
This content originally appeared on DEV Community and was authored by Ankit Anand ✨
The first step in setting up distributed systems monitoring and tracing is instrumentation, which enables generating and managing telemetry data. Once the telemetry data is generated, you need a way to collect and analyze it.

That's where OpenTelemetry collector comes into the picture.
OpenTelemetry collector provides a vendor-neutral way to collect, process, and export your telemetry data(logs, metrics, and traces) to an analysis backend of your choice.
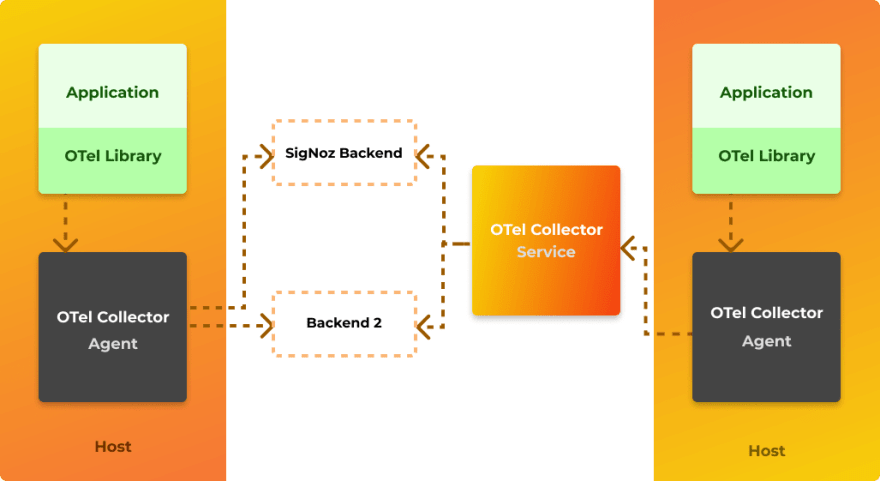 Architecture - How OpenTelemetry fits in an application architecture. OTel collector refers to OpenTelemetry Collector
Architecture - How OpenTelemetry fits in an application architecture. OTel collector refers to OpenTelemetry Collector
Before deep-diving into OpenTelemetry collectors, let's take a short detour to understand what OpenTelemetry is.
What is OpenTelemetry?
OpenTelemetry is a set of API, SDKs, libraries, and integrations that is aiming to standardize the generation, collection, and management of telemetry data(logs, metrics, and traces). OpenTelemetry is a Cloud Native Computing Foundation project created after the merger of OpenCensus(from Google) and OpenTracing(From Uber).
The data you collect with OpenTelemetry is vendor-agnostic and can be exported in many formats. Telemetry data has become critical to observe the state of distributed systems. With microservices and polyglot architectures, there was a need to have a global standard. OpenTelemetry aims to fill that space and is doing a great job at it thus far.
Why to use OpenTelemetry Collector?
A OpenTelemetry collector has three main functions - collect, process, and export the telemetry data collected. But before trying to understand more about OpenTelemetry collectors, let us first understand why it is a critical component of your monitoring architecture. Why can't you send your telemetry data directly to a backend analysis tool of your choice?
OpenTelemetry Collector gives you the flexibility to handle multiple data formats and offloads responsibility from the application to manage telemetry data.
List of reasons why to use OpenTelemetry Collector:
- Provides a vendor-agnostic way to collect telemetry data
- Offloads responsibility from the application to manage telemetry data, thereby reducing overhead
- Makes changes to the way of managing telemetry data easier
- Enables data export in multiple formats, multiple vendors to your choice
- Enables quick config-based updates, trivial to update a config file to receive data in another format
Architecture of OpenTelemetry collector
OpenTelemetry collector consists of three main components:
- Receivers
Receivers are used to get data into the collector. You can use it to configure ports and formats the collector can take data in. It could be push or pull-based. You can receive data in multiple formats. It has a default OTLP format, but you can also receive data in other popular open-source formats like Jaeger or Prometheus. SigNoz uses the default OTLP format to receive telemetry data.
- Processors
Processors are used to doing any processing required on the collected data like data massaging, data manipulation, or any change in the data as it flows through the collector. It can also be used to remove PII data from the collected telemetry data, which can be very useful. You can also do things like batching the data before sending it out, retrying in case the exporting fails, adding metadata, tail-based sampling, etc.
- Exporters
Exporters are used to exporting data to a backend analysis tool like SigNoz. You can send out data in multiple data formats.
 Architecture of OpenTelemetry Collector with receivers, processors and exporters.
Architecture of OpenTelemetry Collector with receivers, processors and exporters.
With the combination of these three components, OpenTelemetry Collector can be used to build data pipelines. Receiving data in one format, processing it and then sending out the data in another data format. This provides flexibility to teams working on distributed global systems.
How to configure a OpenTelemetry collector?
You need to configure the three components of the OpenTelemetry collector described above. Once configured, these components must be enabled via pipelines within the service section.
Receivers
In the sample code shown below, we have two receivers:
- OTLP Default OpenTelemetry protocol to transfer telemetry data. SigNoz receives telemetry data in OTLP format.
