
This content originally appeared on HackerNoon and was authored by Anton Musatov
\ In the previous article, I discuss the main strategic techniques used in Domain-Driven Design (DDD). In this part, I will focus more on the tactical, practical approaches.
Layers
DDD doesn’t prescribe a specific architectural approach, but certain existing solutions effectively help achieve the tactical goals of the methodology. One such approach is a layered application architecture, which isolates the domain logic. The classical layers in this approach are:
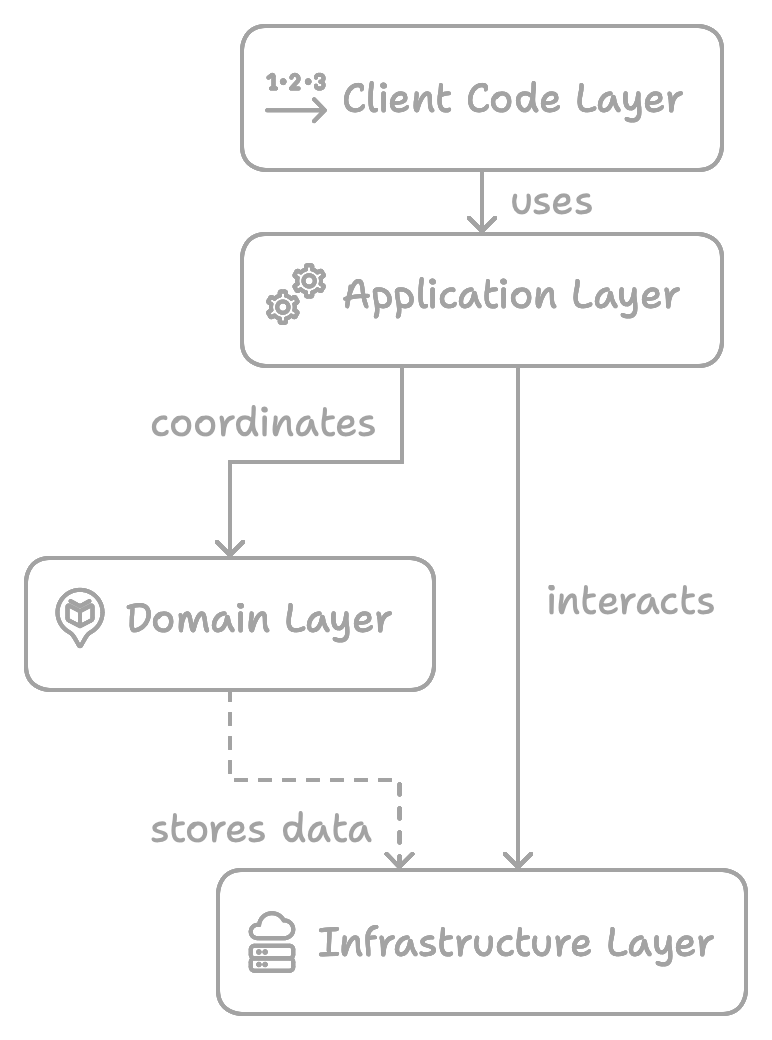
A key principle of organizing a layered architecture is unidirectional connections between the layers. This not only encapsulates logic within different components but also structures the code more effectively, avoiding unnecessary additional connections that could add extra complexity to the project. Let’s examine what each of these layers is responsible for in the context of DDD.
Client Code
This layer contains the code responsible for interacting with the user or external systems. It should handle incoming requests, transform the request into structures suitable for the underlying layers, and return a response or display information in a user-friendly format. If using a classic framework, this layer might include components such as Controllers, Requests, Responses, Jobs, and Views.
Application
In the context of DDD, this layer acts as an internal API to the domain logic. It determines which domain objects should be called and in what sequence. It should not contain business logic but should isolate the domain objects from the Client Code layer. Therefore, the Application layer should also handle converting domain entities into simple DTO objects.
Domain
This layer is responsible for the concepts and rules of business logic. It is the core level and the main algorithmic part of the application. It should be as isolated as possible from other layers and only interact with the infrastructure layer in a limited way.
Infrastructure
This layer provides technical support for the upper layers. It includes mechanisms for persistent storage, message brokers, and events for interacting with other contexts or systems.
Let's explore what techniques and patterns can be applied to these different layers.
Command Pattern
The command pattern is a good fit for structuring an internal API to the domain. It is a behavioral design pattern that turns requests into distinct objects. These objects typically have a single execute method that triggers the action. Request parameters can be stored as fields in the command object through a constructor, thus formalizing the request parameters explicitly and encapsulating interactions with domain objects within the command objects.
\
interface Command {
public method execute()
}
class ConcreteCommandA implements Command {
public construct(foo: int)
public method execute()
}
class ConcreteCommandB implements Command {
public construct(bar: bool)
public method execute()
}
Entity
For structuring complex business logic within the domain layer, we may need more specialized objects. One such object is an Entity. As introduced in the DDD book by Eric Evans: "Many objects are not fundamentally defined by their attributes, but rather by a thread of continuity and identity." This is a key object in the domain, characterized more by its identity than by its attributes. An entity has state and persists in the system, even though its state may change over time.
