
This content originally appeared on Robin Osborne and was authored by Robin Osborne

Microsoft have been consistently ramping up their AI offerings over the past couple of years under the grouping of “Cognitive Services”. These include some incredible offerings as services for things that would have required a degree in Maths and a deep understanding of Python and R to achieve, such as image recognition, video analysis, speech synthesis, intent analysis, sentiment analysis and so much more.
I think it’s quite incredible to have the capability to ping an endpoint with an image and very quickly get a response containing a text description of the image contents. Surely we live in the future!
In this article I’m going to introduce you to the Cognitive Services, focus on the Speech Recognition ones, and implement a working example for Speaker Verification.
The Cognitive Services mainly fall into these categories:

- Vision: Image-processing algorithms to try to describe and analyse your pictures
- Knowledge: Map complex information and data in order to solve tasks such as intelligent recommendations and semantic search.
- Language: Allow your apps to process natural language with pre-built scripts, evaluate sentiment and learn how to recognise what users want.
- Speech: Convert spoken audio into text, use voice for verification or add speaker recognition to your app.
Capabilities under the VISION category:

- Computer Vision API: retrieve keyword/descriptive information from images
- Face API: Detect, identify, analyse, organise and tag faces in photos, including recognising any emotion shown (via teh Emotion API)
- Content Moderator: Automated image, text and video moderation
- Custom Vision Service: Easily customise your own state-of-the-art computer vision models for your unique use case
- Video Indexer: Can wire together the Custom Vision Service for person recognition, speech analysis, emotion analysis, extract keywords – incredible stuff!
Within the SPEECH category we have:

- Speech to text: Customisable speech recognition and transcription
- Text to speech: Read text out loud with a customisable voice
- Translation: Translator is incredible; real time speech translation across 60 languages. There’s community created support for various other languages – including Klingon!
Knowledge, Language, and Search cover things like QnA Maker, Bing-* (loads of Bing APIs), and LUIS – the language understanding and intelligence service, used a lot when making chatbots.
The Speaker Recognition API
Which brings us on to the Speaker Recognition API; this is made up of two parts – verification and identification.
Verification API

The verification API is intended to be used as a type of login or authentication; just by talking a key phrase to your Cognitive Services enhanced app you can, with a degree of confidence, verify the user is who they (literally) say they are.
Each user is required to “enrol” by repeating a known phrase three times, clearly enough for the API to have a high confidence for that voiceprint – that is, the data representation of an audio recording.
Potentially being able to authenticate a user via a passphrase – perhaps treating this as a form of 2FA (two factor authentication) – could be an interesting application, especially from an accessibilty perspective.
My voice is my passport. Verify me.
A short aside – notice the selected phrase in that drop down picture? It looked really familar to me…

This is from the fantastic hacker movie from the 90s, Sneakers!

