
This content originally appeared on DEV Community and was authored by Leandro Proença
Recentemente escrevi uma saga de 6 artigos sobre Assembly x86, abordando conceitos fundamentais de arquitetura de computadores e programação low-level enquanto ia desenvolvendo um web server minimalista multi-threaded.
Durante o processo, acabei deixando de lado alguns conceitos importantes para artigos posteriores, pois se fosse abordar durante a saga, iria ficar maior do que já foi. Entretanto são conceitos que podem ser tratados à parte, como no caso das filas implementadas na thread pool.
E quando falamos de filas, fica inevitável abordar arrays e como estes são organizados na memória do computador.
Neste artigo, vamos abordar conceitos fundamentais como manipulação de memória, registradores e memória heap ao longo da implementação de arrays.
Vou assumir que você já tem familiaridade com Assembly x86 e a ferramenta GDB. Caso não tenha, recomendo fortemente a leitura da minha saga.
Agenda
- Arrays não existem
- Strings também não existem
- O array mais simples do universo
-
Utilizando um array com dados não inicializados
- Índice para o resgate
- Atingindo o limite do array
-
Heap, heap, hooray!
- Alocação dinâmica de memória com brk
- Ponteiros, ponteiros everywhere
- Resize com brk
- O programa final
- Conclusão
- Referências
Arrays não existem
Arrays não existem. Simples assim.
Como vimos na parte IV da saga, a memória é organizada de forma contígua, onde as informações são alocadas uma após a outra.

Supondo que queremos declarar a seguinte sequência de informações:
1, 2, 'H', 0
Eu sei, eu sei, os tipos estão misturados, mas isto não importa para este momento. Todos eles cabem em 1 byte
Em assembly x86 (vamos chamar de asm no restante do artigo), podemos declarar estas informações da seguinte forma na seção de dados:
section .data
stuff: db 0x1, 0x2, 0x48, 0x0
Lembrando que o caracter 'H' na tabela ASCII representa 0x48 em hexadecimal
Ao utilizarmos o gdb para fazer debugging, podemos confirmar que esta sequência de hexadecimal no rótulo stuff está armazenada da seguinte forma:
# Leitura do primeiro hexabyte em stuff
(gdb) x/1xb (void*) &stuff
0x402000 <stuff>: 0x01
# Leitura do segundo hexabyte em stuff
(gdb) x/1xb (void*) &stuff+1
0x402001: 0x02
# Leitura do terceiro hexabyte em stuff
(gdb) x/1xb (void*) &stuff+2
0x402002: 0x48
Podemos também representar o hexadecimal 0x48 em formato de string utilizando x/s
(gdb) x/s (void*) &stuff+2
0x402002: "H"
É tudo hexadecimal!
Com isto, caso queiramos representar a string "Hello", de acordo com a tabela ASCII, poderia ficar assim:
section .data
msg: db 0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x0
No gdb vamos verificar a representação string do rótulo msg:
(gdb) x/s &msg
0x402000 <msg>: "Hello"
Em asm, é possível declarar a string já com a representação direta da tabela ASCII:
section .data
msg: db "Hello", 0x0
; é o mesmo que
; msg: db 0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x0
Strings também não existem
Ou seja, é tudo hexadecimal na memória. Um array, assim como uma string, é simplesmente uma sequência contígua de dados com mesmo tamanho na memória.
A diferença é que a string é um "array especial" que tem dados que representam caracteres da tabela ASCII (note que ambos precisam delimitar um byte "final" para representar o término da string ou array):

O array mais simples possível
A seguir temos a implementação de um array bastante simples em asm, pelo que iremos explorar cada passo nas seções subsequentes:
global _start
%define SYS_exit 60
%define EXIT_SUCCESS 0
section .data
array: db 1, 2, 3, 0
section .text
_start:
mov al, [array] ; array[0]
mov bl, [array + 1] ; array[1]
mov cl, [array + 2] ; array[2]
mov sil, [array + 3] ; array[3]
.exit:
mov rdi, EXIT_SUCCESS
mov rax, SYS_exit
syscall
Na seção de dados inicializados .data, declaramos um array com 3 elementos de 1 byte cada (inteiros de 1 a 3), utilizando o número 0 como término do array:
section .data
array: db 1, 2, 3, 0
A seguir, na seção .text, que é onde vai o código fonte do programa, podemos acessar os elementos do array utilizando aritmética de ponteiros, armazenando o resultado em registradores:
section .text
_start:
mov al, [array] ; array[0]
No código acima, estamos acessando o valor contido no endereço de memória 0x402000 e armazenando o resultado em um registrador (AL) que tem o tamanho de 1 byte, ou seja, vai ser armazenado no registrador apenas o primeiro byte do array.
