
This content originally appeared on Chromium Blog and was authored by Chromium Blog
PartitionAlloc is Chromium’s memory allocator, designed for lower fragmentation, higher speed, and stronger security and has been used extensively within Blink (Chromium’s rendering engine). In Chrome 89 the entire Chromium codebase transitioned to using PartitionAlloc everywhere (by intercepting and replacing malloc() and new) on Windows 64-bit and Android. Data from the field demonstrates up to 22% memory savings, and up to 9% improvement in responsiveness and scroll latency of Chrome.
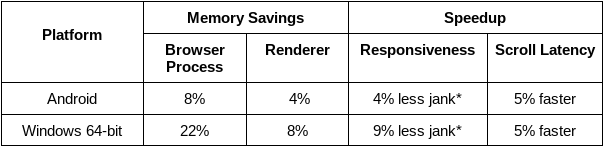
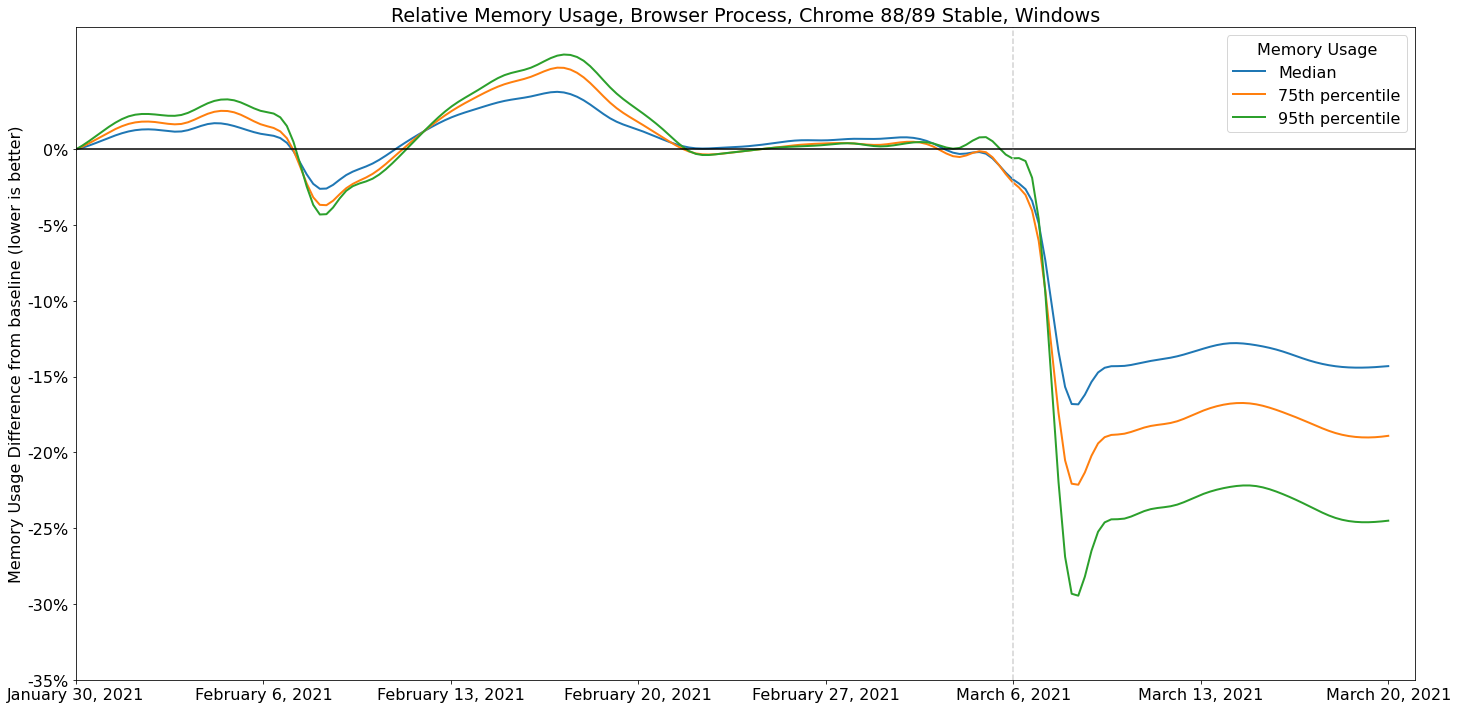
Here's a closer look at memory usage in the browser process for Windows as the M89 release began rolling out in early March:
Background
When we started this project, our goals were to: 1) unify memory allocation across platforms, 2) target the lowest memory footprint without compromising security and performance, and 3) tailor the allocator to optimize the performance of Chrome. Thus we made the decision to use Chromium’s cross-platform allocator, to optimize memory usage for client rather than server workloads and to focus on meaningful end user activities, not micro-benchmarks that wouldn’t really matter in real world usage.
Allocator Security
Additionally, PartitionAlloc protects some of its metadata with guard pages (inaccessible ranges) around memory regions. Not all metadata is equal, however: free-list entries are stored within previously allocated regions, and thus surrounded by other allocations. To detect corrupted free-list entries and off-by-one overflows from client code, we encode and shadow them.
