
This content originally appeared on Level Up Coding - Medium and was authored by Lee James Gilmore

Practical examples of using Lambda ephemeral temp storage, S3 and EFS as a comparison, utilising the Serverless Framework and TypeScript, with supporting code examples
Introduction
When working with AWS Lambda there are various storage options available when working with files, but in which scenario should you use each one?
This blog post covers three options, with code examples; and discussions around when to use each, the advantages and disadvantages, and relative speed:
✔️ AWS S3
✔️ AWS EFS
✔️ Lambda Ephemeral Storage (tmp)
There is a forth option of Lambda Layers which I won’t be covering here as the files are always static in this scenario, but is covered in the following blog post below:
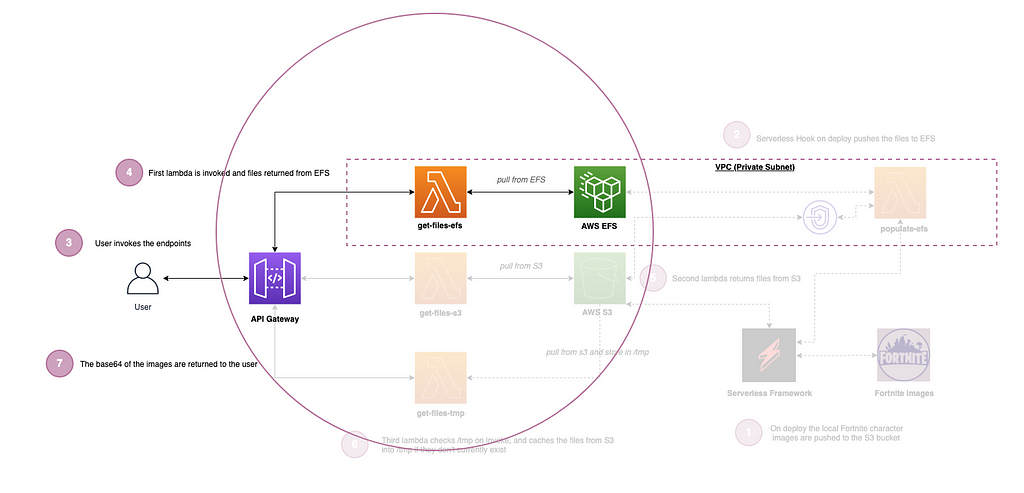
What are we building?
We are going to walk through building a solution which has an API with three endpoints to interact with each storage type via Lambda, and just for fun we are working with images of Fortnite characters ?
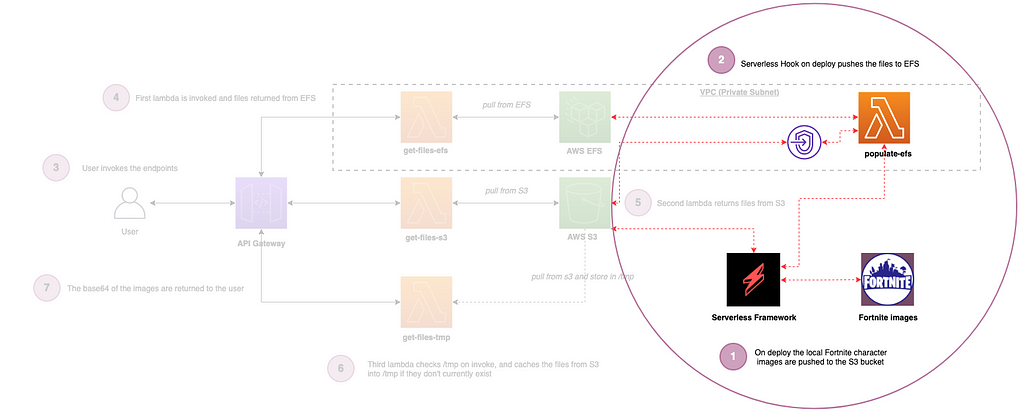
The steps and diagram below show what we are building (code repo available here):
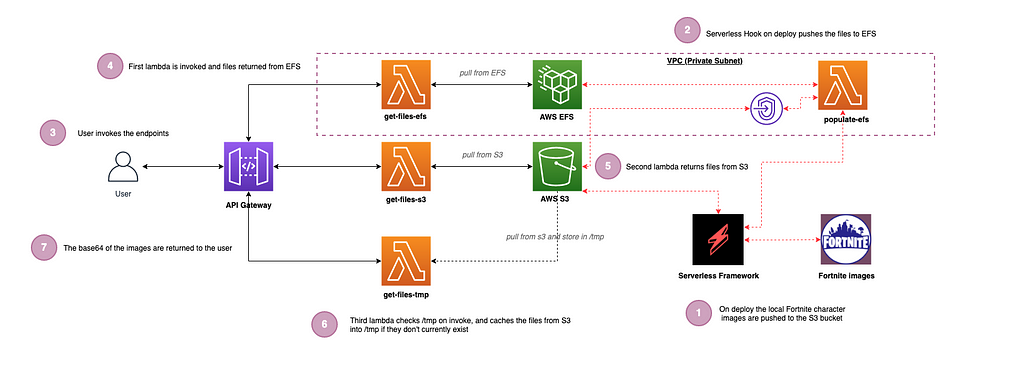
- On deploy using the Serverless Framework we push the four Fortnite character images to an S3 bucket (1.jpeg, 2.jpeg, 3.jpeg & 4.jpeg)(Setup).