Vamos conferir com gdb:
# O array está armazenado no endereço 0x402000
# e contém o valor em hexa 0x00 0x03 0x02 0x01,
# lembrando que esta arquitetura utiliza o formato little-endian
(gdb) x &array
0x402000 <array>: 0x00030201
(gdb) b 13
(gdb) run
(gdb) next
# No registrador AL temos o primeiro elemento do array
(gdb) i r al
al 0x1 1
# É o mesmo que acessar o primeiro hexabyte contido no endereço
# 0x402000
(gdb) x/1xb 0x402000
0x402000 <array>: 0x01
Lembrando que o registrador AL representa os 8-bits menores dentro do espectro do registrador RAX que contempla um total de 64-bits na arquitetura x86_64
Para acessar os demais elementos do array, basta fazer aritmética de ponteiros e ir armazenando em outros registradores de 1 byte:
mov al, [array] ; array[0] => 1
mov bl, [array + 1] ; array[1] => 2
mov cl, [array + 2] ; array[2] => 3
mov sil, [array + 3] ; array[3] => 0 (aqui termina o array)
Utilizando um array com dados não inicializados
Até agora, estamos declarando o array na seção .data onde os dados são inicializados. Mas podemos deixar o programa mais "dinâmico", declarando o array na seção de dados não inicializados, que é a .bss.
Mantendo a compatibilidade com o exemplo anterior, vamos declarar um array de 4 bytes utilizando a diretiva resb que significa "reserve byte", onde os 3 primeiros bytes são reservados para armazenar elementos do array e o último byte representando 0x0 que é o término do array.
section .bss
array: resb 4 ; 3 bytes + 1 byte de término
No gdb, podemos ver que o array está inicializado com os valores tudo a zero, o que indica que o array está vazio mas com 4 bytes reservados:
(gdb) x &array
0x402004 <array>: 0x00000000
(gdb) x/4xb &array
0x402004 <array>: 0x00 0x00 0x00 0x00
Para adicionar elementos no array, precisamos também utilizar aritmética de ponteiros, tal como fizemos no exemplo anterior para acessar um array com dados pré-inicializados.
; Move o valor 1 para o primeiro byte do endereço de memória em array
mov byte [array], 1 ; array[0] = 1
Com gdb confirmamos que no endereço 0x402000 que é onde está o array, foi adicionado o byte 1:
(gdb) x &array
0x402000 <array>: 0x00000001
E se quisermos adicionar o valor 2 no próximo byte do array?
mov byte [array + 1], 2
(gdb) x &array
0x402000 <array>: 0x00000201
Repare que o que modifica é o "índice" do array. Na posição inicial do array, é como se o índice fosse zero, e na posição subsequente, utilizamos o índice 1, podendo incrementar até o término array.
Seria muito complicado ficar manipulando índice hard-coded. Precisamos de um ponteiro para representar este índice.
Índice para o resgate
Assumindo que o ponteiro do array começa com zero, que é o endereço de memória onde está o array, podemos declará-lo na seção de dados inicializados .data:
section .bss
array: resb 4 ; 3 bytes + 1 byte de término
section .data
pointer: db 0
Logo, poderíamos adicionar o primeiro elemento da seguinte forma, certo?
mov byte [array + pointer], 1 ; array + 0
Ao rodar o programa, temos o seguinte erro:
src/live.asm:14: error: invalid effective address: multiple base segments
Este erro indica que estamos tentando fazer manipulação de ponteiros a partir de múltiplos segmentos na memória, no caso o array e pointer.
Para resolver isto, precisamos fazer manipulação de ponteiros com valores imediatos (que foi o caso anterior com número hard-coded) ou com registradores:
; append(1)
mov al, byte [pointer]
mov byte [array + rax], 1 ; array + 0
- a primeira instrução move o primeiro byte contido no endereço de
pointere armazena no registrador AL - a segunda instrução move o valor imediato 1 (elemento do array) para o endereço de memória do array. Como em RAX (versão 64-bits de AL) temos o valor
0x0que representa o ponteiro, então estamos fazendo a inserção no primeiro byte do array
E para armazenar o segundo elemento no array?
