
This content originally appeared on HackerNoon and was authored by Abhishek Gupta
\ To continue our exploration of stream processing, let’s review key terms that will provide a foundation for selecting the right windowing method for your application.
\ A streaming system, or stream processing system, processes data in real-time as it is generated or received. Unlike batch processing, which handles data in large, discrete chunks, streaming systems manage data as a continuous flow, allowing for immediate analysis and action.
\ Bounded data represents finite datasets with a clear beginning and end, and is often more suitable for batch processing (e.g. files, databases, historical records). Processing bounded data is simpler and more predictable but may introduce latency, especially for large datasets.
\ Unbounded data refers to continuous streams of data generated from sources that require real-time or near-real-time processing for timely insights. Stream processing frameworks like Apache Kafka, Apache Flink, Apache Storm, and others are designed to handle unbounded data, providing low-latency, scalable, and fault-tolerant solutions.
\ In the context of stream processing, event time and processing time are two important concepts that refer to different timestamps associated with data:
Event Time
The time an event actually occurs, as recorded by the source. This timestamp is typically embedded in the data itself. Event time is important for applications that require accurate time-based analysis like historical trend analysis, time-series data processing, and windowed aggregations. Systems must be able to manage out-of-order events and ensure accurate clock synchronization.
Processing Time
The time an event is processed by the system, based on the internal clock. This timestamp is generated by the system's internal clock at the moment the event is processed. Processing time is useful for applications where the time of data arrival and processing is more important than the actual occurrence time, such as real-time monitoring and alerting. There are some reliability risks due to potential delays in data arrival or external factors, like system load and network latency, at time of processing. \n
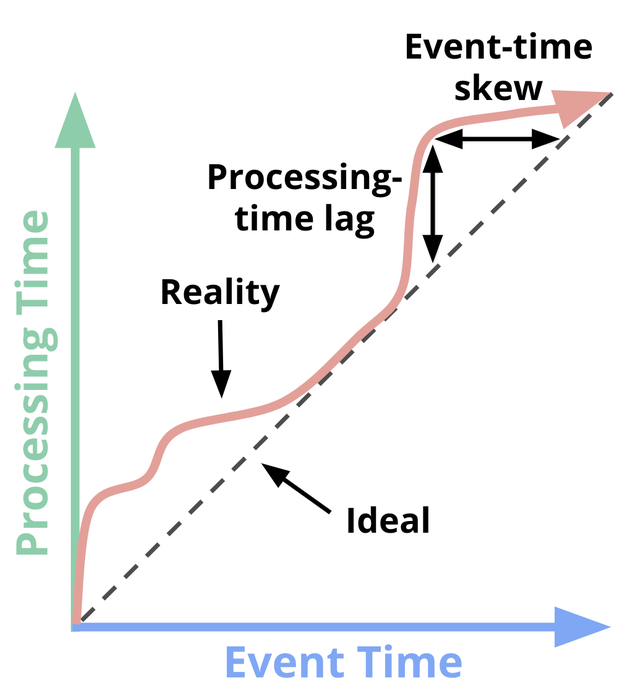
The above figure visualizes time-domain mapping, showing event time on the X-axis (showing when events are generated) and processing time on the Y-axis (indicating when the system processes those events). Many stream processing frameworks provide mechanisms to handle both timestamps effectively.
- Apache Flink supports event time processing with watermarks and windowing functions to handle out-of-order events and perform accurate time-based computations.
- Apache Kafka Streams allows you to specify whether you want to use event time or processing time semantics, and it provides windowing support for both.
- Apache Spark Streaming supports both event time and processing time, with mechanisms to handle late data and perform windowed aggregations.
Windowing
Dividing a continuous data stream into finite segments, or "windows," allows for efficient processing and analysis over manageable data chunks. This technique forms the foundation of real-time stream processing frameworks. Understanding the demands of your data and use case will help you determine the best fit for your application.
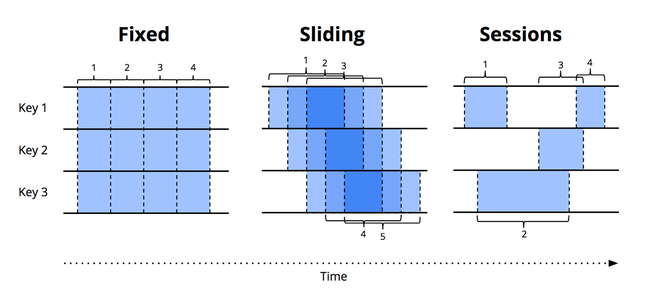
From here, we'll focus on how windowing is implemented in Apache Flink, and how programmers can best make use of the "buckets" for computation. We will cover the general structure of a windowed Flink program, and discuss the differences of keyed and non-keyed streams. Worth noting is the use of keyBy(…) for keyed streams, and windowAll(…) for non-keyed streams.
