
This content originally appeared on DEV Community and was authored by Bradley Schoeneweis
Building an AWS lambda function that uses Python and wkhtmltopdf to convert an HTML file to a PDF file.
tl;dr
Goal
To set up an easy to call HTML to PDF converter as an AWS Lambda function.
Process Overview
- Downloading the
wkhtmltopdfbinary - Creating the AWS Lambda layer(s) and configuring our function
-
Writing the AWS Lambda function
- We will use Python's
subprocessmodule to call thewkhtmltopdfcommand - For more in-depth Python focused usage, also check out pdfkit
- We will use Python's
Prerequisites
This article assumes access to an AWS account (free-tier is acceptable) and basic knowledge of AWS Lambda/S3 and Python.
Functional Requirements
- Allow passing either an S3 file key or an HTML string
- Return a file key for the generated PDF
- Accept a small set of options for the
wkhtmltopdfcommand- A full man page can be found here
- Most of the ones we'd want anyways are the default (i.e.
--images,--enable-external-links, etc.)
Functionality for the following options
--orientation <orientation>--title <text>--margin-bottom <unitreal>--margin-left <unitreal>--margin-right <unitreal>--margin-top <unitreal>
Assumptions
- The HTML string or file will be valid and will include the necessary tags (
<!DOCTYPE html>,<html>,<head>,<body>). It is very important that you check validity of this HTML prior to calling this function if you ever use something similar in production. It may be best to only accept S3 file keys instead of HTML strings, but this is simply to show our functions possibilities or be used as an internal tool. - The event payload will contain all valid values (S3 bucket name, file key,
wkhtmltopdfoptions etc.)
Notes
This article will use us-east-2 for the AWS region, changing this shouldn't effect functionality, just the links within the article.
A better way to do this is through AWS Serverless Application Model (SAM), but this is more tailored for those looking for the basic setup through the AWS Management Console.
A common task I've found myself undertaking recently is programmatically converting an HTML file/string to an embedded and stylized PDF file.
An example use case for this might be exporting a self-managed customer invoice or generating a daily report from an existing HTML template. For those who have used template languages before, you can probably imagine the usefulness of a function like this in combination with Jinja or template rendering engines commonly found in Web Frameworks (like Django).
After doing some research on third party libraries that could simplify our goal, I decided to use wkhtmltopdf.
wkhtmltopdf is an open-source command line tool that enables you to easy convert an HTML file to a PDF file. This is exactly what we're looking for. We will call the wkhtmltopdf command using the subprocess Python library. For more in-depth Python usage, you can check out pdfkit.
Let's dive into it.
Why AWS Lambda?
AWS Lambda provides serverless computing functions where you don't need to manage any servers or containers, you can simply call your function synchronously or asynchronously, and it will be executed and scaled automatically.
Lambda has a ton of use cases and is something I have personally used many times and am a big fan of.
For our goal, AWS Lambda is a powerful tool for the following reasons
- It allows us to offload processing away from the server
- This is more of a general benefit, we won't actually be calling this function from a running server
- These calls will also be scaled automatically
- Our dependencies, specifically the
wkhtmltopdfbinary, can be handled well through AWS Lambda layers- This helps to avoid dealing with different Linux distributions or multiple installation locations
Below is an explanation of why handling the dependencies through layers will avoid issues. For continued instruction, you can skip to the next section.
Issues with downloading the binary
When I was first using this library, I was also using pdfkit to drive this interaction. At the top of the installation instructions, you can see the following warning:
Warning! Version in debian/ubuntu repos have reduced functionality (because it compiled without the wkhtmltopdf QT patches), such as adding outlines, headers, footers, TOC etc. To use this options you should install static binary from wkhtmltopdf site"
When I first installed wkhtmltopdf, I didn't heed the warning and just ran the following:
sudo apt-get install wkhtmltopdf
On initial inspection, I wasn't experiencing the problems they mentioned (at least in my local environment). The issues came when I actually pushed up code using this library to a staging environment and I noticed the PDFs were no longer generating.
I was able to remedy this by installing in an alternative way:
sudo apt-get remove --purge wkhtmltopdf
wget https://github.com/wkhtmltopdf/packaging/releases/download/0.12.6-1/wkhtmltox_0.12.6-1.bionic_amd64.deb
sudo dpkg -i wkhtmltox_0.12.6-1.bionic_amd64.deb
rm wkhtmltox_0.12.6-1.bionic_amd64.deb
This isn't a big deal, but managing this dependency could get tedious if your architecture has multiple servers that need installed with different Linux distributions.