\ A classic example is a user. A user has a unique identifier, and even if the user changes their name, login, or other parameters, we can still identify that user. Whether something qualifies as an Entity or not depends on the domain and the specific context. In some cases, a user might not be an Entity but rather a Value Object.
Value Object
Unlike entities, Value Objects don’t have an identity and are entirely defined by their internal attributes. Developers often create Value Objects to formalize input or output parameters or to reuse specific data structures in different parts of the system. These are valid reasons, but even if a Value Object contains only one attribute, it might make sense to create a separate class for it to explicitly define domain terms. This brings the domain code closer to the analytical model and makes it easier for developers to understand.
\ For example, I mentioned a user modeled as an entity. Now, imagine a separate context that deals with reports on users. In this case, the report might be the entity, while a separate Value Object could be created for the user that reflects the user’s row in the report.
Services
For operations that are important to the domain but cannot be explicitly tied to a specific entity, Eric Evans suggests using separate objects called Services. These objects shouldn’t contain internal state, have identity, or be stored persistently. Essentially, they should be pure functions for calculating attributes based on several entities. Entities should have priority for business logic, as they usually better represent the domain. However, if the logic doesn’t fit within an entity, it’s worth extracting it into a service.
\ For instance, if attribute-based access control is applied to entities and these rules are quite complex, it would be difficult to place this code inside a specific entity or user. A dedicated security service could be introduced to receive both the entity and the user as input and determine the accessibility of the entity for the user.
Specifications
Business logic often contains numerous boolean checks. These rules are often based on domain-specific regulations and need to be reused in multiple parts of the project. These rules can be diverse, combine in different ways, and not directly relate to any one entity. Thus, it’s recommended to separate such rules into objects called specifications. By adding a small amount of abstract code, it becomes possible to implement logical combinations of these objects, providing flexibility and reusability of the logic. This approach promotes maintainability and simplifies changing business rules without altering core entities, while making domain regulations more explicit.
\
interface Specification {
public method isSatisfiedBy(candidate: Entity): bool
}
class AndSpecification implements Specification {
private field specs: List<Specification>
public construct(...specs: Specification)
public method isSatisfiedBy(candidate: Entity): bool
}
class OrSpecification implements Specification {
private field specs: List<Specification>
public construct(...specs: Specification)
public method isSatisfiedBy(candidate: Entity): bool
}
class NotSpecification implements Specification {
private field spec: Specification
public construct(spec: Specification)
public method isSatisfiedBy(candidate: Entity): bool
}
Domain Events
The classic approach of using events and listeners can also be applied within the domain layer. Domain events make side effects of specific actions within the domain explicit, improving transparency and separating different parts of business logic. It’s essential to only use events directly related to the domain here, avoiding the inclusion of technical events like logging or monitoring to keep responsibilities clean and maintain the purity of the domain model. Proper implementation of domain events leads to a more flexible and scalable architecture, simplifying system support and development.
Repositories
The repository pattern is a good fit for isolating domain entities from the details of persistent storage implementation. The repository provides access to domain entities as if they were in-memory collections, with all database logic and data mapping encapsulated within the repository interface. In this case, repository interfaces can be placed in the domain layer, while the implementation of these interfaces belongs to the infrastructure layer.
\
interface Repository {
public method findById(id: int): Entity
public method save(entity: Entity): bool
public method delete(entity: Entity): bool
}
class InMemoryRepository implements Repository {
private field entities: Map<int, Entity>
public method findById(id: int): Entity
public method save(entity: Entity): bool
public method delete(entity: Entity): bool
}
class DatabaseRepository implements Repository {
private field connection: DatabaseConnection
public method findById(id: int): Entity
public method save(entity: Entity): bool
public method delete(entity: Entity): bool
}
Integration Events
At the infrastructure level, we can also apply the event-listener approach. The first reason for this might be to integrate domain events with other contexts or systems. To maintain domain isolation, we can map domain events into similar integration events and then allow their usage. Another reason for introducing integration events could be the need for technical events. For example, if a domain-level entity is edited by a user and saved to the database, distributing the data across multiple tables, it may be useful to trigger a technical event to update each specific table, such as for cache invalidation.
\ In the next articles, I delve into the practical implementation of DDD within the context of a complex legacy project, focusing on potential pitfalls, subtle nuances, and useful practical tips.
This content originally appeared on HackerNoon and was authored by Anton Musatov
Anton Musatov | Sciencx (2024-11-08T07:00:13+00:00) Transforming Legacy with Domain-Driven Design, III: Tactic. Retrieved from https://www.scien.cx/2024/11/08/transforming-legacy-with-domain-driven-design-iii-tactic/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.