
This content originally appeared on HackerNoon and was authored by Anton Musatov
\ In this part, I am discussing the practical implementation of DDD in a complex legacy project, as a continuation of the previous article, focusing on potential mistakes, subtle nuances, and useful practical advice.
Value Objects and Memory Optimization
Value Objects are a useful approach that allows for both formalizing reusable data structures within the domain and designating terms from the subject area. To simplify working with Value Objects, they are often implemented as immutable objects. However, this can lead to an accumulation of many identical objects in memory. The Flyweight pattern is an excellent solution for optimizing memory usage when implementing various Value Objects in the domain layer.
\ For example, in this project, I had a Value Object that described the type of trading procedure:
\
class TradeType {
public const TYPE_AUCTION = 1;
public const TYPE_TENDER = 2;
public const VALID_TYPES = [
self::TYPE_AUCTION,
self::TYPE_TENDER,
]
private field value: int;
private construct(value: int) {
this->value = value
}
public static method get(value: int): self {
if (! in_array(value, self::VALID_TYPES_CODES)) {
throw new DomainInvalidArgumentException();
}
return self(value);
}
public method getValue(): int {
return this->value
}
}
\ To avoid creating new objects for the same type of trading procedure, the Flyweight pattern can be applied. To do this, I modified the code as follows:
\
class TradeType {
public const TYPE_AUCTION = 1;
public const TYPE_TENDER = 2;
public const VALID_TYPES = [
self::TYPE_AUCTION,
self::TYPE_TENDER,
]
private static field instances: TradeType[];
private value: int;
private construct(value: int) {
this->value = value
}
public static method get(value: int): self {
if (! in_array(value, self::VALID_TYPES_CODES)) {
throw new DomainInvalidArgumentException();
}
if (! isset(self::instances[value])) {
self::instances[value] = new self(value);
}
return self::instances[value];
}
public method getValue(): int {
return this->value
}
}
\ If the programming language supports weak references that do not prevent garbage collection, additional optimization can be added using them:
\
class TradeType {
public const TYPE_AUCTION = 1;
public const TYPE_TENDER = 2;
public const VALID_TYPES = [
self::TYPE_AUCTION,
self::TYPE_TENDER,
]
private static field weakReferences: Collection<int, WeakReference>;
private value: int;
private construct(value: int) {
this->value = value
}
public static method get(value: int): self {
if (! in_array(value, self::VALID_TYPES_CODES)) {
throw new DomainInvalidArgumentException()
}
instance = self::weakReferences[value]?->get()
if (null == instance) {
instance = new self(value)
self::weakReferences[value] = WeakReference::create(instance)
}
return instance
}
public method getValue(): int {
return this->value
}
}
\
Thus, only one object of TradeType will be created for each unique procedure type. If there are no strong references to the object, the garbage collector will free it. This approach is particularly useful when there are many Value Objects frequently used in the application and can significantly optimize memory usage.
Interfaces for External Services
There is often a need to reuse existing functionality at the domain level. For example, one of the checks when creating a trading procedure was that the end date of the procedure must be a working day. This check needed to consider not only weekends but also public holidays in the organizer's country calendar. The project already had a complex service that performed such calculations and allowed for saving unique exceptions for specific countries and years. We needed to reuse this service for similar checks in the domain layer.
\ However, in our context, we required only one of its actions — the check to see if a specific date is a working day. To achieve this, I applied an approach similar to the implementation of repositories at the domain level by creating a service interface at the domain level:
\
interface IHolidaysService
{
public method isWorkDay(countryId: CountryId, dateTime: DateTime): bool;
}
\ The implementation of this interface was done at the infrastructure level, using the existing service and its methods. Thus, the domain remained isolated from external dependencies while being able to reuse the logic of other application components.