Putting this binary into an AWS Lambda Layer can help solve this by having a single point of installation and management.
Downloading the wkhtmltopdf binary
The wkhtmltopdf site actually lists using this library with AWS Lambda as a FAQ and gives the following response to this question:
"All files required for lambda layer are packed in one zip archive (Amazon Linux 2 / lambda zip)"
You can download the binary on the releases page under the Stable releases. You'll see an entry under Amazon Linux with lambda zip as the architecture.
Or, you can click here (I likely won't update this link, so probably best to go directly to the release page).
Random note: If you need more fonts for future usage, I've found that this is a good resource. You may need to include one of these fonts as a layer in your lambda function (via ARN) if your function has issues in the beginning.
Creating the AWS Lambda layers
AWS Lambda layers allow us to add in "layers" of dependencies for our functions. An alternative to this is uploading your lambda function as a deployment package or using AWS SAM (Serverless Application Model), but that is out of the scope of this post.
wkhtmltopdf
Now that we have the zip file downloaded, let's add our file as a layer in the AWS Management Console.
Go to the Layers section on the AWS Lambda page and click Create layer.
Then, add the following Layer configuration.
Notice that we don't add a runtime here, this is intentional since our layer is a binary.
Click Create and take note of your new layer's Version ARN as we are about to use it to add to our function.
Now we're set up to create our function!
Writing the AWS Lambda function
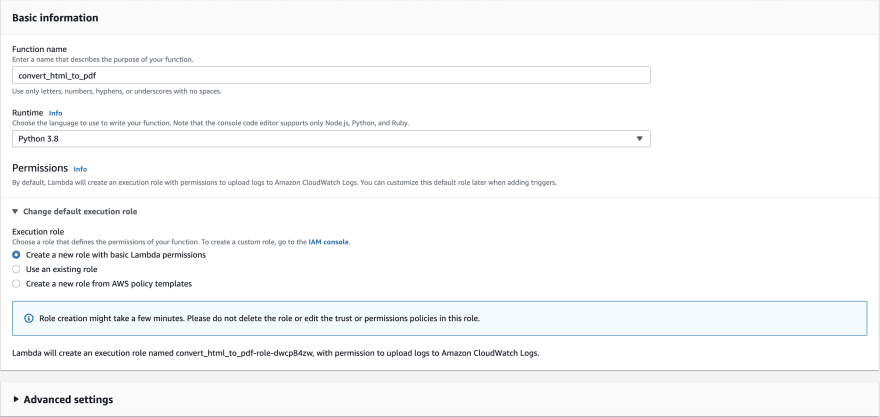
Navigate to the Functions page within the AWS Lambda service and click Create function.
Select Author from scratch, and add the following configuration.

You can ignore the Advanced settings for our use case.
Once the function is created, we have just a few configuration additions to make.
Adding the layer to our Lambda function
Now that our function is created, the first thing we want to do is add our wkhtmltopdf layer.
At the top of the Function Overview panel, click the Layers button right below your function name. This will bring you down to the layers section. Now click Add a layer.
Click on Specify an ARN and copy your Layer Version ARN from earlier.

The reason why we need to specify our layer by ARN is because we didn't define a runtime above.
Important! If your function generates a PDF with a bunch of black squares, this is likely because there is no font configuration within Lambda. To solve this, you can go to this link that I mentioned earlier, and copy one of the AWS Linux Fonts ARNs for your region (or build from scratch), add the environment variable in the README, and repeat these steps to add a font layer.
Add permission to access your S3 bucket
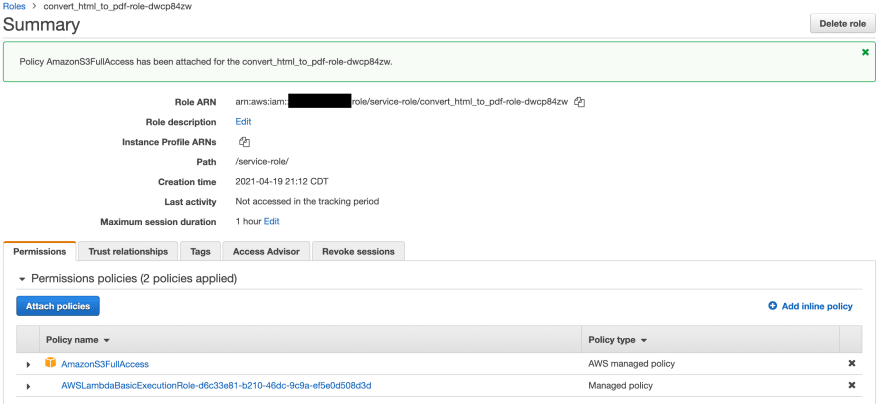
One final function configuration that we need to add is permission for our function to access Amazon S3. To do this, navigate to the Configuration tab below your Function Overview.