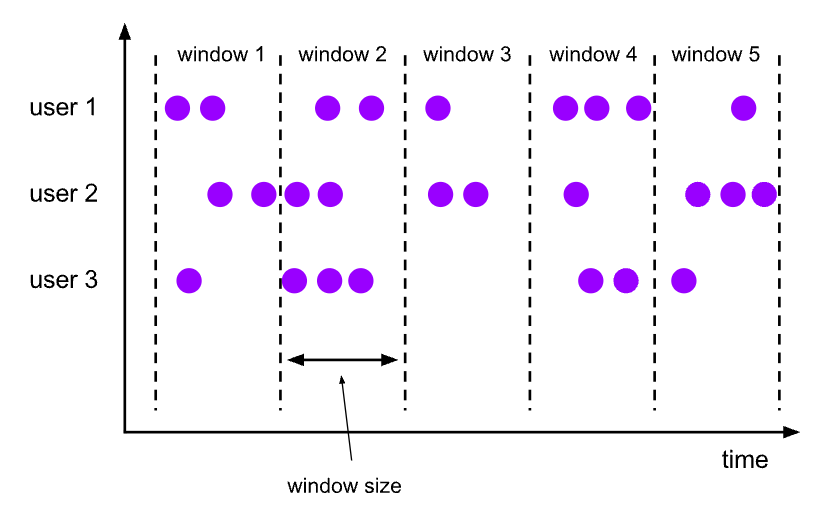
Fixed windows (aka tumbling windows)
Fixed windows divide a continuous data stream into non-overlapping, contiguous segments of equal duration. Each data point belongs to exactly one fixed window, and these windows do not overlap. For example, if you have a fixed window of 1 minute, the data stream will be divided into consecutive 1-minute intervals. Data points that arrive within each minute are grouped together into a single window, and once that minute has passed, a new window starts immediately.
\ Fixed windows have a few defining characteristics:
- Non-overlapping: Each window is distinct and does not share data points with any other window.
- Fixed duration: The length of time for each window is constant and predefined.
- Continuous: The windows cover the entire data stream without gaps.
\ Fixed windows are useful for scenarios where you need to perform periodic computations or aggregations over uniform time intervals, such as calculating the average temperature every minute or counting the number of events in each hour.
\n
Here is an example of calculating word count with a 5-minute fixed window in Apache Beam:
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.transforms.Count;
import org.apache.beam.sdk.transforms.FlatMapElements;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.beam.sdk.values.TypeDescriptors;
import org.joda.time.Duration;
import java.util.Arrays;
public class WordCountFixedWindow {
public static void main(String[] args) {
// Create the pipeline
Pipeline p = Pipeline.create();
// Apply transformations
// Read lines from an input text file.
p.apply("ReadLines", TextIO.read().from("path/to/input.txt"))
// Apply a fixed window of 5 minute to the data stream.
.apply("FixedWindow", Window.into(FixedWindows.of(Duration.standardMinutes(5))))
.apply("ExtractWords", FlatMapElements
.into(TypeDescriptors.strings())
// Split each line into words
.via((String line) -> Arrays.asList(line.split("[^\\p{L}]+"))))
.apply("PairWithOne", MapElements
.into(TypeDescriptors.kvs(TypeDescriptors.strings(), TypeDescriptors.integers()))
// Pair each word with the number 1
.via((String word) -> org.apache.beam.sdk.values.KV.of(word, 1)))
// Count the occurrences of each word.
.apply("CountWords", Count.perElement())
.apply("FormatResults", MapElements
.into(TypeDescriptors.strings())
.via((org.apache.beam.sdk.values.KV<String, Long> wordCount) ->
// Format the word count results into a string.
wordCount.getKey() + ": " + wordCount.getValue()))
// Write the formatted results to an output text file with a .txt suffix.