Caching in Repositories
The "repository" pattern assumes working with the repository as an in-memory collection of entities, which is convenient and, in some cases, eliminates the need to pass entities through various layers of the system. Instead, entities can easily be retrieved from the corresponding repository. However, this is only possible if the repository does not perform a database query every time. To avoid this, I implemented multi-level caching at the infrastructure level.
\ The repository method takes a specification object and converts it into a database query. This query retrieves only the identifiers of the entities, not all the data, and caches them.
\ After retrieving the identifiers, the local cache is checked, which contains already prepared entities. This cache has a limited size and stores only a certain number of objects.
\ If the entity is not found in the local cache, complete information is extracted from the database based on its identifier, and this data is also cached. Next, the information is converted into an entity, the entity is added to the local cache, and it is returned to the calling method.
\ Thus, I had three levels of caching:
\
- A cache of entity identifiers corresponding to the database query.
- A local cache of prepared entities by their identifiers.
- A cache of data from the database for each entity by its identifier.
\ This extended the caching chain but significantly sped up operations with large volumes of data. The main part of the cache contained entity identifiers for complex database queries rather than the full data of the entities, which greatly reduced the memory footprint of this cache. The core data of each entity was stored in a separate cache by its identifier, allowing it to be reused across different queries. The local cache of prepared entities helped avoid repeated data conversion into entities, and its limited size prevented memory overflow.
\
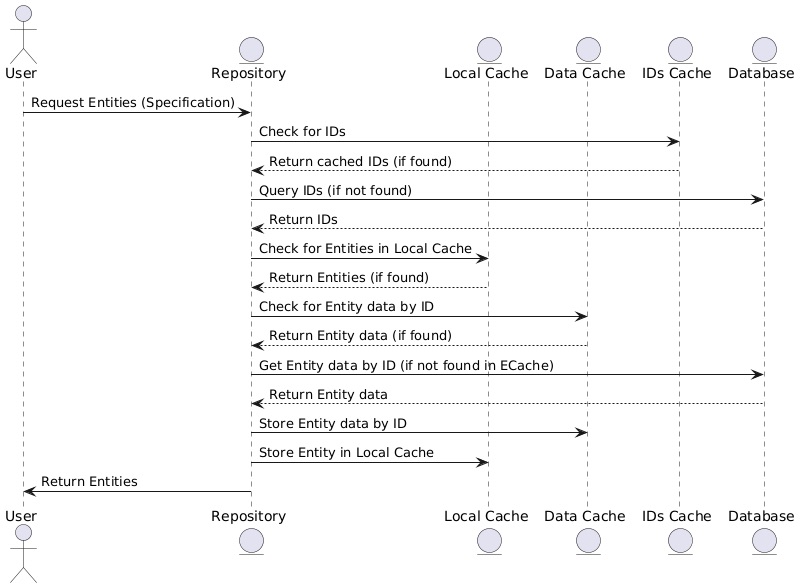
Controlling Relationships Between Layers
In one of the previous articles, I described a layered architecture that helps achieve the strategic goals of DDD. One important feature of such layers is the unidirectional connection, which significantly simplifies interaction between layers and reduces the complexity of their interrelations. However, maintaining this property can be a challenging task. New team members, due to their lack of experience, may start using the layers in the wrong order. And an external team, if you are working in a monolithic repository, may begin using your domain entities directly. In the first case, you have a chance to identify errors through administrative means, such as during code reviews, but in the second case, you may only discover issues during refactoring or extending your domain.
\ If your programming language supports access modifiers for classes, such as packages, namespaces, or modules, they can be used to delineate interactions between layers. For languages that do not have such functionality, a good alternative is static analysis using external libraries. Running such analyzers can be integrated into your CI/CD. For example, there is a library for PHP called Deptrac that allows you to describe layers and their permitted interactions in a configuration file, and then check all the code against this configuration. Although such tools may not detect issues as promptly as built-in language tools, you can be sure not to miss them.