Under Configuration, go to the Permissions section. Here, you will see your generated Execution Role. Click this link to go to the IAM Console.
From here, click Attach policies, and add the AmazonS3FullAccess policy like so
Now that our function is configured, we can dive into the actual requirements and code!
Requirements
- Allow passing either an S3 file key or an HTML string
- Return a file key for the generated PDF
- Accept a small set of options for the
wkhtmltopdfcommand- A full man page can be found here
- Most of the ones we'd want anyways are the default (i.e.
--images,--enable-external-links, etc.)
Let's allow the user to pass the following options
-
--orientation <orientation>- the common page orientation for the PDF file.- Valid values are
LandscapeorPortrait
- Valid values are
-
--title <text>- the title of the generated file. - The margins of the file
--margin-bottom <unitreal>-
--margin-left <unitreal>(default is 10mm) -
--margin-right <unitreal>(default is 10mm) --margin-top <unitreal>
Assumptions
- The HTML string or file will be valid and will include the necessary tags (
<!DOCTYPE html>,<html>,<head>,<body>) - The event payload will contain all valid values (S3 bucket name, file key,
wkhtmltopdfoptions etc.)
The function code
By default, you will see the following handler.
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
This is the code that will be executed when your function is called. We'll come back to this in a bit.
The imports
First, let's go ahead and import all of the Python libraries that we'll need and set up some basic tools like the S3 client and our logger.
from datetime import datetime
import json
import logging
import os
import subprocess
from typing import Optional
import boto3
from botocore.exceptions import ClientError
# Set up logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Get the s3 client
s3 = boto3.client('s3')
Now based upon our requirements, we'll need helper functions to
- Download an HTML file from S3
- Upload a file to S3
Let's start with those, and then we'll return to our lambda handler.
Downloading/uploading the file
boto3 makes it really easy to interact with S3. Using boto3, we can add the following helper functions.
def download_s3_file(bucket: str, file_key: str) -> str:
"""Downloads a file from s3 to `/tmp/[File Key]`.
Args:
bucket (str): Name of the bucket where the file lives.
file_key (str): The file key of the file in the bucket.
Returns:
The local file name as a string.
"""
local_filename = f'/tmp/{file_key}'
s3.download_file(Bucket=bucket, Key=file_key, Filename=local_filename)
logger.info('Downloaded HTML file to %s' % local_filename)
return local_filename
def upload_file_to_s3(bucket: str, filename: str) -> Optional[str]:
"""Uploads the generated PDF to s3.
Args:
bucket (str): Name of the s3 bucket to upload the PDF to.
filename (str): Location of the file to upload to s3.
Returns:
The file key of the file in s3 if the upload was successful.
If the upload failed, then `None` will be returned.
"""
file_key = None
try:
file_key = filename.replace('/tmp/', '')
s3.upload_file(Filename=filename, Bucket=bucket, Key=file_key)
logger.info('Successfully uploaded the PDF to %s as %s'
% (bucket, file_key))
except ClientError as e:
logger.error('Failed to upload file to s3.')
logger.error(e)
file_key = None
return file_key
Parsing the event
One thing we haven't talked about yet is the data that we'll need to pass our function.
Let's define our JSON event schema as the following.
{
"bucket": "<Name of the bucket where the file is stored currently and will be stored after processing> [Required]",
"file_key": "<File key where the file is store in S3> [Required if `html_string` is not defined]",
"html_string": "<HTML string to convert to a PDF> [Required if `file_key` is not defined]",
"wkhtmltopdf_options": {
"orientation": "<`landscape` or `portrait`> [Optional: Default is `portrait`]",
"title": "<Title of the PDF> [Optional]",
"margin": "<Margin of the PDF (same format as css [<top> <right> <bottom> <left>] (all must be included)).> [Optional]"
}
}
wkhtmltopdf_options is an optional object. If the included options are not valid, they will not be included.