; append(2)
mov al, byte [pointer]
mov byte [array + rax], 2
No gdb, vamos verificar o que está acontecendo:
(gdb) x &array
0x402004 <array>: 0x00000002
Uh, oh... Desta forma estamos sobrescrevendo o valor anterior. Queremos na verdade que o ponteiro "ande", ou seja, precisa ser incrementado em um byte para que o append(2) resulte com os 2 elementos no array.
Com a instrução INC podemos resolver este problema:
mov al, byte [pointer] ; pointer -> 0
mov byte [array + rax], 1 ; array + 0
inc byte [pointer] ; pointer -> 1
mov al, byte [pointer]
mov byte [array + rax], 2 ; array + 1
(gdb) x &array
0x402004 <array>: 0x00000201
Yay! Que dia maravilhoso!
Atingindo o limite do array
E se continuarmos incrementando o ponteiro até atingir o limite do array?
mov al, byte [pointer]
mov byte [array + rax], 1 ; array + 0
inc byte [pointer]
mov al, byte [pointer]
mov byte [array + rax], 2 ; array + 1
inc byte [pointer]
mov al, byte [pointer]
mov byte [array + rax], 3 ; array + 2
inc byte [pointer]
# Lendo os primeiros 4 hexabytes do array, temos a representação
# do array cheio com todos os espaços ocupados, lembrando que
# o último byte é o término do array
(gdb) x /4xb &array
0x402004 <array>: 0x01 0x02 0x03 0x00
# O ponteiro está no fim do array
(gdb) x &pointer
0x402000 <pointer>: 0x03
Maravilha, e se adicionar mais um elemento, nosso programa deveria permitir?
mov al, byte [pointer]
mov byte [array + rax], 4 ; array + 3
inc byte [pointer]
# Não deveríamos permitir que mais um elemento fosse adicionado,
# pois nosso array já estava cheio
(gdb) x /4xb &array
0x402004 <array>: 0x01 0x02 0x03 0x04
# O ponteiro está para além da capacidade array (not good...)
(gdb) x &pointer
0x402000 <pointer>: 0x04
Vamos utilizar um jump condicional (explico mais sobre isto na saga) para não permitir que o elemento seja adicionado. Com isto, antes de fazer o append no array, devemos verificar se o ponteiro já não está no fim do array:
cmp byte [pointer], 3 ; verifica se o array está cheio
je .exit ; salta para a rotina .exit caso a flag seja levantada
Assim fica o programa completo:
global _start
%define SYS_exit 60
%define EXIT_SUCCESS 0
section .bss
array: resb 4 ; 3 bytes + 1 byte de término
section .data
pointer: db 0
section .text
_start:
cmp byte [pointer], 3 ; verifica se o array está cheio
je .exit
mov al, byte [pointer]
mov byte [array + rax], 1 ; array + 0
inc byte [pointer]
cmp byte [pointer], 3 ; verifica se o array está cheio
je .exit
mov al, byte [pointer]
mov byte [array + rax], 2 ; array + 1
inc byte [pointer]
cmp byte [pointer], 3 ; verifica se o array está cheio
je .exit
mov al, byte [pointer]
mov byte [array + rax], 3 ; array + 2
inc byte [pointer]
cmp byte [pointer], 3 ; verifica se o array está cheio
je .exit
; não deveria permitir adicionar o quarto elemento,
; pois o array suporta até 3 elementos. desta forma,
; estaríamos escrevendo no endereço de memória de outros
; dados do programa
mov al, byte [pointer]
mov byte [array + rax], 4 ; array + 3
inc byte [pointer]
.exit:
mov rdi, EXIT_SUCCESS
mov rax, SYS_exit
syscall
(gdb) x &pointer
0x402000 <pointer>: 0x00000003
(gdb) x &array
0x402004 <array>: 0x00030201
Perfeito, vamos agora fazer um pequeno refactoring no código separando a lógica de append para uma subrotina:
global _start
%define SYS_exit 60
%define EXIT_SUCCESS 0
%define CAPACITY 3
section .bss
array: resb CAPACITY + 1
section .data
pointer: db 0
section .text
_start:
mov rdi, 1
call .append
mov rdi, 2
call .append
mov rdi, 3
call .append
mov rdi, 4
call .append
.exit:
mov rdi, EXIT_SUCCESS
mov rax, SYS_exit
syscall
.append:
cmp byte [pointer], CAPACITY ; verifica se o array está cheio
je .done
mov al, byte [pointer]
mov byte [array + rax], dil
inc byte [pointer]
.done:
ret
Se você quer entender mais sobre conditional jump, rotinas, call, ret e flags, sugiro a leitura da minha saga que foi referenciada diversas vezes neste artigo
Executando com gdb e...
