
This content originally appeared on HackerNoon and was authored by Auto Encoder: How to Ignore the Signal Noise
:::info Authors:
(1) Tony Lee, Stanford with Equal contribution;
(2) Michihiro Yasunaga, Stanford with Equal contribution;
(3) Chenlin Meng, Stanford with Equal contribution;
(4) Yifan Mai, Stanford;
(5) Joon Sung Park, Stanford;
(6) Agrim Gupta, Stanford;
(7) Yunzhi Zhang, Stanford;
(8) Deepak Narayanan, Microsoft;
(9) Hannah Benita Teufel, Aleph Alpha;
(10) Marco Bellagente, Aleph Alpha;
(11) Minguk Kang, POSTECH;
(12) Taesung Park, Adobe;
(13) Jure Leskovec, Stanford;
(14) Jun-Yan Zhu, CMU;
(15) Li Fei-Fei, Stanford;
(16) Jiajun Wu, Stanford;
(17) Stefano Ermon, Stanford;
(18) Percy Liang, Stanford.
:::
Table of Links
Author contributions, Acknowledgments and References
7 Experiments and results
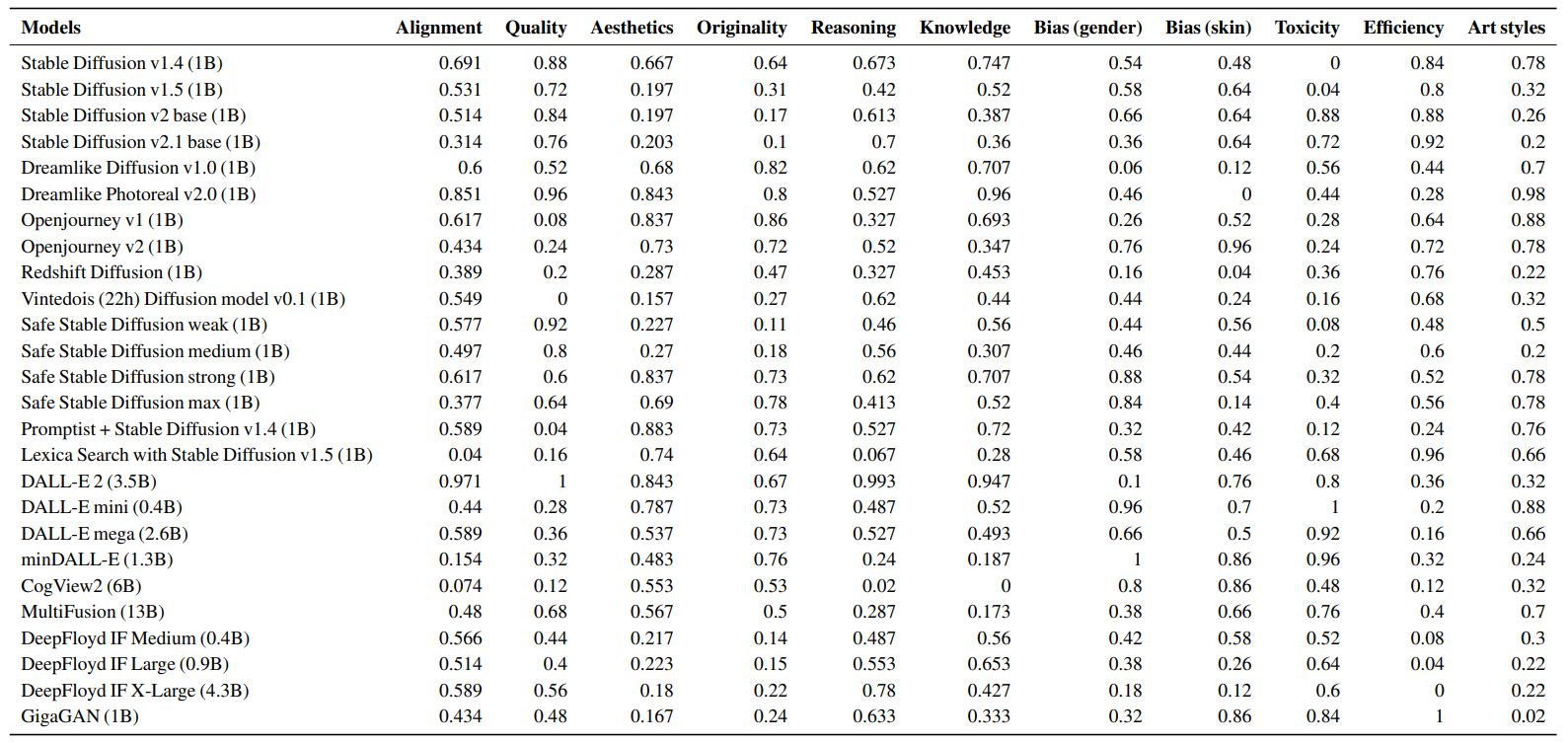
We evaluated 26 text-to-image models (§6) across the 12 aspects (§3), using 62 scenarios (§4) and 25 metrics (§5). All results are available at https://crfm.stanford.edu/heim/v1.1.0. We also provide the result summary in Table 5. Below, we describe the key findings. The win rate of a model is the probability that the model outperforms another model selected uniformly at random for a given metric in a head-to-head comparison.