.apply("WriteCounts", TextIO.write().to("path/to/output").withSuffix(".txt").withoutSharding());
// Run the pipeline
p.run().waitUntilFinish();
}
}
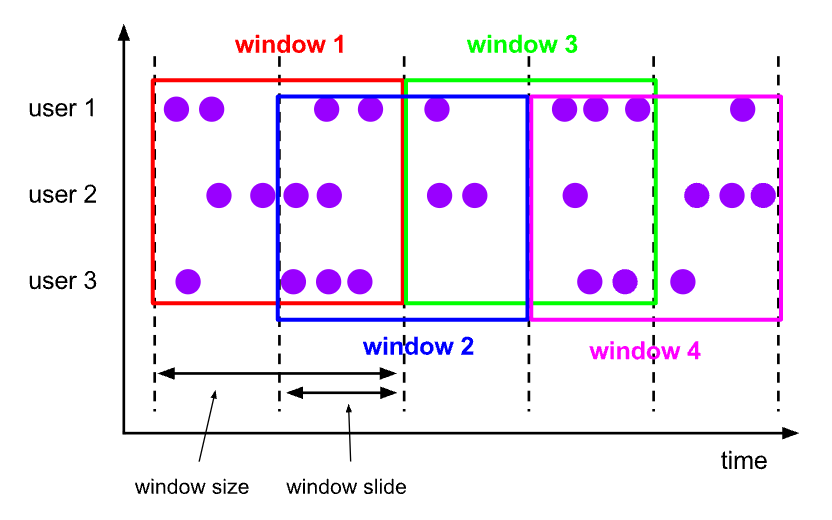
Sliding windows (aka hopping windows)
Sliding windows, unlike fixed (tumbling) windows, allow for overlapping segments of data, which means that a single data point can belong to multiple windows. Sliding windows are defined by two parameters: the window duration and the slide interval (or hop size).
\ Sliding windows have their own characteristics:
- Overlapping: Windows can overlap based on the slide interval, meaning data points can appear in multiple windows.
- Window furation: The length of time each window spans.
- Slide interval: The frequency at which new windows start, which can be shorter than the window duration, leading to overlapping windows.
\ If you have a sliding window with a duration of 1 minute and a slide interval of 30 seconds, new windows will start every 30 seconds, and each window will cover a 1-minute span. As a result, each data point will appear in two consecutive windows.
\ Sliding windows are useful in scenarios where you need more granular and overlapping insights, such as real-time monitoring and alerting systems (e.g. detecting spikes in traffic), moving averages or rolling sums, or overlapping aggregations to smooth out variations in data over time.
\ The following is an example of calculating word count with a sliding windows in Apache Beam:
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.transforms.Count;
import org.apache.beam.sdk.transforms.FlatMapElements;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.windowing.SlidingWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.beam.sdk.values.TypeDescriptors;
import org.joda.time.Duration;
import java.util.Arrays;
public class WordCountSlidingWindow {
public static void main(String[] args) {
// Create the pipeline
Pipeline p = Pipeline.create();
// Apply transformations
p.apply("ReadLines", TextIO.read().from("path/to/input.txt"))
// Apply a sliding window with a duration of 1 minute and a slide interval of 30 seconds.
.apply("SlidingWindow", Window.into(SlidingWindows.of(Duration.standardMinutes((10))
.every(Duration.standardMinutes(5))))
.apply("ExtractWords", FlatMapElements
.into(TypeDescriptors.strings())
.via((String line) -> Arrays.asList(line.split("[^\\p{L}]+"))))
.apply("PairWithOne", MapElements
.into(TypeDescriptors.kvs(TypeDescriptors.strings(), TypeDescriptors.integers()))
.via((String word) -> org.apache.beam.sdk.values.KV.of(word, 1)))
.apply("CountWords", Count.perElement())
.apply("FormatResults", MapElements
.into(TypeDescriptors.strings())
.via((org.apache.beam.sdk.values.KV<String, Long> wordCount) ->
wordCount.getKey() + ": " + wordCount.getValue()))
.apply("WriteCounts", TextIO.write().to("path/to/output").withSuffix(".txt").withoutSharding());
// Run the pipeline
p.run().waitUntilFinish();
}
}
Sessions windows
Session windows are a type of windowing strategy used in stream processing to group events that are related to each other within the same session of activity. Unlike fixed or sliding windows, session windows are dynamic and based on the actual activity in the data stream rather than fixed time intervals.