(gdb) x &array
0x402004 <array>: 0x00030201
(gdb) x &pointer
0x402000 <pointer>: 0x00000003
Um grande Yay!
Entretanto, podem haver situações onde queremos que nosso array seja redimensionado para suportar mais elementos, ou seja, o tamanho do array seria dinâmico.
Como adicionar mais elementos além da capacidade inicial de forma que não podemos escrever em outras áreas da memória que pertencem ao array?
Heap, heap, hooray!
Antes de falar sobre o heap, vamos relembrar como funciona o layout de memória de um programa de computador:

- o layout é representado como uma área na memória do computador onde temos os endereços de memória mais baixos do programa em direção aos endereços mais altos que ficam no topo
- nos endereços de memória mais baixos, temos a seção
.text, onde já vimos que é referente ao programa em si - depois temos a seção de dados que contempla os dados inicializados
.datae a seção a seguir que representa os dados não-inicializados.bss - nos endereços mais altos, temos a stack do programa, que armazena metadados tais como o nome do programa, seus argumentos e qualquer informação do programa que tenha um tamanho fixo cabendo dentro da stack, bem como chamadas de funções e seus respectivos argumentos
- a stack tem um formato de pilha e "cresce pra baixo", ou seja, conforme adicionamos elementos na stack, esta cresce em direção aos endereços mais baixos na memória
No "meio" do layout, entre a seção de dados e a stack, temos uma grande área na memória que muitos acabam associando como heap. No heap, podemos alocar dados de forma dinâmica, diferente da forma estática que fazemos na seção de dados.
Para acomodar um array de tamanho dinâmico que suporte redimensionamento (resize), temos de alocar memória nesta área.
Neste artigo, vamos chamar esta região no meio da memória que fica entre a seção de dados e a stack de heap
Alocação dinâmica de memória com brk
Uma das formas de manipular esta área da memória é através da syscall brk, que muda o program break, que é onde termina a seção de dados.

Com brk, podemos modificar esse program break para endereços mais altos, ou seja, permitindo a manipulação de áreas na memória que vão além da seção de programa e dados.

A primeira coisa que precisamos fazer é mapear a syscall e fazer a chamada que traz o endereço do break atual:
%define SYS_brk 12
....
section .text
_start:
; syscall para acessar o program break (0x403000), que é onde termina
; a seção de dados e começa o heap
mov rdi, 0
mov rax, SYS_brk
syscall
....
Com gdb, vamos analisar o estado do programa:
# Breakpoint na linha da syscall brk
(gdb) b 18
(gdb) run
# O início do programa fica na seção .text e começa com
# 0x401000
(gdb) x _start
0x401000 <_start>: 0x000000bf
# O pointer está na seção .data um pouco mais acima e começa com
# 0x402000
(gdb) x &pointer
0x402000 <pointer>: 0x00000000
# O array está na seção .bss um pouco mais acima e começa com
# 0x402004
(gdb) x &array
0x402004 <array>: 0x00000000
# Executa a syscall brk
(gdb) n
# A syscall brk armazena em RAX o endereço de memória do program break,
# no caso um pouco mais acima em 0x403000
(gdb) i r rax
rax 0x403000 4206592
-
0x401000: seção.textque é onde começa o programa -
0x402000: seção.dataonde ficam os dados inicializados -
0x402004: seção.bssonde ficam os dados não-inicializados -
0x403000: program break, que é onde termina a seção de dados e começa o nosso "heap"
Com isto, a partir do endereço 0x403000 é onde vamos colocar os elementos do nosso array, pelo que o endereço do array pode utilizar apenas um byte, que aponta para o endereço onde começa o primeiro elemento no heap.

