
This content originally appeared on HackerNoon and was authored by Abhishek Gupta
In today's data-driven world, the ability to process and analyze vast amounts of information in real-time is not just an advantage—it's a necessity. This is where stream programming comes into play. It offers a paradigm shift from traditional batch processing methods, enabling businesses and developers to handle data streams as they occur, providing timely insights and actions. Let's delve into what stream programming is, its benefits, and how it's shaping the future of data processing.
\ The term "streaming" is often used loosely and can lead to misunderstandings. It should be precisely defined as a type of data processing engine designed for infinite data sets. This definition encompasses both true streaming and micro-batch implementations. Streaming systems are capable of producing correct, consistent, and repeatable results, contrary to the misconception that they only deliver approximate or speculative outcomes.
\
Batch processing
Batch processing involves handling large volumes of data in one go. Data is gathered over a period, stored, and then processed in bulk at scheduled intervals or when specific conditions are met. For batch processing to occur, all relevant data must be available at the start of the computation. In cases where data is unbounded, only the data available at the beginning of the computation is processed, treating it as a complete dataset. Bounded streams, which have a defined start and end, can be processed by first ingesting all the data before performing any computations. Because bounded datasets can always be sorted, ordered ingestion is not necessary. This method of handling bounded streams is commonly referred to as batch processing.
\
Stream Processing
Stream processing, in contrast, involves handling data as it arrives, enabling real-time or near-real-time data processing for immediate insights and actions. Unbounded streams have a start but no defined end, continuously generating data without termination. These streams must be processed continuously, meaning events need to be promptly handled as they are ingested. Since the input is unbounded and never complete, it is not feasible to wait for all data to arrive. Processing unbounded data often requires events to be ingested in a specific order, such as the order of occurrence, to ensure the completeness and accuracy of the results.
\
Techniques to handle unbounded data
Stream programming is particularly well-suited for handling unbounded data, which refers to data streams that have a beginning but no defined end. These streams continuously generate data, necessitating real-time or near-real-time processing. Here’s how stream programming effectively manages unbounded data:
\
Characteristics of Unbounded Data
Continuous Flow
Unlike bounded data, unbounded data streams do not terminate. Data is continuously generated and needs to be processed as it arrives. Continuous flow is a fundamental concept in unbounded stream processing, where data is processed as it arrives without waiting for the entire dataset to be available. This enables real-time or near-real-time analytics and decision-making. Practical Examples of Continuous Flow in Unbounded Stream Processing are Financial Services: Real-Time Fraud Detection, IoT and Smart Cities: Traffic Management, Healthcare: Real-Time Patient Monitoring, E-commerce and Marketing: Personalized Recommendations, Streaming entertainment: recommendation engine
Dynamic Nature
The data is always evolving, making it essential to handle it in a timely manner to extract meaningful insights. The dynamic nature of unbounded data presents unique challenges that require specialized stream processing techniques. By leveraging real-time data ingestion, event time processing, windowing operations, state management, scalability, and fault tolerance, stream processing frameworks can effectively manage the continuous flow of unbounded data. These capabilities enable real-time analytics and decision-making across various applications, from social media analytics and financial market analysis to IoT sensor monitoring. As the volume and velocity of data continue to grow, stream processing will play an increasingly critical role in harnessing the power of unbounded data for actionable insights and innovations.
\
Order Sensitivity
Events in unbounded data streams often need to be processed in the order they occur to maintain the integrity and accuracy of the analysis. Order sensitivity is a critical aspect of unbounded data in stream processing, ensuring the accuracy, consistency, and relevance of real-time analysis. By leveraging techniques like event time processing, watermarks, buffering and reordering, and stateful processing, stream processing frameworks can effectively manage the dynamic and continuous nature of unbounded data. These capabilities enable applications across various domains, from financial trading and fraud detection to IoT monitoring and real-time analytics, to derive meaningful insights and make timely decisions based on the correct sequence of events.