- On successful deploy we also use ‘Hooks’ to invoke a Lambda which pushes the same images to EFS (Setup).
- The user can invoke any of the three endpoints for each storage type.
- The EFS based Lambda is invoked via API Gateway and returns the files from EFS (EFS).
- The S3 based Lambda is invoked via API Gateway and returns the files from S3 (S3).
- The tmp based Lambda checks to see if the files reside in the /tmp folder on the Lambda container itself already, and if not, it caches the same files from S3. On subsequent invocations via API Gateway the files are there already in tmp to serve from within the lambda (TMP).
- All of the files are returned in base64 format. (the following website is great for viewing base64 strings as images: https://codebeautify.org/base64-to-image-converter)
Example images below just for fun:
? Note: this is the minimal code and architecture to demonstrate the use of the three storage options, so this is not production ready code and does not adhere to all coding and architecture best practices
So what are the various storage options?
The three options we will be discussing are detailed below:
AWS S3
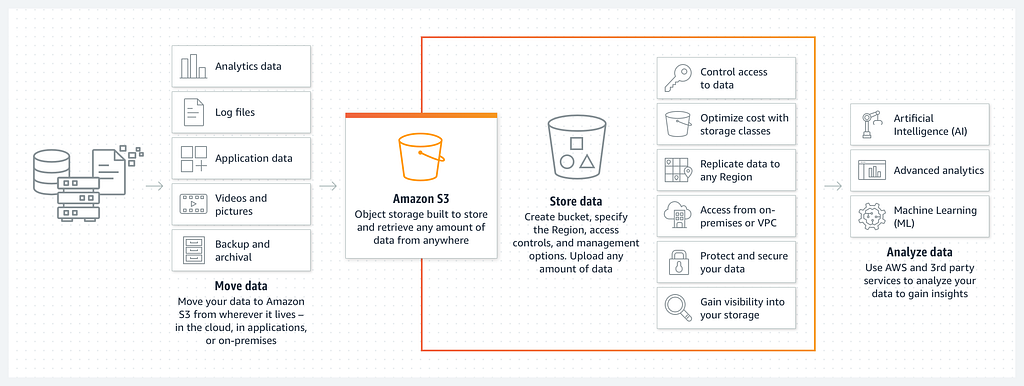
AWS S3 is a serverless option for object storage which scales indefinitely for your project needs, with eleven 9's of durability, allows for various encryption options at rest and transit, and is very cost effective. In the Serverless World this is a fantastic option for storing and retrieving files, especially with the various storage classes available.
Some of the use cases are shown in the diagram below, ranging from building data lakes, hosting front end web applications, backup and retrieval, storing logs etc:
AWS EFS
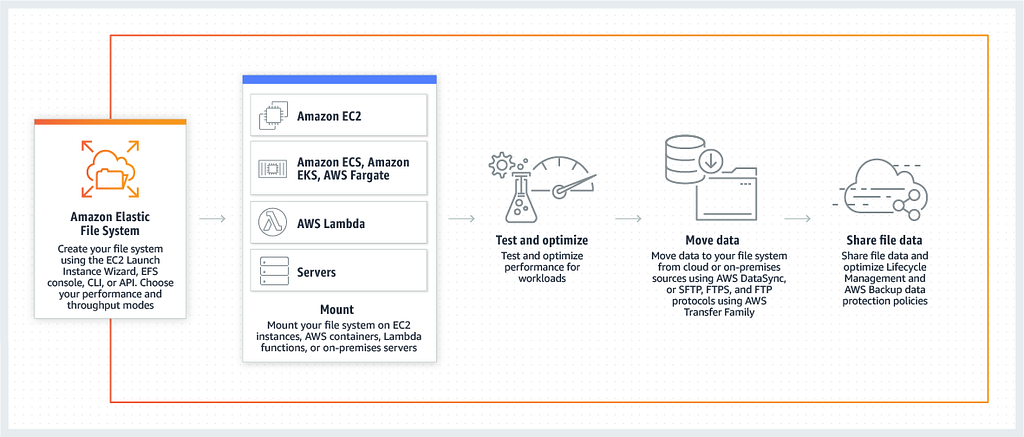
Amazon Elastic File System (AWS EFS) provides a simple elastic file system that lets you share file data without provisioning or managing storage. It can be used with AWS Cloud services and on-premises resources, and is built to scale on demand to petabytes without disrupting applications.