Unfortunately this particular phrase is used in the movie to show how unsecure voice verification is! Hopefully that’s just cinema and real life is more secure… right?
I love this film. Dan Ackroyd, Sidney Poitier, Robert Redford, Ben Kingsley, River Pheonix, hacking old school security systems! What’s not to love?
Azure Setup
Before we can get started with the coding, the first step is to get API keys for Cognitive Services. Head over to your Azure Portal, tap on New, AI + Cognitive Services, and search for “speaker”, then tap “Speaker Recognition API”:
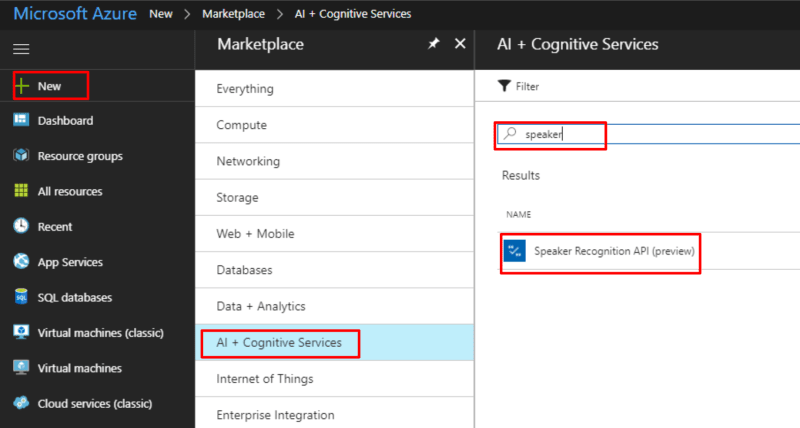
Once the creation process has completed you can grab your key:
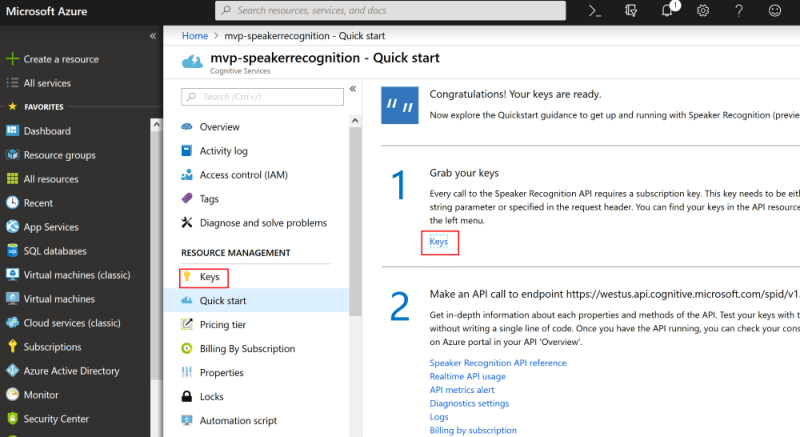
To set up Verification we need to call two or three endpoints;
- Create Profile (create a placeholder with an ID)
- Enroll Profile (associate some audio with that ID)
- Verify Profile (compare some audio to profile and see if it matches)
1. Create Profile
First up we need to ask the verification endpoint for a new profile ID; think of this as creating a blank record and getting the ID for it which we will later use to associate with a voiceprint:
// the cognitive services endpoint
var rootEndpoint =
'https://westus.api.cognitive.microsoft.com/spid/v1.0';
// the Verification endpoint to create a new profile
var create =
rootEndpoint + '/verificationProfiles';
var request = new XMLHttpRequest();
request.open("POST", create, true);
request.setRequestHeader('Content-Type','application/json');
// your cognitive services key goes in this header:
request.setRequestHeader('Ocp-Apim-Subscription-Key', key);
request.onload = function () {
var json = JSON.parse(request.responseText);
var profileId = json.verificationProfileId;
};
request.send(JSON.stringify({ 'locale' :'en-us'}));
The json response looks something like:
{
"verificationProfileId": "084a1bb8-3da0-48fe-80a5-11ad52b82c48"
}
Now we haven’t done anything particularly complex or clever yet; we just called an endpoint and got a response containing a guid. What we need to do next is associate that guid with a voiceprint.
2. Get the predefined verification phrases
Only a specific set of phrases are allowed by the verification service – you can’t just ask people to repeat a random sentence like “Oh yeah, you just have to say the following three times: ‘Robin is my favourite person ever and I’ll buy him coffee every day for a year and give him a promotion’, ok?”. Unfortunately.
To find out what the supported phrases are we hit a different endpoint:
// the cognitive services endpoint
var rootEndpoint =
'https://westus.api.cognitive.microsoft.com/spid/v1.0';
// the endpoint to list valid phrases
var phrases =
rootEndpoint + '/verificationPhrases?locale=en-US';
var request = new XMLHttpRequest();
// This one's a GET not a POST; we aren't creating anything here
request.open("GET", phrases, true);
request.setRequestHeader('Content-Type','multipart/form-data');
// your key goes here:
request.setRequestHeader('Ocp-Apim-Subscription-Key', key);
request.send();
Response:
[
{
"phrase": "i am going to make him an offer he cannot refuse"
},
{
"phrase": "houston we have had a problem"
},
{
"phrase": "my voice is my passport verify me"
},
{
"phrase": "apple juice tastes funny after toothpaste"
},
{
"phrase": "you can get in without your password"
},
{
"phrase": "you can activate security system now"
},
{
"phrase": "my voice is stronger than passwords"
},
{
"phrase": "my password is not your business"
},
{
"phrase": "my name is unknown to you"
},
{
"phrase": "be yourself everyone else is already taken"
}
]
Oooh, cool. Now we have the ID of a freshly created profile and a list of supported verification phrases. What’s next??
3. Enroll Profile
Now that we have a new profile ID and we know what phrases are allowed, next we have to record the audio in a particular format and send that to the “enroll” endpoint, to associate the voiceprint with our profile ID.
This process isn’t as easy as the others: the recording must be repeated 3 times successfully for a given profile.
For it to be successful, it must be:
- clearly recorded
- one of the predefined phrases
- same phrase each time (i.e., don’t use a different phrase from the list)
- audio in a specific format:
- WAV audio container
- 16K rate
- 16 bit sample format
- Mono
If you’re trying to follow along by implementing this in client side javascript, then this is where it could get really tricky; recording audio in this very particular format via your web browser’s web audio API is an absolute PAIN. I had to reverse engineer the Microsoft demo page (un-minifying a load of javascript to understand the libraries and specific settings used), and have a custom version of the incredible open source RecorderJS library on the github repo for this article
// the cognitive services endpoint
var rootEndpoint =
'https://westus.api.cognitive.microsoft.com/spid/v1.0';
// the endpoint to associate a profile with a voiceprint
