
This content originally appeared on DEV Community and was authored by Joël FARVAULT
This article is a result of a chat discussion with @aditmodi , Willian ‘Bill’ Rocha, Kevin Peng, Rich Dudley, Patrick Orwat and Welly Tambunan. Any other contributors are welcome ?
The data lake is the key foundation of data analytics. The data lake is the central repository that can store both structured data (such as tabular or relational data), semi-structured (key/value or document) and unstructured data (such as pictures or audio).
The data lake is scalable and provides the following functionalities:
- all data stored in a single place with a low-cost model
- variety of data formats can be stored
- a fast data ingestion and consumption
- schema on read versus the traditional schema on write
- decoupling between storage and compute
Building a data lake implies to:
- setup the right storage (and the corresponding lifecycle management)
- define the solution for data movement
- clean, catalog and prepare the data
- configure policies and a governance
- make data available for visualization
The data lake is very powerful solution for big data but there are some limitations:
- data management is challenging with data lakes because they store data as a “bunch of files” of different format
- managing ACID transactions or rollback requires to write a specific ETL/ELT logic
- query performance implies to select wisely the data format (such as Parquet or ORC)
A first alternative is the lakehouse architecture which bring the best of 2 worlds: data lake (low cost object store) and datawarehouse (transactions and data management). The lakehouse provides a metadata layer on top of the data lake (or object) storage that defines which objects are part of a table version. The lakehouse allows to manage ACID transactions through the metadata layer while keeping the data stored in the low cost data lake storage.
Another alternative that fits well in a complex and distributed environments is the data mesh architecture. Unlike a “monolithic” central data lake which handle in one place consumption, storage and transformation, a data mesh architecture supports distributed, domain-specific data consumers and views “data-as-a-product,” with each domain handling their own data pipelines.
The domains are all connected through an interoperability layer that applies the same syntax and data standards. The data mesh architecture is based on few principles:
- Domain-oriented data owners and pipelines
- Self-serve functionality
- Interoperability and standardization of communications This decentralized architecture brings more autonomy and flexibility.
Each data architecture model has benefits and shortcomings, there is no good and bad approach, it depends on the context and the use cases. Let’s evaluate how these data architecture patterns can be applied using a concrete example.
Requirements for a data platform
Your company needs a data repository with the following expectations:
- ingest data manually or from data pipelines
- produce ML models, QuickSight dashboard or external API with the output data
What is the best AWS architecture for these requirements?
Data Lake architecture
The diagram below presents a first solution for the requirements.
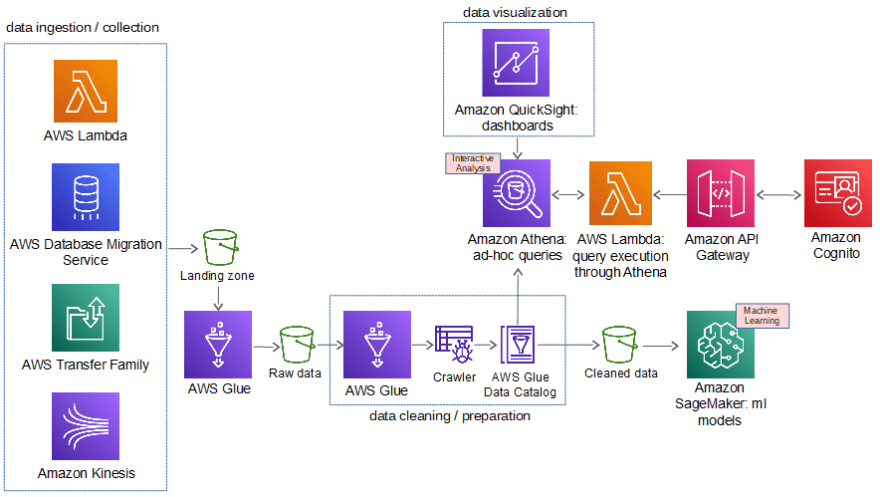
The AWS data lake architecture is based on several components:
1. The data ingestion / collection enables to connect different data sources through batch or real time modes.
| Services | Usage |
|---|---|
| AWS Data Migration Services | one-time migration of a database (cloud or on-premise) and replicate on-going changes |
| AWS Transfer Family | transfer of data over SFTP ➡️ article dev.to |
| Kinesis Firehose | fully managed delivering of real-time streaming data to Amazon S3 ➡️ article dev.to |
| AWS Lambda | serverless and event based data integration |
2. The data storage enables to hold massive amount of data in raw format. That’s the core of the data lake. The best storage service for this purpose is Amazon S3.
As highlighted in the diagram the best approach is to create specific buckets for landing zone, raw data and cleaned data.
3. The data cleaning and preparation implies to partition, index, catalog and transform data (especially into a columnar format for performance optimization). The data catalog will be automatically created or updated through a crawler that extracts the schemas and adds metadata tags in the catalog. The AWS options are AWS Glue or Glue DataBrew.
| Services | Usage |
|---|---|
| AWS Glue | ETL/ELT that can extract both data and metadata to build catalogs and perform transformations. You can either use the UI or author your scripts in Python, Spark and Scala |
| AWS Glue DataBrew | is a visual data prep tool that enables to profile, transform, clean and normalize data |
You can also use other ETL tools such as Amundsen for an intuitive UI and business data cataloguing. The solution Talend can be also an option.
4. The data processing and analytics is the process that creates insights from data (following the rule « garbage in garbage out » it is recommended to use cleaned data to get the best insights). The data will be structured and analyzed to identify information or to support decision-making.
The data processing can be done through batch mode, interactive analysis, streaming or machine learning.
| Batch mode | Services |
|---|---|
| Querying or processing large amount of data on a regular frequency (daily, weekly or monthly) | AWS Glue - EMR - Redshift |
| Interactive analysis | Services |
|---|---|
| Ad hoc querying for data exploration and analysis | Athena |
| Streaming | Services |
|---|---|
| Ingest and analyze a sequence of data continuously generated in high volume and/or high velocity | Kinesis Data Analytics |
| Machine Learning | Services |
|---|---|
| Perform on-demand data computation using inference endpoints | Sagemaker Inferences ➡️ article dev.to |
Based on the data lake requirements, the first approach for the data Analytics & processing leverages the following AWS services:

Athena for interactive analysis. Athena is a serverless querying service (based on Apache Presto) that enables to build SQL queries against relational or non-relational data stored in Amazon S3 (even outside S3 with Athena Federated Query). Athena is adapted for use cases such as: ad hoc queries, data exploration or integration with BI tools.
Sagemaker Inferences for machine learning. That service allows to execute ML models deployed through Sagemaker Endpoints.
This architecture provides also the possibility to expose some data through API Gateway using Lambda function and Athena.
Another option for the data lake architecture is to use Redshift as a curated datawarehouse. This approach will be described in the part 2 “the lakehouse architecture”.
5. data visualization is the tool that provides a view of the data for your data consumers. The purpose of Amazon QuickSight is to empower your data consumers (especially the business users) for building their visualization. QuickSight is powered by SPICE (Super-Fast, Parallel, In-Memory Calculation Engine) and provides the possibility to build easily dashboards and share it with other users.
As highlighted in the proposed architecture, QuickSight is integrated with Athena but it can be integrated with other data sources.
This article provides only an high level view of the topic, for more information I recommend these very useful dev.to posts:
This content originally appeared on DEV Community and was authored by Joël FARVAULT
Joël FARVAULT | Sciencx (2021-06-02T11:21:53+00:00) Architecture options for building a basic Data Lake on AWS – Part 1. Retrieved from https://www.scien.cx/2021/06/02/architecture-options-for-building-a-basic-data-lake-on-aws-part-1/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.