We can access all of the data passed to our function from the event parameter in the lambda_handler function.
Now, let's jump back to the lambda_handler function and add some code to pull out the data from our event and put together the remaining pieces of actually calling the wkhtmltopdf executable to finish our lambda function.
def lambda_handler(event, context):
logger.info(event)
# bucket is always required
try:
bucket = event['bucket']
except KeyError:
error_message = 'Missing required "bucket" parameter from request payload.'
logger.error(error_message)
return {
'status': 400,
'body': json.dumps(error_message),
}
# html_string and file_key are conditionally required, so let's try to get both
try:
file_key = event['file_key']
except KeyError:
file_key = None
try:
html_string = event['html_string']
except KeyError:
html_string = None
if file_key is None and html_string is None:
error_message = (
'Missing both a "file_key" and "html_string" '
'from request payload. One of these must be '
'included.'
)
logger.error(error_message)
return {
'status': 400,
'body': json.dumps(error_message),
}
# Now we can check for the option wkhtmltopdf_options and map them to values
# Again, part of our assumptions are that these are valid
wkhtmltopdf_options = {}
if 'wkhtmltopdf_options' in event:
# Margin is <top> <right> <bottom> <left>
if 'margin' in event['wkhtmltopdf_options']:
margins = event['wkhtmltopdf_options']['margin'].split(' ')
if len(margins) == 4:
wkhtmltopdf_options['margin-top'] = margins[0]
wkhtmltopdf_options['margin-right'] = margins[1]
wkhtmltopdf_options['margin-bottom'] = margins[2]
wkhtmltopdf_options['margin-left'] = margins[3]
if 'orientation' in event['wkhtmltopdf_options']:
wkhtmltopdf_options['orientation'] = 'portrait' \
if event['wkhtmltopdf_options']['orientation'].lower() not in ['portrait', 'landscape'] \
else event['wkhtmltopdf_options']['orientation'].lower()
if 'title' in event['wkhtmltopdf_options']:
wkhtmltopdf_options['title'] = event['wkhtmltopdf_options']['title']
# If we got a file_key in the request, let's download our file
# If not, we'll write the HTML string to a file
if file_key is not None:
local_filename = download_s3_file(bucket, file_key)
else:
timestamp = str(datetime.now()).replace('.', '').replace(' ', '_')
local_filename = f'/tmp/{timestamp}-html-string.html'
# Delete any existing files with that name
try:
os.unlink(local_filename)
except FileNotFoundError:
pass
with open(local_filename, 'w') as f:
f.write(html_string)
# Now we can create our command string to execute and upload the result to s3
command = 'wkhtmltopdf --load-error-handling ignore' # ignore unecessary errors
for key, value in wkhtmltopdf_options.items():
if key == 'title':
value = f'"{value}"'
command += ' --{0} {1}'.format(key, value)
command += ' {0} {1}'.format(local_filename, local_filename.replace('.html', '.pdf'))
# Important! Remember, we said that we are assuming we're accepting valid HTML
# this should always be checked to avoid allowing any string to be executed
# from this command. The reason we use shell=True here is because our title
# can be multiple words.
subprocess.run(command, shell=True)
logger.info('Successfully generated the PDF.')
file_key = upload_file_to_s3(bucket, local_filename.replace('.html', '.pdf'))
if file_key is None:
error_message = (
'Failed to generate PDF from the given HTML file.'
' Please check to make sure the file is valid HTML.'
)
logger.error(error_message)
return {
'status': 400,
'body': json.dumps(error_message),
}
return {
'status': 200,
'file_key': file_key,
}
Now you can go to the Test tab and create the following test event (change your bucket name as necessary)
{
"bucket": "bucket-for-articles",
"html_string": "<!DOCTYPE html><html><head></head><body>This is an example of a simple HTML page.</body></html>",
"wkhtmltopdf_options": {
"orientation": "portrait",
"title": "Test PDF Generation",
"margin": "10mm 10mm 10mm 10mm"
}
}
You should get a return event with a status of 200, and a file_key of your converted file, thus achieving our goal! ?
This content originally appeared on DEV Community and was authored by Bradley Schoeneweis
Bradley Schoeneweis | Sciencx (2021-06-02T02:38:53+00:00) Converting HTML to a PDF using Python, AWS Lambda, and wkhtmltopdf. Retrieved from https://www.scien.cx/2021/06/02/converting-html-to-a-pdf-using-python-aws-lambda-and-wkhtmltopdf/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.