
This content originally appeared on Chromium Blog and was authored by Chromium Blog
The 1%
Our metrics show that while Chrome is fast on average, it can be noticeably slow at times. Such user-pain is visible in the 99th percentile of many of our metrics but unreproducible, and thus quite hard to act upon. Deeper analysis in the data shows that the long-tail of performance is not 1% of users on slow machines but rather many users, 1% of the time.Let’s talk about 1%. 1% is quite large in practice. The core metric we use is “jank” which is a noticeable delay between when the user gives input and when software reacts to it. Chrome measures jank every 30 seconds, so Jank in 1% of samples for a given user means jank once every 50 minutes. To that user, Chrome feels slow at those moments. Now the problem: can we find and fix the root causes of all the ways Chrome can be momentarily slow for our users?
Approach
As engineers, our training in optimization is to focus on improving the algorithmic performance of the components we own. The last 3 years of analyzing the immensely complex codebase of Chrome however have taught us that the real issue is often cross-cutting: multiple unrelated features’ long-tail performance issues, sharing the same systemic root cause(s). Applying local expertise and optimization is likely to miss the global optimum. It is necessary to disregard our initial intuition and assume ignorance, forcing us to dig beyond what is immediately apparent and find the underlying root cause by relentlessly exposing what we don’t know.Chasing Invisible Bugs
How do we find bugs that are unforeseen, unreproducible, unowned, and essentially invisible?First, define a scenario. For this work, we focus on user-visible Jank, which we measure in the field as a way to systematically identify moments where Chrome feels slow.
Second, gather high actionability bug reports in the field. For this we rely on Chrome’s BackgroundTracing infrastructure to generate what we call Slow Reports. A subset of Canary users who have opted in to sharing anonymized metrics have circular-buffer tracing enabled to examine specific scenarios. If a preconfigured threshold on a metric of interest is hit, the trace buffer is captured, anonymized, and uploaded to Google servers.
Such a bug report might look like this:

We have a culprit! Let’s optimize AutocompleteController? No! We don’t know why yet: keep assuming ignorance!
By augmenting BackgroundTracing with stack sampling, we were able to find a recurring stack under stalled AutoComplete events:
RegEnumValueWStub
base::win::RegistryValueIterator::Read()
gfx::`anonymous namespace\'::CachedFontLinkSettings::GetLinkedFonts
gfx::internal::LinkedFontsIterator::GetLinkedFonts()
gfx::internal::LinkedFontsIterator::NextFont(gfx::Font *)
gfx::GetFallbackFonts(gfx::Font const &)
gfx::RenderTextHarfBuzz::ShapeRuns(...)
gfx::RenderTextHarfBuzz::ItemizeAndShapeText(...)
gfx::RenderTextHarfBuzz::EnsureLayoutRunList()
gfx::RenderTextHarfBuzz::EnsureLayout()
gfx::RenderTextHarfBuzz::GetStringSizeF()
gfx::RenderTextHarfBuzz::GetStringSize()
OmniboxTextView::CalculatePreferredSize()
OmniboxTextView::ReapplyStyling()
OmniboxTextView::SetText...)
OmniboxResultView::Invalidate()
OmniboxResultView::SetMatch(AutocompleteMatch const &)
OmniboxPopupContentsView::UpdatePopupAppearance()
OmniboxPopupModel::OnResultChanged()
OmniboxEditModel::OnCurrentMatchChanged()
OmniboxController::OnResultChanged(bool)
AutocompleteController::UpdateResult(bool,bool)
AutocompleteController::Start(AutocompleteInput const &)
(...)
And before we figure that out, how do we know this is the #1 root cause of our overall long-tail performance issue? We’ve only looked at one trace so far after all...
The Measurement Conundrum
The metrics tell us how many users are affected and how bad it is, but they do not highlight the root cause.Slow Reports tell us what the problem is for a specific user but not how many users are affected. And while we can query our corpus of Slow Report traces, it comes with inherent biases that make it impossible to correlate 1:1 with metrics. For instance, because Chrome only reports the first instance of bad performance per-session and only for users of the Canary/Dev channel, there’s both a startup and a population bias.
This is the measurement conundrum. The more actionability (data) a tool provides, the fewer scenarios it captures and the more bias it incurs. Depth vs. breadth.
Tools that attempt to do both sit somewhere in the middle, where they use aggregation over a large dataset and risk showing aggregate results based on flawed input (e.g. circular buffer tracing having dropped the interesting portion and contributing to a biased aggregate).