Finally, having our own allocator enables advanced security features like MiraclePtr and *Scan.
Architecture Details
Each partition in PartitionAlloc uses a single, central, slab-based allocator to conserve memory, with a minimal per-thread cache in front for scaling to multi-threaded workloads. This simplicity also pays performance dividends: we’ve extensively profiled and aggressively trimmed the allocator’s fast path, improving thread-local storage access, locks, reducing cache line fetches, and removing branches.
PartitionAlloc pre-reserves slabs of virtual address space. They are gradually backed by physical memory, as allocation requests arrive. Small and medium-sized allocations are grouped in geometrically-spaced, size-segregated buckets, e.g. [241; 256], [257; 288]. Each slab is split into regions (called “slot spans”) that satisfy allocations (“slots”) from only one particular bucket, thereby increasing cache locality while lowering fragmentation. Conversely, larger allocations don’t go through the bucket logic and are fulfilled using the operating system’s primitives directly (mmap() on POSIX systems, and VirtualAlloc() on Windows).
This central allocator is protected by a single per-partition lock. To mitigate the scalability problem arising from contention, we add a small, per-thread cache of small slots in front, yielding a three-tiered architecture:
PartitionAlloc pre-reserves slabs of virtual address space. They are gradually backed by physical memory, as allocation requests arrive. Small and medium-sized allocations are grouped in geometrically-spaced, size-segregated buckets, e.g. [241; 256], [257; 288]. Each slab is split into regions (called “slot spans”) that satisfy allocations (“slots”) from only one particular bucket, thereby increasing cache locality while lowering fragmentation. Conversely, larger allocations don’t go through the bucket logic and are fulfilled using the operating system’s primitives directly (mmap() on POSIX systems, and VirtualAlloc() on Windows).
This central allocator is protected by a single per-partition lock. To mitigate the scalability problem arising from contention, we add a small, per-thread cache of small slots in front, yielding a three-tiered architecture:

The second layer (Slot span free-lists) is invoked upon a per-thread cache miss. For each bucket size, PartitionAlloc knows a slot span with free slots associated with that size, and captures a slot from the free-list of that span. This is still a fast path, but slower than per-thread cache as it requires taking a lock. However, this section is only hit for larger allocations not supported by per-thread cache, or as a batch to fill the per-thread cache.
Finally, if there are no free slots in the bucket, the third layer (Slot span management) either carves out space from a slab for a new slot span, or allocates an entirely new slab from the operating system, which is a slow but very infrequent operation.
The overall performance and space-efficiency of the allocator hinges on the many tradeoffs across its layers such as how much to cache, how many buckets, and memory reclaiming policy. Please refer to PartitionAlloc to learn more about the design.
All in all, we hope you will enjoy the additional memory savings and performance improvements brought by PartitionAlloc, ensuring a safer, leaner, and faster Chrome for users on Earth and in outer space alike. Stay tuned for further improvements, and support of more platforms coming in the near future.
Posted by Benoît Lizé and Bartek Nowierski, Chrome Software Engineers
Data source for all statistics: Real-world data anonymously aggregated from Chrome clients.
*The core metric measures jank -- delay handling user input -- every 30 seconds.
This content originally appeared on Chromium Blog and was authored by Chromium Blog
Print
Share
Comment
Cite
Upload
Translate
Updates

There are no updates yet.
Click the Upload button above to add an update.
APA
MLA
Chromium Blog | Sciencx (2021-04-12T18:43:00+00:00) Efficient And Safe Allocations Everywhere!. Retrieved from https://www.scien.cx/2021/04/12/efficient-and-safe-allocations-everywhere/
" » Efficient And Safe Allocations Everywhere!." Chromium Blog | Sciencx - Monday April 12, 2021, https://www.scien.cx/2021/04/12/efficient-and-safe-allocations-everywhere/
HARVARDChromium Blog | Sciencx Monday April 12, 2021 » Efficient And Safe Allocations Everywhere!., viewed ,<https://www.scien.cx/2021/04/12/efficient-and-safe-allocations-everywhere/>
VANCOUVERChromium Blog | Sciencx - » Efficient And Safe Allocations Everywhere!. [Internet]. [Accessed ]. Available from: https://www.scien.cx/2021/04/12/efficient-and-safe-allocations-everywhere/
CHICAGO" » Efficient And Safe Allocations Everywhere!." Chromium Blog | Sciencx - Accessed . https://www.scien.cx/2021/04/12/efficient-and-safe-allocations-everywhere/
IEEE" » Efficient And Safe Allocations Everywhere!." Chromium Blog | Sciencx [Online]. Available: https://www.scien.cx/2021/04/12/efficient-and-safe-allocations-everywhere/. [Accessed: ]
rf:citation » Efficient And Safe Allocations Everywhere! | Chromium Blog | Sciencx | https://www.scien.cx/2021/04/12/efficient-and-safe-allocations-everywhere/ |
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.