Na syscall que fizemos, se o argumento em RDI tiver zero, significa que brk vai retornar o program break atual, no caso 0x403000. Mas podemos fazer mais syscalls brk com o argumento RDI diferente (incrementado), sinalizando que estamos mudando o program break.
A partir de agora, na seção de dados .bss, não precisamos mais reservar 4 bytes para o array, pelo que é necessário apenas 1 byte que irá representar o endereço de memória do array no heap:
global _start
%define SYS_brk 12
%define SYS_exit 60
%define EXIT_SUCCESS 0
%define CAPACITY 3
; inicialmente começa com 0x000000, mas depois irá conter
; o endereço 0x403000
section .bss
array: resb 1
section .data
pointer: db 0
section .text
_start:
mov rdi, 0
mov rax, SYS_brk
syscall
mov rdi, rax
add rdi, CAPACITY
mov rax, SYS_brk
syscall
...
...
Ao analisarmos com gdb:
# Breakpoint na primeira syscall
(gdb) b 18
(gdb) run
# Executa a linha da syscall
(gdb) n
# Em RAX a syscall armazena o endereço do program break, no caso
# 0x403000
(gdb) i r rax
rax 0x403000 4206592
(gdb) x 0x403000
0x403000: Cannot access memory at address 0x403000
Neste momento, este endereço ainda não é acessível pois não reservamos novos bytes no heap. Vamos andar com a próxima syscall:
(gdb) n
(gdb) n
# Antes de executar a syscall, verificamos que o argumento RDI vai
# conter o endereço desejado para o novo program break, no caso com
# 3 bytes adicionados, 0x403003
(gdb) i r rdi
rdi 0x403003 4206595
# Executa a syscall...
(gdb) n
(gdb) n
# Após a execução da segunda syscall, vemos que em RAX, o program break foi alterado para 0x403003
(gdb) i r rax
rax 0x403003 4206595
Agora, podemos acessar os endereços de memória entre 0x403000 e 0x403003:
(gdb) x 0x403000
0x403000: 0x00000000
(gdb) x 0x403001
0x403001: 0x00000000
(gdb) x 0x403002
0x403002: 0x00000000
(gdb) x 0x403003
0x403003: 0x00000000
Uau! Agora temos no heap uma área reservada especialmente para o nosso querido array, olha que coisa!
Como vamos manipular o array nesta região da memória?
Ponteiros, ponteiros everywhere
Após a primeira syscall, devemos pegar o endereço de memória 0x403000 que representa o primeiro program break e armazenar no ponteiro do array que está em .bss:
...
mov rdi, 0
mov rax, SYS_brk
syscall
mov [array], rax ; <---- breakpoint aqui
mov rdi, rax
add rdi, CAPACITY
mov rax, SYS_brk
syscall
...
Vamos verificar com gdb o breakpoint na linha que muda o ponteiro do array:
(gdb) b 19
(gdb) run
(gdb) x &array
0x402004 <array>: 0x00000000
# Executa a linha que muda o ponteiro
(gdb) n
# Agora o ponteiro aponta para o endereço 0x403000,
# é isto o que queremos
(gdb) x &array
0x402004 <array>: 0x00403000
Importante notar que array está no endereço 0x402004, na seção .bss, pelo que seu valor representa outro endereço de memória 0x403000 que é onde deve começar o primeiro elemento do array no heap.
Agora, quando fizermos a próxima syscall para alocar 3 bytes no heap, o program break será modificado e iremos conseguir manipular o array pois o ponteiro já aponta para o endereço correto.
Após a segunda syscall, já não podemos mais manipular o array pelo seu valor, pois agora o valor do array já não é mais um elemento de fato, mas sim um endereço para outro lugar na memória.