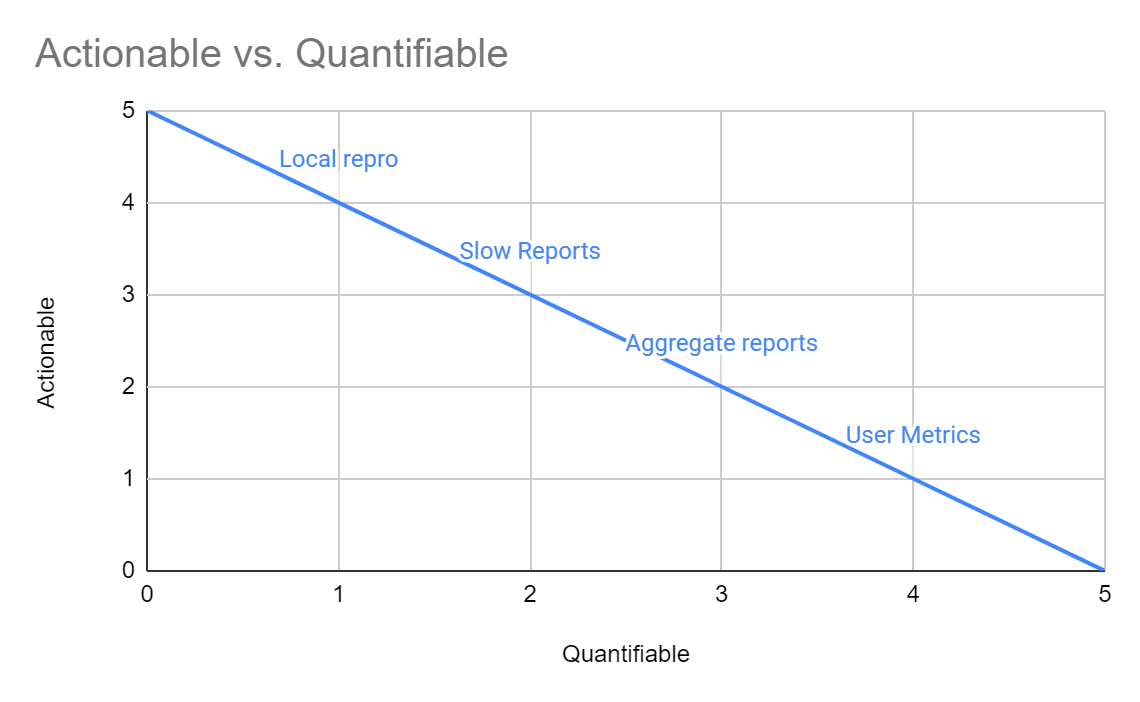
Thus we scientifically opted for the least engineering-minded option: open a bunch of Slow Report traces manually. This gave us the most actionability over a top-level issue we’d already quantified.
After opening dozens of traces it turned out that a great majority showed variations of the aforementioned fonts issue. While this didn’t give us a precise #users-affected, it was enough for us to believe it was the main cause of user pain seen in the metrics.
Fallback Fonts
We dug into why GetFallbackFonts() had to be called in the first place. In the example above, the caller is trying to determine the size in pixels of a Unicode string rendered by a given font.If a substring within it is from a Unicode Block that can’t be rendered by the given font, GetFallbackFont() is used to request the system recommended fallback font for it. If that fails, GetFallbackFonts() is invoked to try all the linked fonts and determine the one that can best render it; that second fallback is much slower.
GetFallbackFont() should never fail, but in practice it’s not that simple. The reliable way to do this on Windows is to query DirectWrite; however, DirectWrite was added in Windows 7, when Chrome still supported Windows XP. Therefore the GetFallbackFont() logic was forced to stick to a less reliable heuristic using Uniscribe+GDI in order to work on both versions of the OS. Since things worked most of the time, no one noticed that this could have been cleaned up when Chrome later dropped support for Windows XP. With new tooling to investigate long-tail performance, this turned out to be the number one cause of jank (unnecessarily invoking GetFallbackFonts()).
We fixed that, reducing the amount of calls to GetFallbackFonts() by 4x.