EFS with Lambda is another great serverless offering which is cost effective, has various storage classes (as does S3), automatically scales to your applications needs, and is another great approach for persistent file storage with Lambda:
AWS Lambda (tmp)
The third option is utilising the /tmp folder which is created within the Lambda container when the Lambda is first invoked. This allows you to read and write files directly into this folder, which is there for the lifetime of the specific Lambda container itself. This means that you can’t guarantee that the files are always going to be there in your code.
This is a great option when the persisted files don’t need to be shared across different invocations of the same Lambda when horizontally scaling, but there are some limitations of this approach which are discussed further in the article.
Getting started!
? Note: Running the following commands will incur charges on your AWS account so change the config accordingly.
Deploying the solution
In the root of the folder run npm i and then npm run deploy:develop which will install all of the dependencies and then deploy to AWS.
This will generate the resources for you using the Serverless Framework i.e. the API, compute layer and storage resources. You will see similar output to this following on a successful deploy:
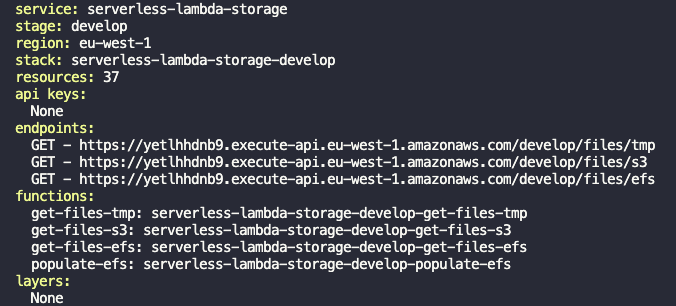
Automatically populating S3 and EFS with images on deploy
During the deploy of the resources, we use the serverless plugin serverless-s3-sync which takes the four images in the ./assets folder and automatically pushes them to the S3 bucket using the following config in the serverless.yml which ensures when we hit the endpoint we get back files straight after a successful deploy:
s3Sync:
- bucketName: ${self:custom.bucketName}
localDir: ./assets/
Now that we have the images deployed to an S3 bucket, at the end of the sls deploy we automatically run a Lambda which pulls the images from the S3 bucket and pushes them to the EFS file-share. This is done using the serverless plugin serverless-plugin-scripts and the following config below in the serverless.yml (again ensuring we get files back from the EFS endpoint straight away):
scripts:
hooks:
'deploy:finalize': sls invoke -f populate-efs
This invokes the populate-efs Lambda which grabs the images from S3 and writes them to EFS if they don’t already exist there. We now have EFS and S3 fully populated with the images as part of the deployment to start working with! ?
Pulling the images from tmp
The first Lambda we will discuss is pulling the images from the /tmp folder on the lambda itself. Obviously as part of the deploy we only pushed the images to S3 and EFS, and Lambda is ephemeral (short lived and only created when needed), so how do we get the images into the tmp folder?
“The Lambda execution environment provides a file system for your code to use at /tmp. This space has a fixed size of 512 MB. The same Lambda execution environment may be reused by multiple Lambda invocations to optimize performance. The /tmp area is preserved for the lifetime of the execution environment and provides a transient cache for data between invocations. Each time a new execution environment is created, this area is deleted.
Consequently, this is intended as an ephemeral storage area. While functions may cache data here between invocations, it should be used only for data needed by code in a single invocation. It’s not a place to store data permanently, and is better-used to support operations required by your code.”- James Beswick
When the lambda first invokes we check to see if the images reside in the tmp folder already, and if not we pull them from S3, which will now be cached in the tmp folder for the life of this lambda container and further invocations.