Vamos ao programa na versão atual:
global _start
%define SYS_brk 12
%define SYS_exit 60
%define EXIT_SUCCESS 0
%define CAPACITY 3
section .bss
array: resb 1 ; 0x403000
section .data
pointer: db 0
section .text
_start:
mov rdi, 0
mov rax, SYS_brk
syscall
mov [array], rax
mov rdi, rax
add rdi, CAPACITY
mov rax, SYS_brk
syscall
mov rbx, [array]
mov r8, 1
call .append
mov r8, 2
call .append
mov r8, 3
call .append
mov r8, 4
call .append
.exit:
mov rdi, EXIT_SUCCESS
mov rax, SYS_exit
syscall
.append:
cmp byte [pointer], CAPACITY ; verifica se o array está cheio
je .done
mov sil, byte [pointer]
mov byte [rbx + rsi], r8b
inc byte [pointer]
.done:
ret
Explicando cada bloco:
mov rdi, 0
mov rax, SYS_brk
syscall
mov [array], rax
- busca o program break atual e armazena o endereço no ponteiro
array
mov rdi, rax
add rdi, CAPACITY
mov rax, SYS_brk
syscall
- modifica o program break atual, incrementando 3 bytes que é a capacidade inicial do array no heap
; atribuir ao registrador o endereço de memória ao qual o
; ponteiro "array" está apontando
mov rbx, [array]
- armazena o endereço de memória do ponteiro no registrador RBX. Isto é necessário pois não queremos fazer aritmética diretamente no ponteiro da seção
.bss, mas sim através de um registrador que permite
mov r8, 1
call .append
- como agora o RDI foi usado como argumento na syscall brk, não convém mais utilizarmos este registrador para representar o elemento a ser adicionado no array, pelo que trocamos pelo registrador R8
.append:
cmp byte [pointer], CAPACITY ; verifica se o array está cheio
je .done
mov sil, byte [pointer]
mov byte [rbx + rsi], r8b ; indirect-mode addressing
inc byte [pointer]
.done:
ret
Agora a rotina .append foi modificado para que a manipulação do array no heap seja através do registrador RBX. Também não podemos mais usar o registrador RAX para representar o ponteiro pois a syscall brk também utilizou como retorno do program break; neste caso trocamos para o RSI (que tem o SIL como sua representação de 8-bits menores).
Ao executar com gdb, podemos verificar que os elementos estão sendo adicionados no endereço 0x403000 que fica no heap, através do ponteiro que foi armazenado no registrador RBX:
# Array aponta para o endereço 0x403000
(gdb) x &array
0x402004 <array>: 0x00403000
# No endereço, temos os elementos adicionados. Yay!
(gdb) x 0x403000
0x403000: 0x00030201
# E o ponteiro de "índice" corretamente representando o fim do array no heap
(gdb) x &pointer
0x402000 <pointer>: 0x00000003
Neste momento, o programa está com o mesmo comportamento do exemplo anterior com array estático em .bss, não permitindo adicionar mais elementos quando o array atinge seu limite.
Vamos mudar isto, redimensionando o array e permitir que novos elementos sejam adicionados.
Resize com brk
A seguir, iniciamos os passos para que o redimensionamento do array seja feito quando este atingir o limite da capacidade. Começamos por alterar a rotina .append:
.append:
cmp byte [pointer], CAPACITY ; verifica se o array está cheio
je .resize
mov sil, byte [pointer]
mov byte [rbx + rsi], r8b
inc byte [pointer]
.done:
ret
.resize:
...
Ao invés de fazer jump para .done quando o array estiver cheio, fazemos jump para outra sub-rotina chamada .resize, que deverá fazer a syscall brk novamente, modificando assim o program break em uma nova área na memória, obedecendo a capacidade inicial do array:
.append:
cmp byte [pointer], CAPACITY ; verifica se o array está cheio
je .resize
mov sil, byte [pointer]
mov byte [rbx + rsi], r8b
inc byte [pointer]
.done:
ret
.resize:
mov rdi, 0
mov rax, SYS_brk
syscall
mov rdi, rax ; RDI passa a representar o break atual
add rdi, CAPACITY ; adiciona 3 bytes, ficando 0x403006
mov rax, SYS_brk
syscall
jmp .append
- a primeira syscall de resize traz o break atual, no caso já sabemos que é
0x403003, que foi alocado no início do programa para o array - a segunda syscall de resize modifica o break atual, alocando assim mais 3 bytes no heap
- ao fim do resize, ao invés de retornar a função, vamos voltar para o início do
.appende executar a lógica necessária para adicionar o elemento no array
Desta forma, podemos manipular esta nova área na memória para adicionar mais elementos no array, modificando assim sua capacidade dinamicamente.