\
Key Components for Handling Unbounded Data with Stream Programming
Real-Time Processing Engines
Frameworks like Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, Amazon Kinesis and Apache Spark Streaming are designed to process data streams in real-time. They provide the infrastructure needed to handle continuous data flow. Real-time processing engines are essential for managing the dynamic nature of unbounded data streams. These engines provide the necessary infrastructure for real-time data ingestion, processing, and analysis, enabling timely insights and actions across various applications. By leveraging the capabilities of these engines, organizations can harness the power of unbounded data to drive innovation, efficiency, and competitiveness in today's data-driven world.
\
Event Time Processing
Stream processing frameworks allow for event time processing, which ensures that events are processed based on the actual time they occurred, rather than the time they were ingested. This is crucial for maintaining the order of events. Event time processing is a important concept in handling unbounded data streams, especially in the context of stream programming. Unlike processing time, which is based on the system clock when the event is processed, event time refers to the time at which the event actually occurred. This distinction is significant for accurately analyzing and processing data streams where timing matters
\
Windowing Operations
To manage the infinite nature of unbounded data, stream processing uses windowing operations. These operations break the data stream into manageable chunks (windows) based on time, count, or other criteria, allowing for periodic computation and analysis. Windowing operations are essential for extracting meaningful insights from continuous data streams. By segmenting the data into manageable chunks, they enable real-time analysis, aggregation, and decision-making. Understanding and leveraging different types of windows, triggers, and state management techniques allows organizations to effectively harness the power of stream processing frameworks like Apache Flink, Apache Spark Structured Streaming, and Apache Kafka Streams.
\
State Management
Stream processing frameworks offer robust state management capabilities to keep track of intermediate results and aggregated states, essential for long-running computations on unbounded data. State management is a cornerstone of advanced stream processing, enabling the handling of complex operations that depend on historical context. By leveraging stateful operations, organizations can perform real-time analytics, detect patterns, and respond to events with high accuracy and low latency. Understanding and effectively managing state in stream processing frameworks like Apache Flink, Apache Spark Structured Streaming, and Apache Kafka Streams is essential for building robust, scalable, and fault-tolerant stream processing applications.
\
Fault Tolerance
Built-in fault tolerance mechanisms ensure that the processing can recover from failures without data loss, maintaining the reliability of the system. Fault tolerance is essential for building robust and reliable stream processing applications. By implementing checkpointing, state management, and distributed coordination mechanisms, stream processing frameworks like Apache Flink, Apache Spark Structured Streaming, and Apache Kafka Streams ensure that applications can recover from failures without data loss or inconsistency. Understanding and leveraging these fault tolerance features allow organizations to build scalable, resilient, and high-performance stream processing systems.
\
Case Studies
Event-driven Applications
Event-driven applications are software systems designed to respond to events or changes in state that occur within the system or its environment. These events can be anything from user actions (like clicking a button), messages from other systems, sensor readings, or system-generated notifications. The core principle of event-driven architecture (EDA) is to decouple the components of the system, allowing them to react to events asynchronously, which leads to better scalability, maintainability, and flexibility.