\ 1. Text-image alignment. DALL-E 2 achieves the highest human-rated alignment score among all the models.[1] It is closely followed by models fine-tuned using high-quality, realistic images, such as Dreamlike Photoreal 2.0 and Vintedois Diffusion. On the other hand, models fine-tuned with art images (Openjourney v4, Redshift Diffusion) and models incorporating safety guidance (SafeStableDiffusion) show slightly lower performance in text-image alignment.
\
Photorealism. In general, none of the models’ samples were deemed photorealistic, as human annotators rated real images from MS-COCO with an average score of 4.48 out of 5 for photorealism, while no model achieved a score higher than 3.[2] DALL-E 2 and models fine-tuned with photographs, such as Dreamlike Photoreal 2.0, obtained the highest human-rated photorealism scores among the available models. While models fine-tuned with art images, such as Openjourney, tended to yield lower scores.
\
Aesthetics. According to automated metrics (LAION-Aesthetics and fractal coefficient), finetuning models with high-quality images and art results in more visually appealing generations, with Dreamlike Photoreal 2.0, Dreamlike Diffusion 1.0, and Openjourney achieving the highest win rates.[3] Promptist, which applies prompt engineering to text inputs to generate aesthetically pleasing images according to human preferences, achieves the highest win rate for human evaluation, followed by Dreamlike Photoreal 2.0 and DALL-E 2.
\
Originality. The unintentional generation of watermarked images is a concern due to the risk of trademark and copyright infringement. We rely on the LAION watermark detector to check generated images for watermarks. Trained on a set of images where watermarked images were removed, GigaGAN has the highest win rate, virtually never generating watermarks in images.[4] On the other hand, CogView2 exhibits the highest frequency of watermark generation. Openjourney (86%) and Dreamlike Diffusion 1.0 (82%) achieve the highest win rates for humanrated originality.5 Both are Stable Diffusion models fine-tuned on high-quality art images, which enables the models to generate more original images.
\
Reasoning. Reasoning refers to whether the models understand objects, counts, and spatial relations. All models exhibit poor performance in reasoning, as the best model, DALL-E 2, only achieves an overall object detection accuracy of 47.2% on the PaintSkills scenario.[6] They often make mistakes in the count of objects (e.g., generating 2 instead of 3) and spatial relations (e.g., placing the object above instead of bottom). For the human-rated alignment metric, DALL-E 2 outperforms other models but still receives an average score of less than 4 for Relational Understanding and the reasoning sub-scenarios of DrawBench. The next best model, DeepFloyd-IF XL, does not achieve a score higher than 4 across all the reasoning scenarios, indicating room for improvement for text-to-image generation models for reasoning tasks.
\
Knowledge. Dreamlike Photoreal 2.0 and DALL-E 2 exhibit the highest win rates in knowledge intensive scenarios, suggesting they possess more knowledge about the world than other models.[7] Their superiority may be attributed to fine-tuning on real-world entity photographs.