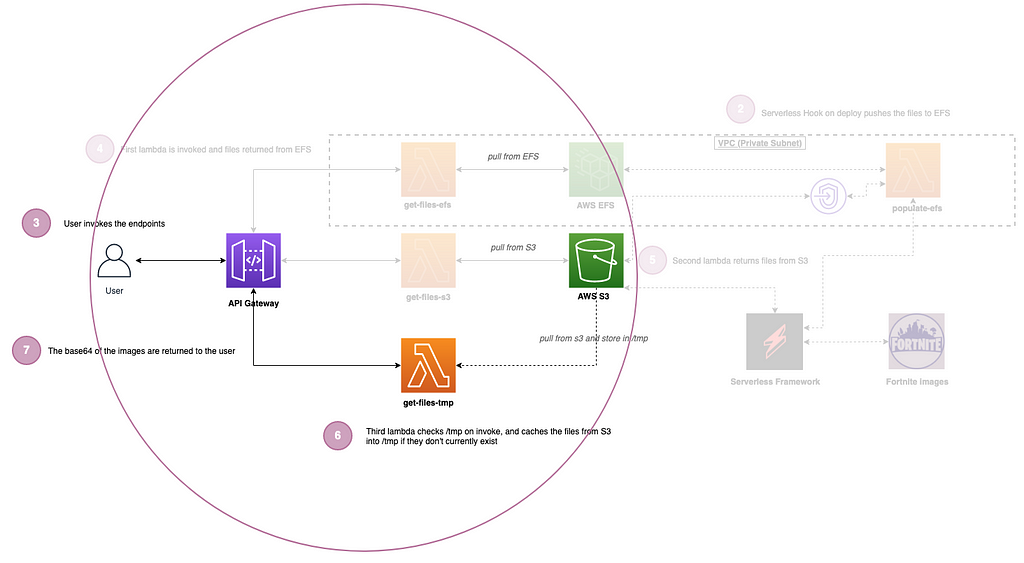
This means that the first call is slightly slower on a cold start as it grabs the images from AWS S3, but subsequent calls of the API are lightening fast!
? Another great example of caching in a lambda with NodeJS is populating a global variable outside of your lambda handler, which will now retain the values in memory across further invocations. You can’t assume it is always populated, however I have used this in the past to store generated tokens from a client credentials grant flow when hitting an internal API (i.e. rather than generating new tokens on every invocation). Check if it is populated, and if not, generate a new token and cache it — similar to the approach with tmp discussed above.
Pulling the images from S3
Next is a fairly simple setup which is pulling the files directly from the AWS S3 bucket.
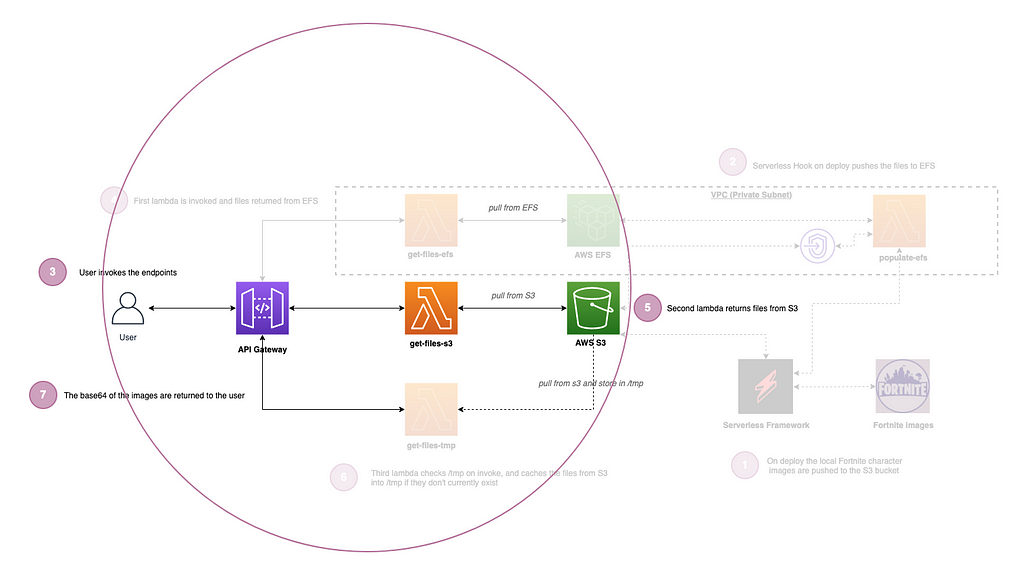
This is the slowest of the three methods but still really fast.