- Jaeger You can also receive traces data in Jaeger format, which is a popular distributed tracing tool.
receivers:
otlp:
protocols:
grpc:
http:
jaeger:
protocols:
grpc:
thrift_http:
Processors
There are three processors in the code sample shown below:
Batch
Batching helps better compress the data and reduce the number of outgoing connections required to transmit the data. This processor supports both size and time-based batching.Memory limiter
The memory limiter processor is used to prevent out-of-memory situations on the collector. Given that the amount and type of data a collector processes are environment-specific and resource utilization of the collector is also dependent on the configured processors, it is important to put checks in place regarding memory usage.Queued retry
This processor is highly recommended to configure for every collector as it minimizes the likelihood of data being dropped due to delays in processing or issues exporting the data.
processors:
batch:
send_batch_size: 1000
timeout: 10s
memory_limiter:
# Same as --mem-ballast-size-mib CLI argument
ballast_size_mib: 683
# 80% of maximum memory up to 2G
limit_mib: 1500
# 25% of limit up to 2G
spike_limit_mib: 512
check_interval: 5s
queued_retry:
num_workers: 4
queue_size: 100
retry_on_failure: true
You can find detailed information about these processors and more in OpenTelemetry Collector GitHub repo.
Exporters
In this sample code, we have created two exporters.
kafka/traces
This forwards collected traces to write to a kafka topic named asotlp_spans.kafka/metrics
This forwards collected metrics to write to a kafka topic named asotlp_metrics.
exporters:
kafka/traces:
brokers:
- signoz-kafka:9092
topic: 'otlp_spans'
protocol_version: 2.0.0
kafka/metrics:
brokers:
- signoz-kafka:9092
topic: 'otlp_metrics'
protocol_version: 2.0.0
You can also configure extensions which enables things like monitoring the health of OpenTelemetry Collector.
Extensions
Extensions provide capabilities on top of primary functionality of the OpenTelemetry Collector.
In this example, we have enabled two extensions.
Health Check
It enables a url that can be used to check the status of the OpenTelemetry Collector.Zpages
It enables an HTTP endpoint that provides live data for debugging different components of the OpenTelemetry Collector.
extensions:
health_check: {}
zpages: {}
Configuring the service section and data pipelines
All the components that are configured must be enabled via pipelines within the service section. If a component is not defined in the service section, then it is not enabled. Pipelines make OpenTelemetry collector a must-have component in your architecture. It provides the flexibility of receiving and exporting data in multiple formats.
In the example shown below, we have enabled two pipelines.
- traces
In this pipeline, we can receive traces in
jaegerandotlpformats. We then use three processors on the collected traces namelymemory_limiter,batchandqueued_retry. We export the processed traces to kafka topics. - metrics
In the pipeline, we receive metrics in
otlpformats. Process the collected metrics using batch processor and then export the processed metrics to kafka topics.
service:
extensions: [health_check, zpages]
pipelines:
traces:
receivers: [jaeger, otlp]
processors: [memory_limiter, batch, queued_retry]
exporters: [kafka/traces]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [kafka/metrics]
A sample OpenTelemetry Collector configuration file. (Source: SigNoz)
apiVersion: v1
kind: ConfigMap
metadata:
name: otel-collector-conf
labels:
app: opentelemetry
component: otel-collector-conf
data:
otel-collector-config: |
receivers:
otlp:
protocols:
grpc:
http:
jaeger:
protocols:
grpc:
thrift_http:
processors:
batch:
send_batch_size: 1000
timeout: 10s
memory_limiter:
# Same as --mem-ballast-size-mib CLI argument
ballast_size_mib: 683
# 80% of maximum memory up to 2G
limit_mib: 1500
# 25% of limit up to 2G
spike_limit_mib: 512
check_interval: 5s
queued_retry:
num_workers: 4
queue_size: 100
retry_on_failure: true
extensions:
health_check: {}
zpages: {}
exporters:
kafka/traces:
brokers:
- signoz-kafka:9092
topic: 'otlp_spans'
protocol_version: 2.0.0
kafka/metrics:
brokers:
- signoz-kafka:9092
topic: 'otlp_metrics'
protocol_version: 2.0.0
service:
extensions: [health_check, zpages]
pipelines:
traces:
receivers: [jaeger, otlp]
processors: [memory_limiter, batch, queued_retry]
exporters: [kafka/traces]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [kafka/metrics]
Getting started with OpenTelemetry
OpenTelemetry provides a vendor-agnostic way of collecting and managing telemetry data. The next step is to choose a backend analysis tool that can help you make sense of the collected data. SigNoz is a full-stack open-source application performance monitoring and observability platform.
If you have docker installed, getting started with SigNoz just takes three easy steps at the command line:
git clone https://github.com/SigNoz/signoz.git
cd signoz/deploy/
./install.sh
You can read more about deploying SigNoz from its documentation.
SigNoz can be used to visualize metrics and traces with charts that can enable quick insights for your teams.
 SigNoz UI showing application overview metrics like RPS, 50th/90th/99th Percentile latencies, and Error Rate
SigNoz UI showing application overview metrics like RPS, 50th/90th/99th Percentile latencies, and Error Rate
You can try out SigNoz by visiting its GitHub repo ?
This content originally appeared on DEV Community and was authored by Ankit Anand ✨
Ankit Anand ✨ | Sciencx (2021-08-31T12:57:05+00:00) Everything you need to know about OpenTelemetry Collector ?. Retrieved from https://www.scien.cx/2021/08/31/everything-you-need-to-know-about-opentelemetry-collector-%f0%9f%9a%80/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.