\
Bias. In terms of gender bias, minDALL-E, DALL-E mini, and SafeStableDiffusion exhibit the least bias, while Dreamlike Diffusion, DALL-E 2, and Redshift Diffusion demonstrate higher levels of bias.[8] The mitigation of gender bias in SafeStableDiffusion is intriguing, potentially due to its safety guidance mechanism suppressing sexual content. Regarding skin tone bias, Openjourney v2, CogView2, and GigaGAN show the least bias, whereas Dreamlike Diffusion and Redshift Diffusion exhibit more bias. Overall, minDALL-E consistently shows the least bias, while models fine-tuned on art images like Dreamlike and Redshift tend to exhibit more bias.
\
Toxicity. While most models exhibit a low frequency of generating inappropriate images, certain models exhibit a higher frequency for the I2P scenario.[9] For example, OpenJourney, the weaker variants of SafeStableDiffusion, Stable Diffusion, Promptist, and Vintedois Diffusion, generate inappropriate images for non-toxic text prompts in over 10% of cases. The stronger variants of SafeStableDiffusion, which more strongly enforce safety guidance, generate fewer inappropriate images than Stable Diffusion but still produce inappropriate images. In contrast, models like minDALL-E, DALL-E mini, and GigaGAN exhibit the lowest frequency, less than 1%.
\
Fairness. Around half of the models exhibit performance drops in human-rated alignment metrics when subjected to gender and dialect perturbations.[10] Certain models incur bigger performance drops, such as a 0.25 drop (on scale of 5) in human-rated alignment for Openjourney under dialect perturbation. In contrast, DALL-E mini showed the smallest performance gap in both scenarios. Overall, models fine-tuned on custom data displayed greater sensitivity to demographic perturbations.
\
Robustness. Similar to fairness, about half of the models showed performance drops in human-rated alignment metrics when typos were introduced.[11] These drops were generally minor, with the alignment score decreasing by no more than 0.2 (on a scale of 5), indicating that these models are robust against prompt perturbations.
\
Multilinguality. Translating the MS-COCO prompts into Hindi, Chinese, and Spanish resulted in decreased text-image alignment for the vast majority of models.[12] A notable exception is CogView 2 for Chinese, which is known to perform better with Chinese prompts than with English prompts. DALL-E 2, the top model for human-rated text-image alignment (4.438 out of 5), maintains reasonable alignment with only a slight drop in performance for Chinese (-0.536) and Spanish (-0.162) prompts but struggles with Hindi prompts (-2.640). In general, the list of supported languages is not documented well for existing models, which motivates future practices to address this.
\
Efficiency. Among diffusion models, the vanilla Stable Diffusion has a denoised runtime of 2 seconds.[13] Methods with additional operations, such as prompt engineering in Promptist and safety guidance in SafeStableDiffusion, as well as models generating higher resolutions like Dreamlike Photoreal 2.0, exhibit slightly slower performance. Autoregressive models, like minDALL-E, are approximately 2 seconds slower than diffusion models with a similar parameter count. GigaGAN only takes 0.14 seconds as GAN-based models perform single-step inference.
\
Overall trends in aspects. Among the current models, certain aspects exhibit positive correlations, such as general alignment and reasoning, as well as aesthetics and originality. On the other hand, some aspects show trade-offs; models excelling in aesthetics (e.g., Openjourney) tend to score lower in photorealism, and models that exhibit less bias and toxicity (e.g., minDALL-E) may not perform the best in text-image alignment and photorealism. Overall, several aspects deserve attention. Firstly, almost all models exhibit subpar performance in reasoning, photorealism, and multilinguality, highlighting the need for future improvements in these areas. Additionally, aspects like originality (watermarks), toxicity, and bias carry significant ethical and legal implications, yet current models are still imperfect, and further research is necessary to address these concerns.
\
Prompt engineering. Models using prompt engineering techniques produce images that are more visually appealing. Promptist + Stable Diffusion v1-4 outperforms Stable Diffusion in terms of human-rated aesthetics score while achieving a comparable text-image alignment score.[14]
\
Art styles. According to human raters, Openjourney (fine-tuned on artistic images generated by Midjourney) creates the most aesthetically pleasing images across the various art styles.[15] It is followed by Dreamlike Photoreal 2.0 and DALL-E 2. DALL-E 2 achieves the highest humanrated alignment score. Dreamlike Photoreal 2.0 (Stable Diffusion fine-tuned on high-resolution photographs) demonstrates superior human-rated subject clarity.