Pulling the images from EFS
The third Lambda pulls the files directly from EFS, and is the most complicated setup of the three.
This is because to use EFS with Lambda, your Lambda function needs to be attached to a VPC. The CloudFormation associated with creating an EFS file system is quite heavy, so I have added verbose comments in the serverless.yml file.
There is also the added complication that our Lambda which populates EFS from S3 on serverless deploy needs access to both S3 and EFS, and with the Lambda being in a private subnet with no internet access, it means that we need to introduce a VPC Gateway endpoint to allow the function to talk out to AWS S3 (another approach could have been using a Nat Gateway).
Testing the endpoints
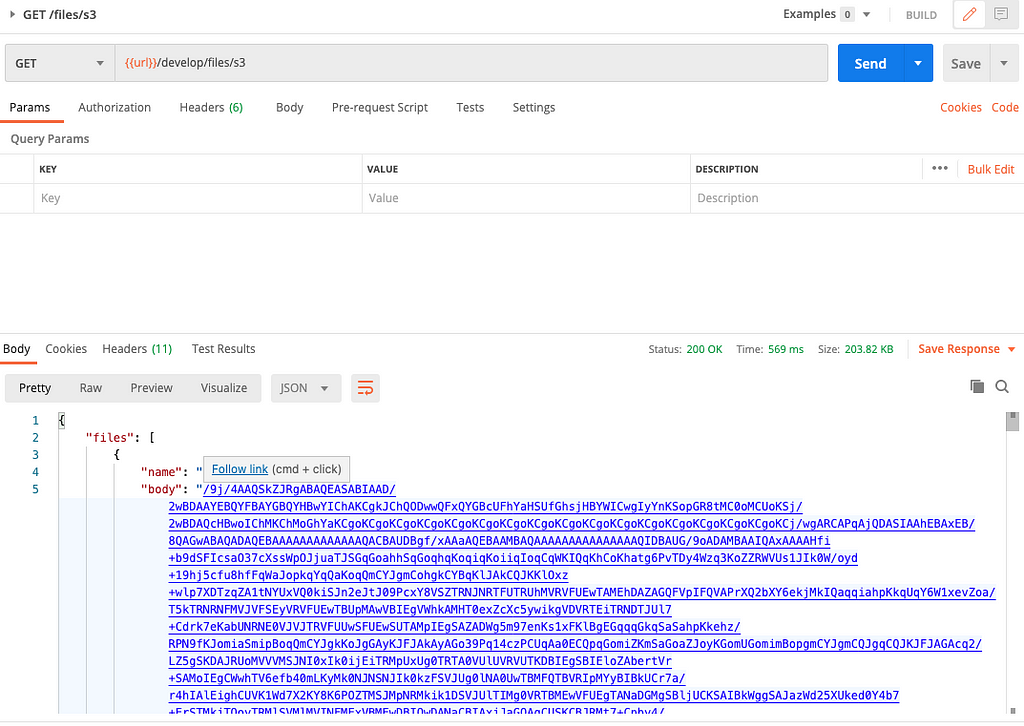
Now that we have discussed the setup, you can test the endpoints by using the Postman collection in the ./postman folder in the repo.
? Once you have imported the Postman collection, amend the url variable to be the API Gateway URL which we showed in the screenshot above following a successful deploy.
Example screenshot shows invoking the endpoints using Postman:
When to use each storage option?
Now that we have seen the three options coded and configured in the same solution, when would you use each, and what are the advantages and disadvantages of each approach in my opinion?
AWS temporary storage
Let’s discuss the /tmp folder on the Lambda itself first. This is the fastest of the three options when reading and writing files within your solution, however there is the added complexity in code that you need to check if the files reside in the folder already before using them. This is essentially the equivalent of reading and writing data to your local hard-drive.
You obviously also can’t share the files between different invocations of the same lambda (as you can’t typically with hard drives on individual machines).
You also have a capped limit of 512MB in the tmp storage which is a limitation with scale compared to the other options. This is however cost effective, and requires less IaC as the other options (i.e. no need to create file shares or s3 buckets, worry about configuration and permissions etc).
I have used this approach in the past to cache email templates within Lambda which changed very rarely, but increased the speed for our customers.
AWS S3
AWS S3 is the slowest of the three options when reading and writing files (but still very fast for most applications); however this doesn’t require a VPC like EFS does, so this is a fantastic offering if your full solution doesn’t need one (i.e. less IaC, configuration, setup etc).