var enroll =
rootEndpoint
+ '/verificationProfiles/'
+ profileId // NOW we can finally use the profile ID from the first request!
+ '/enroll';
var request = new XMLHttpRequest();
// POST
request.open("POST", enroll, true);
request.setRequestHeader('Content-Type','multipart/form-data');
// your key goes here
request.setRequestHeader('Ocp-Apim-Subscription-Key', key);
request.onload = function () {
var json = JSON.parse(request.responseText);
// there need to be 3 successful enrollments before it's ready
if (json.remainingEnrollments == 0)
{
console.log("Verification should be enabled!")
}
};
request.send(blob);
Notice the
blobin therequest.send(blob)call? That’s the audio recorded via the browser, already encoded in the correct format; i.e. WAV container, mono (1 channel), 16K rate, 16 bit sample format. The details of how this was achieved are out of the scope of this article, since they’re specific to the Web Audio API and a custom version of the incredible RecorderJS, which can be found within my demo solution over on github. I honestly can’t remember all the changes I had to make to get this working as it was a lot of trial and error!
The response will look something like this when more tries are needed:
{
"enrollmentStatus": "Enrolling",
"enrollmentsCount": 1,
"remainingEnrollments": 2,
"phrase": "houston we have had a problem"
}
Notice remainingEnrollments in the response? This is where we check to see if the enrollment has completed; if the audio wasn’t quite right (remember the checklist) then that number won’t go down. Once it reaches zero then the enrollment has successfully completed!
The response will look something like this when the enrollment has completed:
{
"enrollmentStatus": "Enrolled",
"enrollmentsCount": 3,
"remainingEnrollments": 0,
"phrase": "houston we have had a problem"
}
Notice enrollmentStatus is now “Enrolled”.
4. Verify!
Now that we have a voiceprint associated with a profile, let’s try to verify that profile by sending another chunk of audio.
You must repeat the same verification phrase that was used when setting up the profile for the verification to work; or you can try to fool it by having someone else do an impression of you, or say a different phrase yourself to test it.
// the cognitive services endpoint
var rootEndpoint =
'https://westus.api.cognitive.microsoft.com/spid/v1.0';
var verify =
rootEndpoint + '/verify?verificationProfileId='
+ profileId; // the id we're trying to verify
var request = new XMLHttpRequest();
request.open("POST", verify, true);
request.setRequestHeader('Content-Type','application/json');
request.setRequestHeader('Ocp-Apim-Subscription-Key', key);
request.onload = function () {
// did it work??
console.log(request.responseText);
};
// submit the audio we just recorded
request.send(blob);
When the audio matched the profile’s voiceprint, then you get a response like this:
{
"result": "Accept",
"confidence": "High",
"phrase": "houston we have had a problem"
}
When the audio doesn’t match, then you get a response like this:
{
"result": "Reject",
"confidence": "Normal",
"phrase": ""
}
Cool, huh?
Summary
As you can see, it’s really really easy to use this API; just sign up, record some audio, and call a few endpoints. How secure it actually is remains to be seen or tested, but it’s certainly very interesting and promising!
You can have a go yourself by checking out the github repo and playing with the demo; you just need to enter your cognitive services key in the box and tap GO.
Then you can tap the “Create Verification Profile” button, watch the responses come through, repeat (i.e., tap that same button again) until you get “Enrollment complete” in the response, and then tap the “Verify” button to see if you can be recognised or fool the system!
Stay tuned, as I’ll dig into the other Speech Recognition endpoint next: Identification
Troubleshooting
The documentation for the Speaker Recognition API is your best stop for issues with getting it working: API docs
If you try out the [demo](rposbo.github.io/speaker-recognition-api/ and find the profiles aren’t being verified very well, open a your browser’s debug console and type BurnItAll('verification') to delete all verification profiles associated with that cognitive services account; only do this when testing and playing around as it really will delete all profile voiceprints for the specified subscription key!
If the demo or this article doesn’t make sense, then perhaps the LDN BotFramework Meetup session where I first talked about this will help: https://youtu.be/dseEDOsWzts?t=28m48s
This content originally appeared on Robin Osborne and was authored by Robin Osborne
Robin Osborne | Sciencx (2018-10-01T06:00:14+00:00) AI Awesomeness! Microsoft Cognitive Services Speech Verification. Retrieved from https://www.scien.cx/2018/10/01/ai-awesomeness-microsoft-cognitive-services-speech-verification/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.