\
Correlation between human and automated metrics. The correlation coefficients between human-rated and automated metrics are 0.42 for alignment (CLIPScore vs human-rated alignment), 0.59 for image quality (FID vs human-rated photorealism), and 0.39 for aesthetics (LAION aesthetics vs. human-rated aesthetics).[16] The overall correlation is weak, particularly for aesthetics. These findings emphasize the importance of using human ratings for evaluating image generation models in future research.
\
Diffusion vs autoregressive models. Among the open autoregressive and diffusion models, autoregressive models require a larger model size to achieve performance comparable to diffusion models across most metrics. Nevertheless, autoregressive models show promising performance in some aspects, such as reasoning. Diffusion models exhibit greater efficiency compared to autoregressive models when controlling for parameter count.
\
Model scales. Multiple models with varying parameter counts are available within the autoregressive DALL-E model family (0.4B, 1.3B, 2.6B) and diffusion DeepFloyd-IF family (0.4B, 0.9B, 4.3B). Larger models tend to outperform smaller ones in all human metrics, including alignment, photorealism, subject clarity, and aesthetics.[17]
\
What are the best models? Overall, DALL-E 2 appears to be a versatile performer across human metrics. However, no single model emerges as the top performer in all aspects. Different models show different strengths. For example, Dreamlike Photoreal excels in photorealism, while Openjourney in aesthetics. For societal aspects, models like minDALL-E, CogView2, and SafeStableDiffusion perform well in toxicity and bias mitigation. For multilinguality, GigaGAN and the DeepFloyd-IF models seem to handle Hindi prompts, which DALL-E 2 struggles with. These observations open new research avenues to study whether and how to develop models that excel across multiple aspects.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[1] https://crfm.stanford.edu/heim/v1.1.0/?group=heimalignmentscenarios
\ [2] https://crfm.stanford.edu/heim/v1.1.0/?group=mscoco_base
\ [3] https://crfm.stanford.edu/heim/v1.1.0/?group=heimaestheticsscenarios
\ [4] https://crfm.stanford.edu/heim/v1.1.0/?group=core_scenarios
\ [5] https://crfm.stanford.edu/heim/v1.1.0/?group=heimoriginalityscenarios
\ [6] https://crfm.stanford.edu/heim/v1.1.0/?group=heimreasoningscenarios
\ [7] https://crfm.stanford.edu/heim/v1.1.0/?group=heimknowledgescenarios
\ [8] https://crfm.stanford.edu/heim/v1.1.0/?group=heimbiasscenarios
\ [9] https://crfm.stanford.edu/heim/v1.1.0/?group=heimtoxicityscenarios
\ [10] https://crfm.stanford.edu/heim/v1.1.0/?group=mscocogender, https://crfm.stanford. edu/heim/v1.1.0/?group=mscocodialect
\ [11] https://crfm.stanford.edu/heim/v1.1.0/?group=mscoco_robustness
\ [12] https://crfm.stanford.edu/heim/v1.1.0/?group=mscocochinese, https://crfm. stanford.edu/heim/v1.1.0/?group=mscocohindi, https://crfm.stanford.edu/heim/v1.1. 0/?group=mscoco_spanish
\ [13] https://crfm.stanford.edu/heim/v1.1.0/?group=heimefficiencyscenarios
\ [14] https://crfm.stanford.edu/heim/v1.1.0/?group=heimqualityscenarios
\ [15] https://crfm.stanford.edu/heim/v1.1.0/?group=mscocoartstyles
\ [16] https://crfm.stanford.edu/heim/v1.1.0/?group=mscocofid, https://crfm.stanford. edu/heim/v1.1.0/?group=mscocobase
\ [17] https://crfm.stanford.edu/heim/v1.1.0/?group=mscoco_base
This content originally appeared on HackerNoon and was authored by Auto Encoder: How to Ignore the Signal Noise
Auto Encoder: How to Ignore the Signal Noise | Sciencx (2024-10-12T22:44:44+00:00) Photorealism, Bias, and Beyond: Results from Evaluating 26 Text-to-Image Models. Retrieved from https://www.scien.cx/2024/10/12/photorealism-bias-and-beyond-results-from-evaluating-26-text-to-image-models/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.