Se executarmos o programa exatamente assim, vamos enfrentar um problema, pois:
- a cada vez que é feito o resize, salta para o início da rotina
- é verificado o tamanho do array (pointeiro) com a capacidade inicial, que no caso é 3. Como o ponteiro atingiu o valor 3, então vai entrar novamente no resize caracterizando assim um loop infinito com resize infinito até acabar a memória
Para resolver isto, precisamos comparar o pointer com a capacidade atual (modificada), e portanto vamos adicionar um valor na seção .data que representa a capacidade atual:
%define CAPACITY 3
section .data
pointer: db 0
currentCapacity: db CAPACITY ; começa com 3
Na rotina .append, vamos fazer a comparação com o currentCapacity, que vai ser modificado a cada resize, ao invés de ser com CAPACITY, que vai permanecer fixo com o valor inicial enquanto durar o programa.
.append:
mov r9, [currentCapacity]
cmp byte [pointer], r9b ; verifica se o array está cheio
je .resize
...
E, após o redimensionamento antes de voltar pro .append, vamos incrementar o valor da capacidade inicial à capacidade atual:
.resize:
mov rdi, 0
mov rax, SYS_brk
syscall
mov rdi, rax
add rdi, CAPACITY
mov rax, SYS_brk
syscall
mov r10, currentCapacity
add byte [r10], CAPACITY
jmp .append
Ao executar o programa, podemos ver que o elemento 4 foi adicionado com sucesso no array após o redimensionamento:
(gdb) x 0x403000
0x403000: 0x04030201
E se adicionarmos mais e mais elementos?
...
mov r8, 4
call .append
mov r8, 5
call .append
mov r8, 6
call .append
mov r8, 7
call .append
...
# Podemos ver que o currentCapacity é 9, ou seja, foram feitos
# 2 redimensionamentos. Nosso array consegue agora acomodar até 9 elementos,
# pelo que ao adicionar o décimo elemento, mais um resize seria feito.
(gdb) x ¤tCapacity
0x402001 <currentCapacity>: 0x09
# Buscando os 9 primeiros hexabytes no endereço do array no heap
(gdb) x/9xb 0x403000
0x403000: 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x00
0x403008: 0x00
How cool is that?
O programa final
A seguir o programa final, com um array de capacidade inicial de 3 elementos no heap que pode ser redimensionado utilizando a syscall brk, conforme mais elementos vão sendo adicionados no array:
global _start
%define SYS_brk 12
%define SYS_exit 60
%define EXIT_SUCCESS 0
%define CAPACITY 3
section .bss
array: resb 1
section .data
pointer: db 0
currentCapacity: db CAPACITY ; capacidade inicial é 3
section .text
_start:
mov rdi, 0
mov rax, SYS_brk
syscall
mov [array], rax
mov rdi, rax
add rdi, CAPACITY
mov rax, SYS_brk
syscall
mov rbx, [array]
mov r8, 1
call .append
mov r8, 2
call .append
mov r8, 3
call .append
mov r8, 4
call .append
mov r8, 5
call .append
mov r8, 6
call .append
mov r8, 7
call .append
.exit:
mov rdi, EXIT_SUCCESS
mov rax, SYS_exit
syscall
.append:
mov r9, [currentCapacity]
cmp byte [pointer], r9b ; verifica se o array está cheio
je .resize
mov sil, byte [pointer]
mov byte [rbx + rsi], r8b
inc byte [pointer]
.done:
ret
.resize:
mov rdi, 0
mov rax, SYS_brk
syscall
mov rdi, rax
add rdi, CAPACITY
mov rax, SYS_brk
syscall
mov r10, currentCapacity
add byte [r10], CAPACITY
jmp .append
Conclusão
Neste artigo, mostramos a implementação de um array em Assembly x86, passando por conceitos importantes como layout de memória, manipulação de registradores e alocação dinâmica de memória com brk.
Este artigo é base para artigos futuros sobre estruturas de dados, onde pretendo escrever sobre a implementação de filas e posteriormente listas ligadas.
Stay tuned!