\
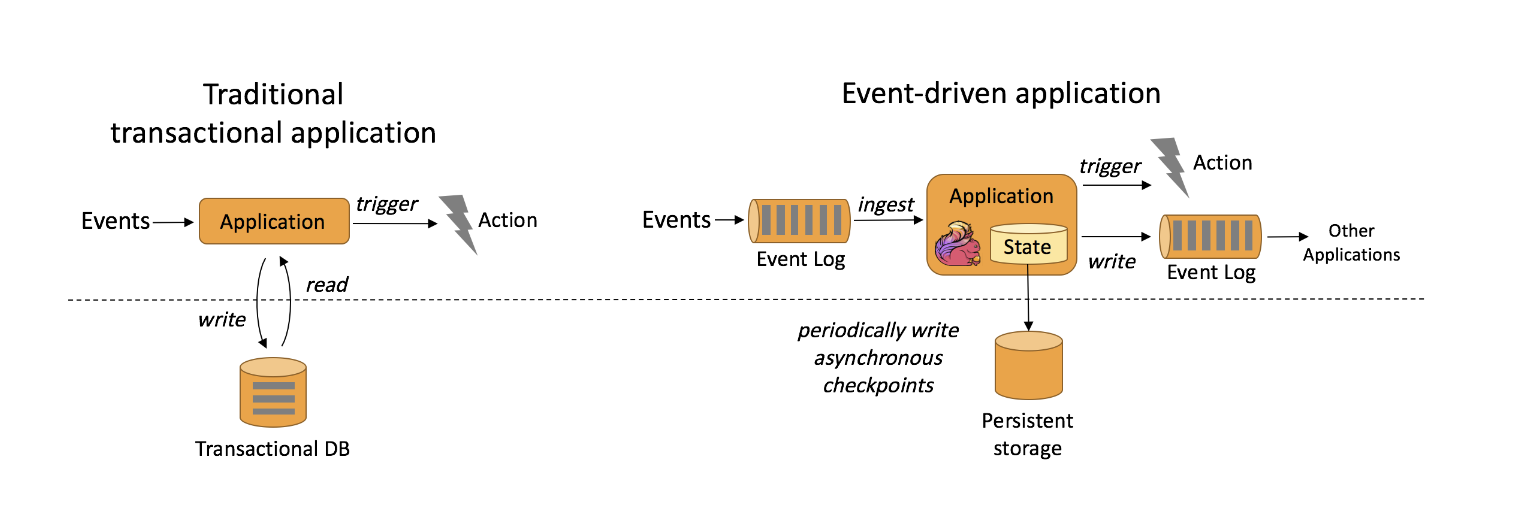
\ The effectiveness of event-driven applications largely depends on how well a stream processor handles time and state. Apache Flink excels in these areas with features like a rich set of state primitives for managing large data volumes with exactly-once consistency, support for event-time processing, customizable window logic, and fine-grained time control via the ProcessFunction. Flink also includes a Complex Event Processing (CEP) library for detecting patterns in data streams. A standout feature of Flink is its support for savepoints, which are consistent state images that allow applications to be updated, scaled, or run in multiple versions for A/B testing.
\
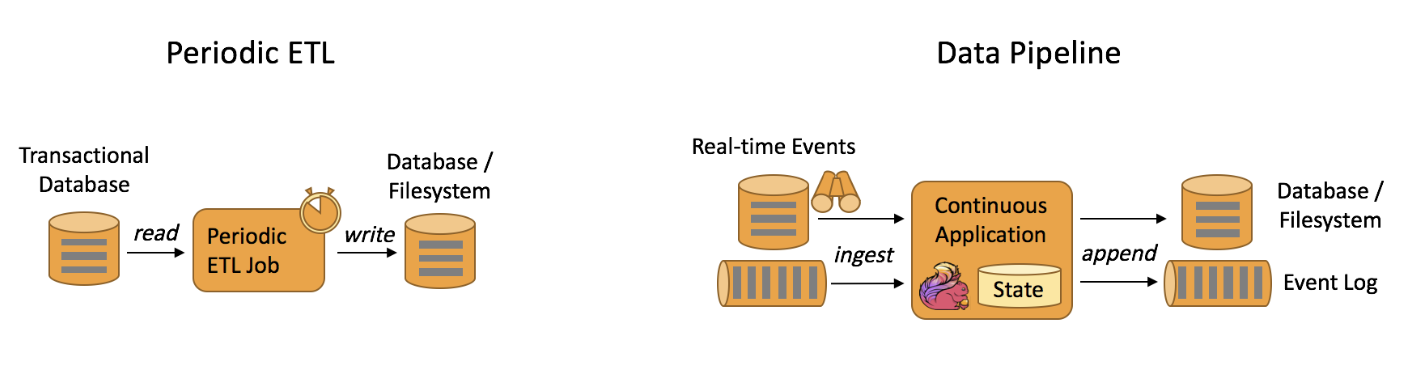
Data Pipeline Applications
Data pipelines are a series of data processing steps that systematically collect, process, and move data from one or more sources to a destination, typically for analysis, storage, or further processing. These pipelines are designed to handle various data operations such as extraction, transformation, and loading (ETL), ensuring that data is cleansed, formatted, and integrated from diverse sources before reaching its end destination.
