
This content originally appeared on DEV Community and was authored by sidney alcantara
Know the how, the when, and the why behind our refactoring
When working on any project, especially in the MVP stage, we as developers often prioritise one thing above all else when writing code: making sure it works. Unfortunately, this can mean we write code hyperfocused on the MVP’s requirements, so we end up with code that is hard to maintain or cumbersome to expand. Of course, this isn’t a problem one can easily avoid since we don’t live in an ideal world. The forces of time are always against us — sometimes we just need to push something out.
I’m a software engineer building Firetable, an open-source React app that combines a spreadsheet UI with Firestore and Firebase’s full power. We ran into this exact issue with some fundamental code: the code for all the different field types, from the simple ShortText to the complex ConnectTable field.
After refactoring, we now have a more solid foundation to build more features, we squashed a few hard-to-find bugs, and we now even a guide on how our contributors can write new field types.
When code smells and tech debt became big problems
When we first started building Firetable, the idea was to build a spreadsheet interface, and naturally, the resulting product closely matched that. Looking at old screenshots, it’s remarkable how closely it resembles spreadsheet programs like Excel and Google Sheets:
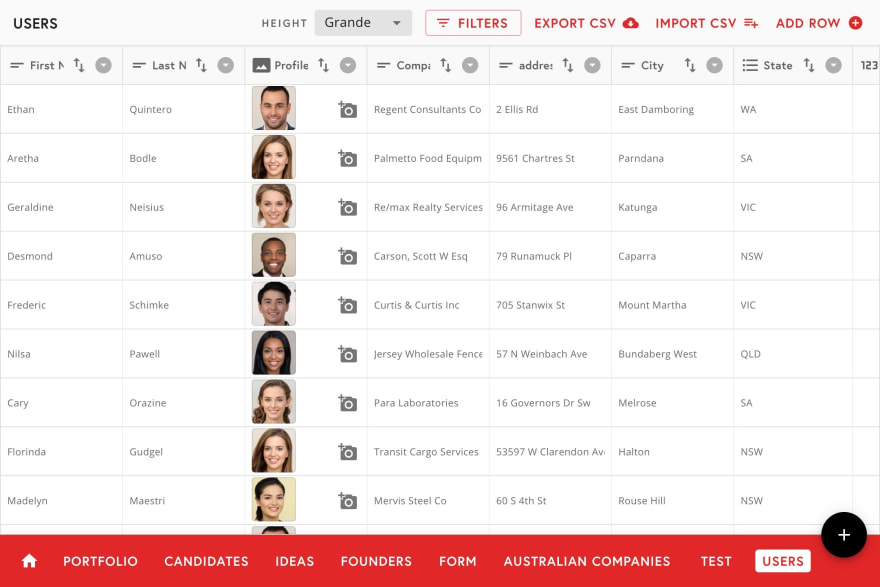
We used React Data Grid to implement this. It accepts “formatter” components used to render cells and “editor” components used to edit cells when a user double-clicks the cell. We structured our code around this, with formatters and editors becoming folders alongside the code for Table.
A few months later, we added the SideDrawer, a form-like UI that slides over the main table. It was designed to make it easier to edit all the fields of a single row at a time, which we found was an everyday workflow for our users. At the time, it seemed like the most logical way to structure this new code was similar to how we structured the Table, so we created a Fields folder in the SideDrawer folder.

But as we maintained this code, cracks began to show.
One of our distinctive field types is Action, which displays a button on the table that lets the user run code based on the row’s data using Firebase Cloud Functions and show the results in the very same cell. We’ve used it for novel applications such as setting our database’s access controls from right within Firetable using Firebase Auth custom roles.
We had a bug where the Cloud Function wasn’t receiving the right parameters when called by Action cells. But to update the code, we had to do it in two separate locations — the Table formatter and the SideDrawer field. Not only that, it turns out we had duplicated the code calling the Cloud Function due to time constraints. There was simply no clear location for that shared code, and the bug was too high-priority for us to have time to answer that question correctly.
The final straw was when we noticed we had inconsistently implemented the column lock feature. Some fields remained editable in the SideDrawer but not the Table or vice versa, or we didn’t implement it at all for that field. This was a result of adding this feature after we had implemented the minimum requirements for each field type, so we had to go through each Table formatter and each SideDrawer field — double the number of field types we had. This tedious manual process was clearly prone to errors.
At this point, we knew it was time to refactor.
Refactoring for success
We identified the main problem: we didn’t have a single place to store code for each field type. It was scattered throughout the codebase: Table formatters and editors, SideDrawer fields, column settings, and more. This scattering rapidly inflated the cost for adding new features for field types and weeding out bugs.
The first thing we did was invert our approach to code structure entirely — instead of grouping code by each feature that would use the field types, we grouped the code by the field types themselves.