S3 also has the best integrations with other AWS services in my opinion (for example invoking a Lambda when a new object is uploaded to the bucket), allows for object versioning and tagging, as well as allowing you to add metadata to the objects.
There are certain characteristics of S3 object storage that are important to remember. While S3 objects can be versioned, you cannot append data as you could in a file system. You have to store an entirely new version of an object. S3 also has a flat storage hierarchy that’s different to a file system. Instead of directories, you use folders to logically organize objects, by prefixing ‘foldername/’ in the key name. — James Beswick — Principal Developer Advocate for the AWS Serverless Team
A great use case is for allowing your customers to generate or upload their own documents and images (unstructured data) which need to be versioned, which is an approach I have used in the past in an enterprise application which worked very well.
S3 also allows you to run queries on the data using Amazon Athena and run reporting using Amazon QuickSight which are additional great features.
AWS EFS
AWS EFS for Lambda allows you to mount a shared file-system to your lambdas when they are first invoked, which retains the mount for the duration of that Lambdas lifetime.
This is great for sharing large data between many Lambda invocations, and as like the tmp approach, it is the fastest compared to S3. Because of the dynamic binding it also allows you to share your up to date large binaries or code libraries very easily (you can do this with Lambda Layers but this has overhead of managing and deploying the layers, and it is less dynamic).
With this option you can have up to 25K concurrent Lambda connections with your EFS file-share, with all Lambdas consuming the latest file data.
Due to its speed and support of standard file operations, EFS is also useful for ingesting or writing large numbers files durably. This can be helpful for zipping or unzipping large archives, for example. For appending to existing files, EFS is also a preferred option to using S3. — James Beswick — Principal Developer Advocate for the AWS Serverless Team
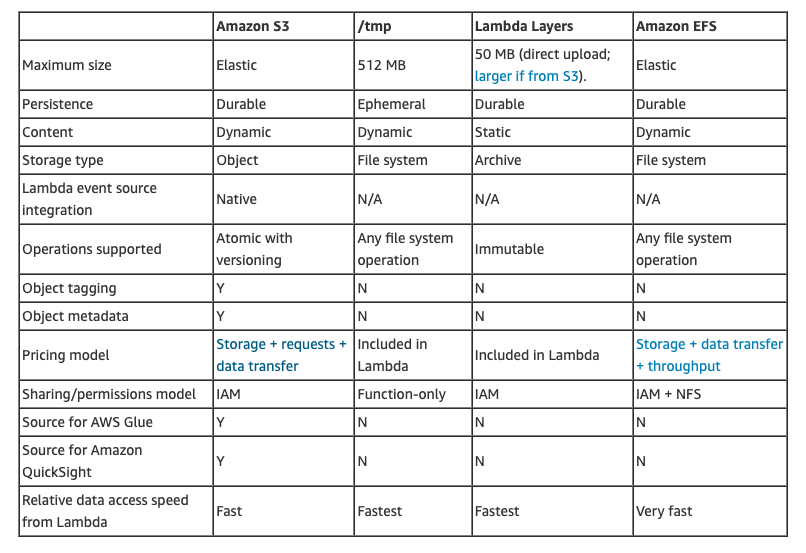
The diagram below shows the official comparison from AWS which highlights these difference very well in my opinion:
I hope you find this useful!
Wrapping up
I would love to connect with you on any of the following:
https://www.linkedin.com/in/lee-james-gilmore/
https://twitter.com/LeeJamesGilmore
If you found the articles inspiring or useful please feel free to support me with a virtual coffee https://www.buymeacoffee.com/leegilmore and either way lets connect and chat! ☕️
If you enjoyed the posts please follow my profile Lee James Gilmore for further posts/series, and don’t forget to connect and say Hi ?
Please also use the ‘clap’ feature at the bottom of the post if you enjoyed it! (You can clap more than once!!)
About me
“Hi, I’m Lee, an AWS certified technical architect and Lead Software Engineer based in the UK, currently working as a Technical Cloud Architect and Principal Serverless Developer, having worked primarily in full-stack JavaScript on AWS for the past 5 years.
I consider myself a serverless evangelist with a love of all things AWS, innovation, software architecture and technology.”
** The information provided are my own personal views and I accept no responsibility on the use of the information. ***
Serverless Lambda storage options ? was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Lee James Gilmore
Lee James Gilmore | Sciencx (2021-08-03T13:58:54+00:00) Serverless Lambda storage options. Retrieved from https://www.scien.cx/2021/08/03/serverless-lambda-storage-options/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.