Documentation
This point does not directly relate to the DDD methodology but can be useful for working with any complex subject area. In general, I support the approach that code should be expressive enough for a developer to understand the main concepts and rules just by reading it. However, this does not exclude the need for explanatory comments in complex or non-obvious places. For instance, if a specific, little-known algorithm is used in the code, it is important to add a comment with its name and a brief explanation of why it was chosen. This will help future developers understand the logic and context of using the algorithm more quickly.
\ Additionally, it can be useful to create brief descriptions for more general structures that explain key principles and approaches. In our project, for example, I created markdown files describing each level of architecture, which are located right in the repository alongside the code. These files contain information about what each level is responsible for and which patterns are used there. Although the code was well-organized, it included many classes, which could slow down the onboarding process for new developers. Such files greatly simplified the initial familiarization with the project and allowed experienced team members to quickly find the necessary information without having to remember all the details. We often create similar README files at the root of the repository, but we rarely add them in separate directories, even though this could significantly ease the team's work.
\ For some types of documentation, diagrams can be more effective than text. A graphical representation concentrates information and helps it be absorbed more quickly. In our case, I used PlantUML to create diagrams that were located right next to the code. This did not require manual drawing or keeping it up to date: the PlantUML language is simple and intuitive, and IDE plugins allowed generating diagrams on demand. For example, for our project, I created a diagram describing the interaction between layers.