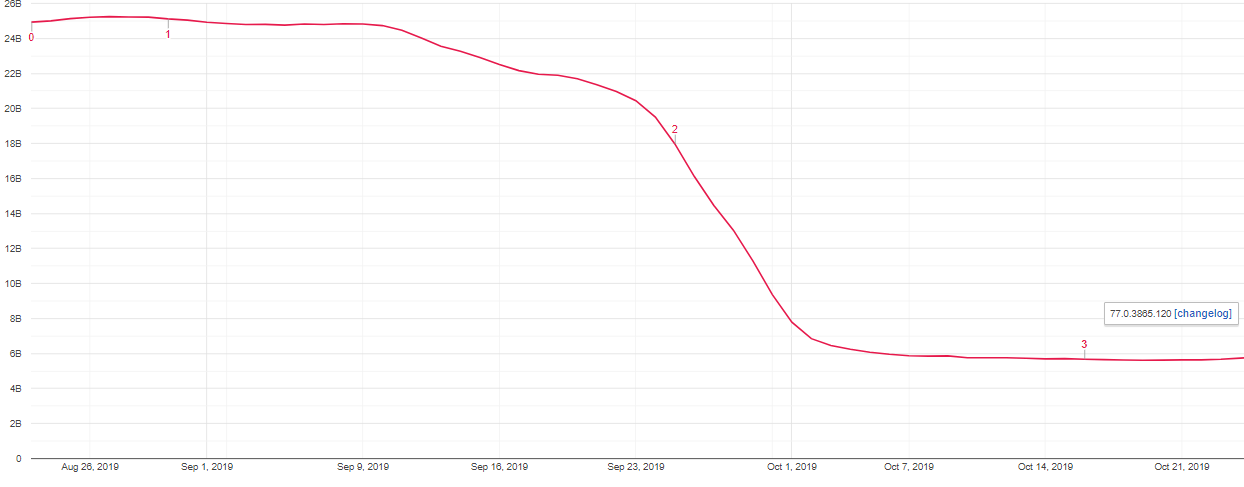
Still not zero though, and still seeing instances of the aforementioned AutoComplete issue in our Slow Reports. Keep digging. DirectWrite’s GetFallbackFont() failing was unexpected, but since Slow Reports are anonymized, no user-generated strings can be uploaded -- and therefore, finding which codepoints were problematic was tricky. We teamed up with our privacy experts to instrument Unicode Block and Script of text blocks going through HarfBuzz so that we could ensure no leakage of Personally Identifiable Information.
The Emoji Saga
With this new recording enabled, the next wave of Slow Reports came back. The vast majority of reports indicated that font fallback was failing when DirectWrite was being asked to find a font for a codepoint (Unicode character) in Miscellaneous Symbols and Pictographs. We wrote a local script trying all codepoints in that Unicode Block and quickly found out which ones could be problematic: U+1F3FB - U+1F3FF are modifiers added in Unicode 8.0 and are meaningful only when paired with another codepoint. For instance, U+1F9D7 (?) when paired with U+1F3FF is ??. No font can render U+1F3FF on its own, and font fallback would correctly error out after scanning all linked fonts when asked to find one. The bug was in the browser-side Unicode segmentation logic which incorrectly broke down these two codepoints and asked DirectWrite to render them separately instead of keeping them as a single grapheme.But wait, doesn’t Chrome support modern Unicode..?! Indeed, it does, in Blink which renders the web content. But the browser-side logic was not updated to support modern emojis (with modifiers) because it didn’t use to draw emojis at all. It’s only when the browser UI (tab strip, bookmark bar, omnibox, etc.) was modernized to support Unicode circa 2018 that the legacy segmentation logic became an (invisible) problem.
On top of that, the caching logic did not cache on error, so trying to render a modifier on its own caused a massive jank, every time, for users with a lot of fonts installed. Ironically, this cache had been added to amortize the cost of this misunderstood bottleneck when Unicode support was first added to browser UI. Diving deeper into the underlying implementation of our fonts logic, rather than stopping at the layer of the fonts APIs, not only fixed a major performance issue but also resulted in a correctness fix for other emojis. For instance, ?️? is encoded as U+1F3F3( ?️) + U+1F308 (?); before the itemization fix, browser UI would incorrectly render this grapheme as ?️?.
And the journey continues...
Our journey keeps going into various components of Chrome but it always follows the same basic playbook: assume ignorance and relentlessly investigate unforeseen, unreproducible, and unowned bugs. And while stack ranking issues is nigh impossible (see: measurement conundrum), fixing the top 5 findings from any given tool and zooming in on the long tail has always addressed the majority of the user pain in practice.Using this approach, we have reduced user-visible jank by a factor of 10X over the last 2.5 years and improved long-tail performance of many features caught in the cross-fire.

Data source for all statistics: Real-world data anonymously aggregated from Chrome clients.
This content originally appeared on Chromium Blog and was authored by Chromium Blog
Chromium Blog | Sciencx (2021-04-22T19:15:00+00:00) Digging for performance gold: finding hidden performance wins. Retrieved from https://www.scien.cx/2021/04/22/digging-for-performance-gold-finding-hidden-performance-wins/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.