\
\
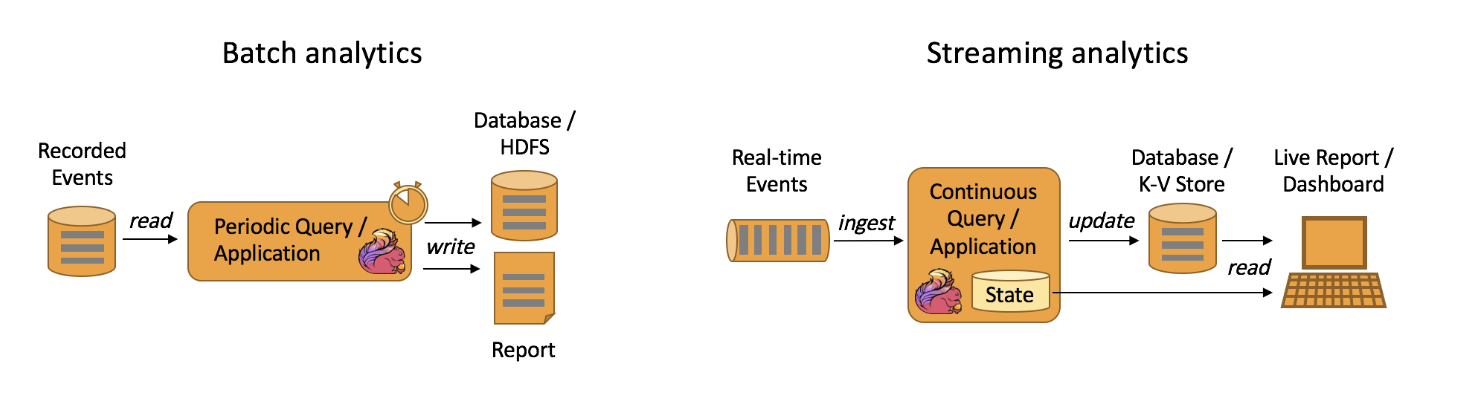
Data Analytics Applications
Data analytics applications are software solutions designed to analyze, interpret, and visualize data to provide actionable insights and support decision-making processes. These applications utilize various techniques such as statistical analysis, machine learning, and data visualization to transform raw data into meaningful information.
\
\
Summary
Streaming applications are fundamental in today's data-driven landscape. They provide the infrastructure and tools needed to harness data for insights, improve operational efficiency, and respond dynamically to changes, ultimately driving innovation and competitive advantage. They play a pivotal role in today’s data-driven world, enabling organizations to extract valuable insights from their data. By leveraging advanced analytics techniques and tools, businesses can make informed decisions, optimize operations, and gain a competitive edge. Understanding the components, types, benefits, and best practices of data analytics applications is essential for effectively harnessing the power of data to drive innovation and achieve strategic goals.
\ Next, we will explore the details of Stream Processing with a focus on windowing.
References
https://flink.apache.org/what-is-flink/flink-architecture
https://flink.apache.org/what-is-flink/use-cases/
https://beam.apache.org/documentation/programming-guide/
\
This content originally appeared on HackerNoon and was authored by Abhishek Gupta
Abhishek Gupta | Sciencx (2024-11-08T08:36:01+00:00) Stream Processing – Concepts. Retrieved from https://www.scien.cx/2024/11/08/stream-processing-concepts/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.