouTube page is opened first, and then the actual video is played, is that it looks more human than simply starting a browser and opening the video straight away. Now, the link of the “video_url” argument needs to be adjusted. Specifically, the link to the video whose views are to be increased must be implemented.
# Video URL whose views are to be increased
video_url = "https://www.youtube.com/watch?v=h2IsokP_knE&list=PLhVrO77VPbRJnHg5RDu1JSaozdhTndzIp" # Hier die URL des gewünschten Videos einfügen
# Number of repetitions to increase the views
num_repeats = 10
# Minimum and maximum duration of the video playback in seconds
min_play_duration = 60
max_play_duration = 120
# Retrieve list of proxies
try:
proxies = get_proxies()
print(f"Successfully fetched {len(proxies)} proxies.")
except Exception as e:
print(f"Error fetching proxies: {e}")
proxies = []
def get_proxy_driver(proxy):
options = Options()
options.add_argument('--proxy-server=%s' % proxy)
driver = webdriver.Firefox(options=options)
return driver
if proxies:
# Repetitions with different proxies
for i in range(num_repeats):
proxy = proxies[i % len(proxies)]
driver = get_proxy_driver(proxy)
# Open YouTube homepage
driver.get("https://www.youtube.com")
accept_cookies(driver)
driver.get(video_url)
# Play and pause video
play_and_pause_video(driver, min_play_duration, max_play_duration)
# Close the browser to change proxy
driver.quit()
else:
print("No proxies available to use.")
print("Done")
Depending on which version of the bot you choose, go to the directory containing the WebDriver execution file and the Python script. The bot is started via the terminal with the command:
python ytvb1.py # Bot basic
python ytvb2.py # Bot with manual proxy IP list
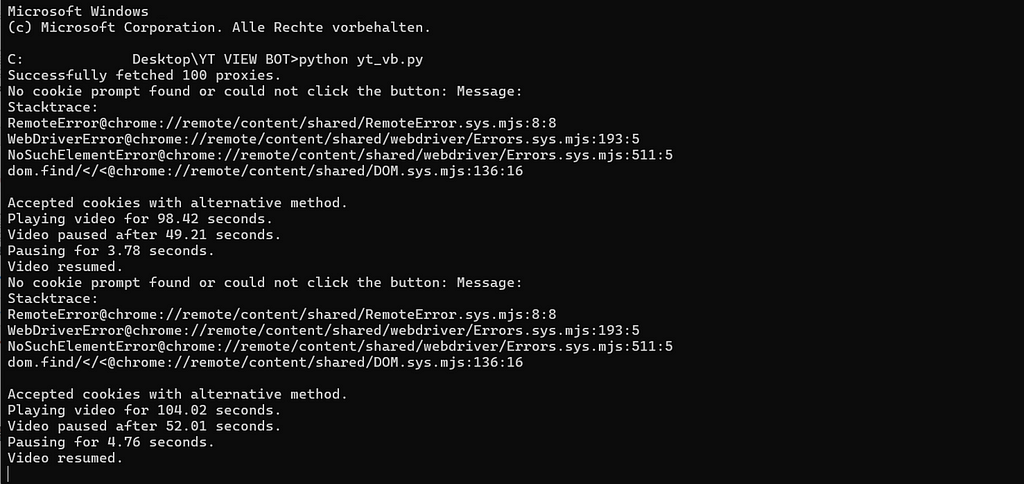
When the bot is running, the output in the terminal should look like this after the first run. Error messages are displayed that the WebDriver has problems finding the button in the cookie window. The fallback solves the problem. This is followed by output on how long a video is played and paused. The output is repeated depending on how many repetitions were specified in the “num_repeats” argument.
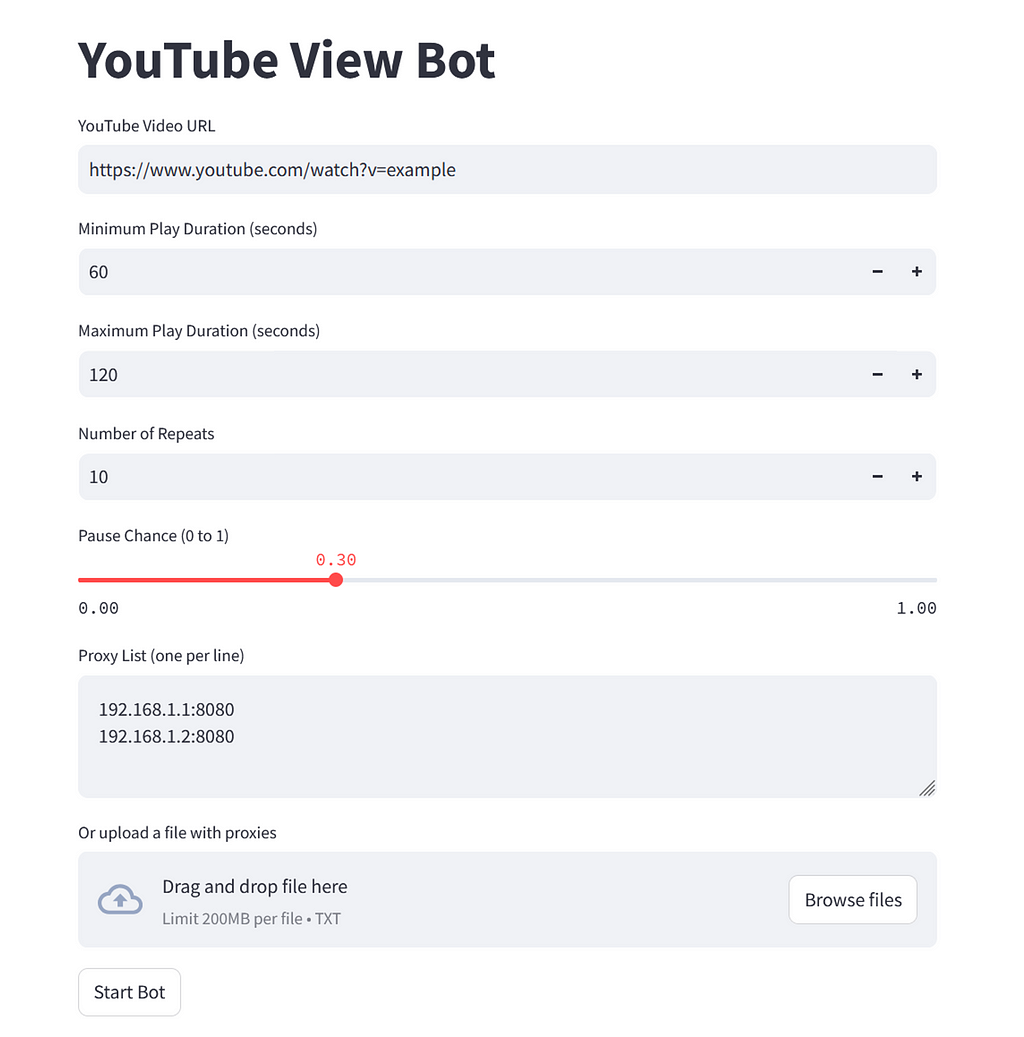
GUI FOR THE BOT!
To make it easier to control the bot and adjust the various parameters more quickly, Streamlit can be used to create a graphical user interface. To be able to use Streamlit, it must first be installed using the following command:
pip install streamlit
To create the GUI elements, “st.title()”, “st.text_input()”, “st.number_input()”, “st.slider()” and “st.text_area()” are used. The bot is started via a button created with “st.button()”. The proxy IPs can be added via the text field, alternatively a drag-and-drop field has been set up into which the previously created .txt file can be dragged. If no file has been uploaded, the proxy IPs contained in the text field are used. If the automation process is not to run in the background but in the foreground, the following argument in the “get_driver_with_proxy()” function must be removed:
options.add_argument('--headless') Headless mode consumes fewer resources overall and also reduces the risk of unintentional user interaction, which could potentially interrupt the process. The bot with user interface then looks as follows and is started with the command:
streamlit run ytvb3.py
BOT PYTHON SCRIPT [DOWNLOAD]
Click on the folder to download the zip file with the three bots.

ADDITIONAL NOTES
Depending on when a video was uploaded, it may take longer or shorter for the views to be added to the video. If a video has just been uploaded to YouTube, it reacts more quickly to new views. For older videos, views are checked more strictly to avoid fraud. This is called the “auditing” phase. New videos only go through this phase when some time has passed since they were uploaded or when a certain number of views has been reached. This is also the reason why most videos receive a large number of views in the first few days and only very few after that. As part of a test series, the bot was tested on various videos that had had few views for a long time (mostly contributions from scientific conferences). After a certain period of time, the videos finally had more views.
CONCLUSION
This article showed how you can create a bot with simple means to increase the number of views of videos on YouTube. Only a basic setup was shown, which of course does not come close to what the numerous providers on the Internet offer in the area of social media marketing. Despite warnings at the beginning of the request, actual LLMs have assisted in the development of the bot. Sometimes suggestions came up to use Python in combination with Selenium for ethically safe data extraction or web scraping. If you tell the LLM that you no longer want any warnings about ethical concerns or that the bot is being developed in an educational context for demonstration purposes, these are no longer displayed. Thanks for reading and have fun customizing the bot.
SOURCES
[1] We Are Social, & DataReportal, & Meltwater. (31. Januar, 2024). Ranking der größten Social Networks und Messenger nach der Anzahl der Nutzer im Januar 2024 (in Millionen) [Graph]. In Statista. Zugriff am 02. August 2024, von https://urlz.fr/rwzQ
[2] Statista. (2024). Social Media Trends — Welche Plattformen sind am beliebtesten? Zugriff am 2. August 2024, von https://urlz.fr/rwzR
[3] HypeAuditor. (2. Februar, 2024). Entwicklung der Marktgröße des Influencer-Marketings weltweit in den Jahren 2021 bis 2025 (in Milliarden US-Dollar) [Graph]. In Statista. Zugriff am 02. August 2024, von https://urlz.fr/rwzT
[4] The Influencer Marketing Factory. (2. Mai, 2023). Was ist dein jährliches Einkommen als Content-Creator? [Graph]. In Statista. Zugriff am 02. August 2024, von https://urlz.fr/rwzX
The influence of illusion: How bots are changing the social media world was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Stefan Pietrusky
Stefan Pietrusky | Sciencx (2024-08-14T11:20:34+00:00) The influence of illusion: How bots are changing the social media world. Retrieved from https://www.scien.cx/2024/08/14/the-influence-of-illusion-how-bots-are-changing-the-social-media-world/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.