Sessions windows can be identified by these characteristics:
- Gap-based: Session windows are defined by a period of inactivity, known as the session gap. If no new events occur within this gap, the session is considered to have ended, and a new session starts with the next event.
- Dynamic length: The duration of session windows can vary based on the activity pattern in the data stream. They expand to include all events up to the point where the gap is detected.
\ Session windows are particularly useful for analyzing user activity or any other scenarios where events are naturally grouped by periods of activity followed by inactivity.
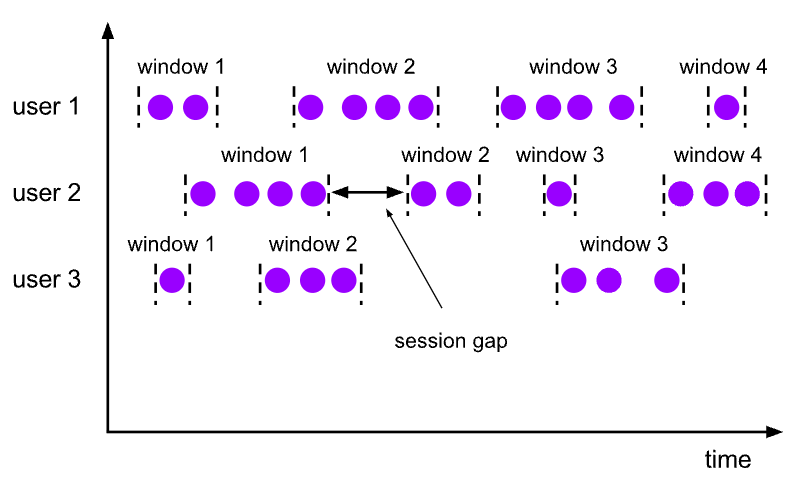
If you set a session gap of 5 minutes, events that occur within 5 minutes of each other will be grouped into the same session window. If there is a period of 5 minutes without any events, a new session window will start with the next event. Session windows are commonly used in user behavior analysis (e.g. tracking user sessions on a website), clickstream analysis, network activity monitoring, or any scenario where events are naturally grouped by periods of activity and inactivity.
\ The following is an example of calculating word count with session windows in Apache Beam:
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.transforms.Count;
import org.apache.beam.sdk.transforms.FlatMapElements;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.windowing.Sessions;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.beam.sdk.values.TypeDescriptors;
import org.joda.time.Duration;
import java.util.Arrays;
public class WordCountSessionWindow {
public static void main(String[] args) {
// Create the pipeline
Pipeline p = Pipeline.create();
// Apply transformations
p.apply("ReadLines", TextIO.read().from("path/to/input.txt"))
.apply("SessionWindow", Window.into(Sessions.withGapDuration(Duration.standardMinutes(5))))
.apply("ExtractWords", FlatMapElements
.into(TypeDescriptors.strings())
.via((String line) -> Arrays.asList(line.split("[^\\p{L}]+"))))
.apply("PairWithOne", MapElements
.into(TypeDescriptors.kvs(TypeDescriptors.strings(), TypeDescriptors.integers()))
.via((String word) -> org.apache.beam.sdk.values.KV.of(word, 1)))
.apply("CountWords", Count.perElement())
.apply("FormatResults", MapElements
.into(TypeDescriptors.strings())
.via((org.apache.beam.sdk.values.KV<String, Long> wordCount) ->
wordCount.getKey() + ": " + wordCount.getValue()))
.apply("WriteCounts", TextIO.write().to("path/to/output").withSuffix(".txt").withoutSharding());
// Run the pipeline
p.run().waitUntilFinish();
}
}
Summary
The choice between batch and streaming systems depends largely on your specific use case and the efficiency demands of your data. Batch systems excel through data bundling and shuffling, while streaming systems manage continuous data flows with windowing techniques. These strategies make it possible to perform efficient computation and aggregation over streaming data, supporting real-time analytics, monitoring, and alerting.
References
Akidau, T., Chernyak, S., & Lax, R. (2018). Streaming systems: the what, where, when, and how of large-scale data processing. " O'Reilly Media, Inc.".
https://www.oreilly.com/radar/the-world-beyond-batch-streaming-101/
\ \
This content originally appeared on HackerNoon and was authored by Abhishek Gupta
Abhishek Gupta | Sciencx (2024-11-08T08:39:17+00:00) Stream Processing – Windows. Retrieved from https://www.scien.cx/2024/11/08/stream-processing-windows/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.