\
@startuml
Actor Bob
box "ClientCode"
participant EndPointController
participant SpecificController
end box
box "App"
participant ICommandWithSecurity
participant ICommand
end box
box "Domain"
participant Entity
participant SecurityService
participant IEventDispatcher
end box
box "Infrastructure"
participant Repository
end box
title Example Entity creating
Bob -> EndPointController: :run()
EndPointController -> SpecificController: :run()
SpecificController -> ICommand: :execute()
ICommand -> SecurityService: :can...()
SecurityService --> ICommand: true
ICommand --> SpecificController: true
SpecificController -> ICommandWithSecurity: :execute()
ICommandWithSecurity -> ICommand: :execute()
ICommand -> SecurityService: :can...()
SecurityService --> ICommand: true
ICommand --> ICommandWithSecurity: true
ICommandWithSecurity -> Entity: :create()
Entity --> ICommandWithSecurity: Entity
|||
ICommandWithSecurity -> Repository: :startTransaction()
ICommandWithSecurity -> Repository: :save(Entity)
ICommandWithSecurity -> IEventDispatcher: :dispatch(Entity->getEvents())
ICommandWithSecurity -> Repository: :commitTransaction()
ICommandWithSecurity -> IEventDispatcher: :dispatchCommitted()
ICommandWithSecurity -> IEventDispatcher: :dispatchIntegration()
|||
ICommandWithSecurity --> EndPointController: DTO
EndPointController --> Bob: :redirect()
@enduml
\
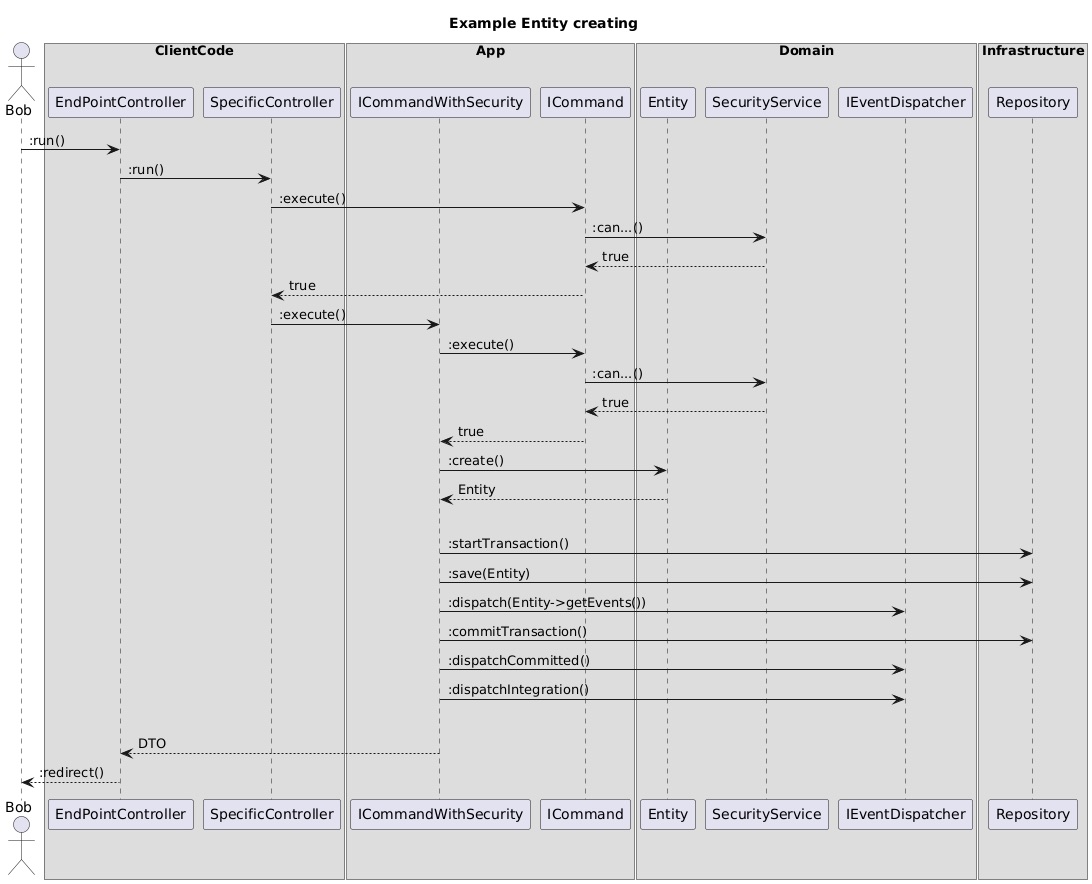
\ I also recommended using diagrams not only for describing technical implementation details but also for complex business rules. In particular, we created diagrams to describe complex Security Services.
\
@startuml
|TradeEditSecService|
start
if (Status "Deleted") then (yes)
#AA0000:false;
detach
else
if (Procedure cancelled?) then (yes)
#AA0000:false;
detach
else
if (Organizer?) then (yes)