The new approach translates to a new top-level component folder called fields, comprising subfolders for each field type, and within each, we have files such as TableCell.tsx and SideDrawerField.tsx. Then we could export these features in a config object, so all this code would only need to be imported once by the consumer. This is similar to a problem solved by React Hooks: grouping related code and not having to think about lifecycle methods.
This approach also simplifies how we import a field’s code throughout the codebase. Previously in the Table and SideDrawer, we would rely on switch statements that looped through each field type until we could fetch the correct component and import each field one by one. So whenever we added a new field type, we would also have to add a new entry to these switch blocks — again ballooning the cost of development. Instead, we could create a single array with every field config, then share it across the codebase. So we only need to define a new field type once.
Additionally, the config object lets us quickly implement new features and ensure all fields do so correctly. Now we could simply check if a field’s config has a property. And since we’re using TypeScript, each config object must implement our interface, which can enforce certain features (properties of the interface) to be of a particular type, such as a React component accepting specific props. This new functionality allowed us to fix column locking implementation and made it much easier to develop a new feature, default values for columns. All we had to do was add a new property to the interface.

With this in mind, our refactor not only made our code easier to maintain and fix bugs — but it also provided a much more solid foundation on which we can build advanced features for fields and removing extra costs to development.
Lessons for the future
Of course, we could have avoided all this pain and extra work had we initially gone with this approach. But we don’t live in an ideal world. All of the non-ideal solutions I mentioned above were the result of time constraints on our end, especially when we were working on other projects simultaneously, which directly impacted day-to-day work.
Many of us work for a business that doesn’t have excellent code quality as its primary goal. I work for a global early-stage venture capital firm, Antler, and I would be very shocked if this were the case for us. As developers, we are hired to build tech solutions that meet business requirements, and the “how” is abstracted away. In this case, however, our poorly-structured code and the amount of accrued tech debt were directly impacting our ability to work.
And whilst writing this article, I came across Refactoring.Guru, an excellent guide on refactoring. We clearly satisfied their first recommendation on when to refactor: “When you’re doing something for the third time, start refactoring.”
This experience has taught us many valuable lessons on code structure and when a refactor is necessary. I hope you’ve gained some insights by reading about our journey.
Thanks for reading! You can find out more about Firetable below and follow me on Twitter @nots_dney as I write more about what we’re building at Antler Engineering.
Features
-
Spreadsheet interface for viewing Firestore collections, documents, and subcollections.
- Add, edit, and delete rows
- Sort and filter by row values
- Resize and rename columns
-
27 different column types Read more
- Basic types: Short Text, Long Text, Email, Phone, URL…
- Custom UI pickers: Date, Checkbox, Single Select, Multi Select…
- Uploaders: Image, File
- Rich Editors: JSON, Code, Rich Text (HTML)
-
Powerful access controls with custom user roles Read more
-
Supercharge your database with your own scripts.
- Action field: trigger any Cloud Function
- Derivative field: populate cell with value derived from the rest of the row’s values
- Aggregate field: populate cell with value aggregated from the row’s sub-table
-
Integrations with external services.
- Connect Table uses Algolia to get a snapshot of another table’s row values
- Connect Service uses any HTTP endpoint to get a cell value
Firetable makes it easy to use key Firebase products





Live demo →
Getting started
To set…
This content originally appeared on DEV Community and was authored by sidney alcantara
sidney alcantara | Sciencx (2021-02-09T02:15:46+00:00) We Refactored 10K Lines of Code in Our Open-Source React Project. Retrieved from https://www.scien.cx/2021/02/09/we-refactored-10k-lines-of-code-in-our-open-source-react-project/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.