Referências
Addressing modes
https://www.tutorialspoint.com/assembly_programming/assembly_addressing_modes.htm
Syscall brk
https://man7.org/linux/man-pages/man2/brk.2.html
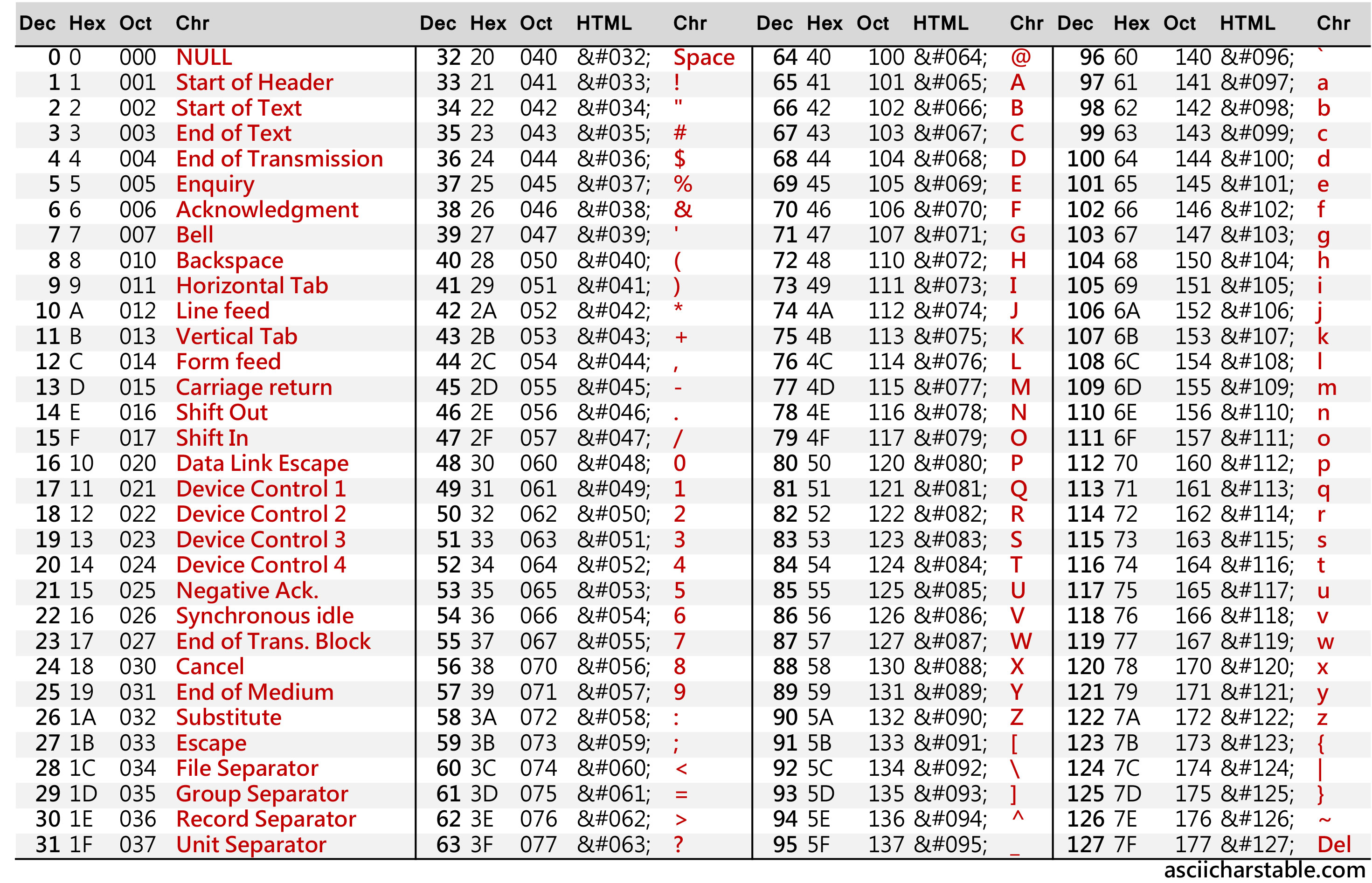
ASCII table
https://www.asciicharstable.com/_site_media/ascii/ascii-chars-table-landscape.jpg
{kind=link}
This content originally appeared on DEV Community and was authored by Leandro Proença
Leandro Proença | Sciencx (2024-08-17T21:49:05+00:00) Arrays em Assembly x86. Retrieved from https://www.scien.cx/2024/08/17/arrays-em-assembly-x86/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.