if (Editing restriction on platform?) then (yes)
#AA0000:false;
detach
endif
if (Status "Draft") then (yes)
if (Creation permissions?) then (no)
#AA0000:false;
detach
endif
if (Manage departments?) then (yes)
#00AA00:true;
detach
endif
if (Belongs to department?) then (no)
#AA0000:false;
detach
endif
if (Department head?) then (yes)
#00AA00:true;
detach
endif
if (Restricted to responsible?) then (yes)
if (Responsible?) then
#00AA00:true;
detach
else
#AA0000:false;
detach
endif
else (no)
#00AA00:true;
detach
endif
else (no)
if (Admin rights?) then (yes)
if (Manage departments?) then (yes)
#00AA00:true;
detach
else (no)
if (Belongs to department?) then (no)
#AA0000:false;
detach
endif
if (Department head?) then (yes)
#00AA00:true;
detach
endif
if (Restricted to responsible?) then (yes)
if (Responsible?) then
#00AA00:true;
detach
else
#AA0000:false;
detach
endif
else (no)
#00AA00:true;
detach
endif
endif
else (no)
#AA0000:false;
detach
endif
endif
endif
#AA0000:false;
detach
endif
endif
@enduml
\
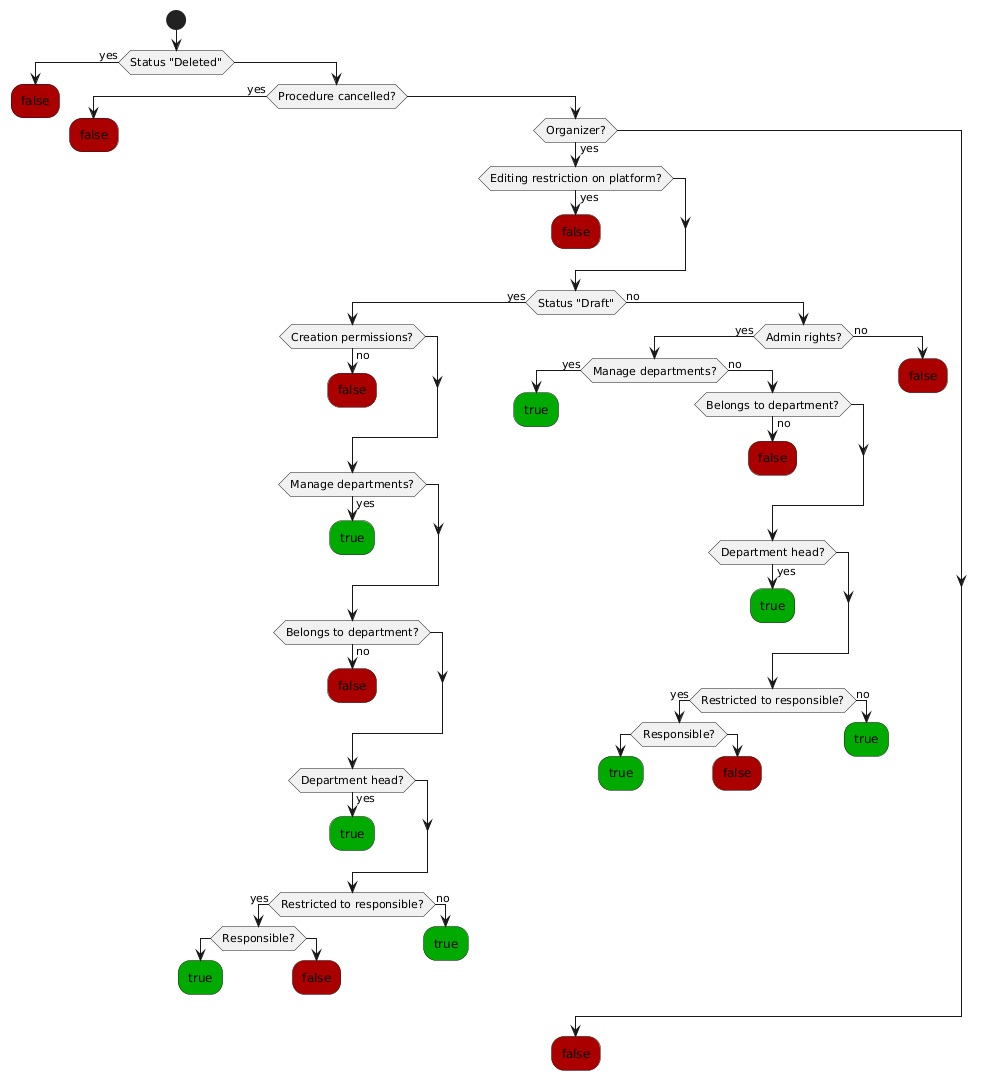
\ This helped synchronize with domain experts both during the initial development and when making changes in the future. When a developer is no longer deeply immersed in the context, such diagrams speed up understanding and finding the right place for modifications. At the code level, we could split such complex checks into several objects, while also dividing the diagram into several files and having an overall diagram referencing different files.
\ In the next article, I will share the results and achievements of implementing DDD in a large legacy project.
This content originally appeared on HackerNoon and was authored by Anton Musatov
Anton Musatov | Sciencx (2024-11-12T07:00:13+00:00) Transforming Legacy with Domain-Driven Design, V: Insights. Retrieved from https://www.scien.cx/2024/11/12/transforming-legacy-with-domain-driven-design-v-insights/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.