
This content originally appeared on DEV Community and was authored by Code_Jedi
In the last tutorial, we made a PHP script that performs customizable backend operations that take in user input.
In part 3, we'll be making a php script that refers another php script, which then executes a memory and time intensive background script through AJAX.
In order to understand some of the things covered in this tutorial, I strongly advice you to read Part 1 and Part 2
Just thinking about running and handling these sorts of memory and time intensive background processes in PHP brings back memories of younger me really struggling with them.
The reason is, I've spent a lot of time trying to handle and work with these types of PHP background operations. Heavy background operations in PHP are hard to:
- Handle
- Scale
- Adapt for good UX
But in this tutorial, I'll be condensing my experience with such backend operations and teaching you the easiest and most efficient way to perform and handle long running backend operations in PHP!
Let's get started!
First of all, let's create an index.php file:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Simple operations</title>
</head>
<body>
<form method="post" action="results.php">
Ticker: <input type="text" name="ticker"><br>
<button type="submit" >Submit</button>
</form>
</body>
</html>
As you can see, all it does is display a form asking the user for a 'url' and 'tag' parameter.
These parameters will then be passed on to our results.php file, and this is where the magic happens...
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Complex operations</title>
</head>
<body>
<h1 id="txt"></h1>
<?php
session_start();
$ticker = $_POST["ticker"];
$_SESSION["ticker"] = $ticker;
?>
<script>
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("txt").innerHTML = this.responseText;
}
}
xmlhttp.open("GET", "bg.php", true);
xmlhttp.send();
</script>
</body>
</html>
Now I know the stuff between inside the script tag might look scary, but let me explain what's happening here:
The h1 tag containing the "txt" id is defined, this will be used later by the code between the script tag.
PHP then starts the user session using
session_start();function, defines the$tickervariable as the parameters received from theindex.phpfile and finally defines the$_SESSION["ticker"]as the previously defined$tickervariable. These variables are then going to be used inbg.phpto execute the background operation, but we'll get into that later.Inside the script tag is where AJAX retrieves the data displayed by
bg.phpinside the h1 tag created earlier.
Inside bg.php:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Complex operations</title>
</head>
<body>
<?php
session_start();
$ticker = $_SESSION["ticker"];
$output = exec("ticker=$ticker node op1.js");
echo("<h1>$output</h1>");
?>
</body>
</html>
PHP:
Starts the user session using
session_start();Retrieves the
$_SESSION["ticker"];session variables created by theresults.phpfile.Displays the output of the
op1.jsfile once executed with the$tickerparameter passed on as a system variable( refer to Part 2 ).
The displayed text contents are then retrieved by AJAX and displayed onresults.php
op1.js simply scrapes the stock ticker passed-on by bg.php inside the $ticker parameter ( refer to Part 2 ).
For the purpose of this tutorial, there's no need to know how this works, but if you want to find out, check out this tutorial
const puppeteer = require('puppeteer');
async function start() {
const url = 'https://finance.yahoo.com/quote/' + process.env.ticker + '?p=' + process.env.ticker + '&.tsrc=fin-srch';
const browser = await puppeteer.launch({
args: ['--no-sandbox']
});
const page = await browser.newPage();
await page.waitFor(1000)
await page.goto(url);
var accept = ("#consent-page > div > div > div > form > div.wizard-body > div.actions.couple > button");
await page.click(accept)
await page.waitFor(1000)
var element = await page.waitForXPath("/html/body/div[1]/div/div/div[1]/div/div[2]/div/div/div[5]/div/div/div/div[3]/div[1]/div[1]/span[1]")
var price = await page.evaluate(element => element.textContent, element);
console.log(price)
browser.close()
}
start();
Here's how the whole process looks like:
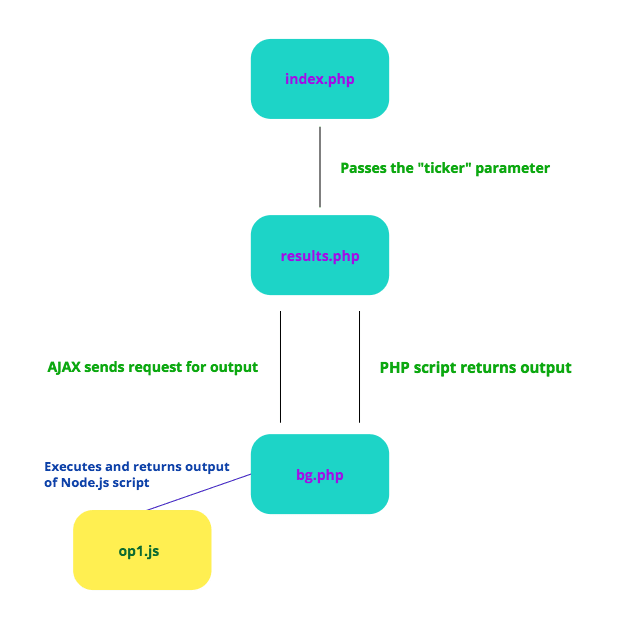
Let's see how it works!

As you can see, the stock price of the specified ticker is returned once it's scraped by the Node.js script, displayed by bg.php and retrieved by results.php, which takes about 5 seconds.
The main advantage of this is that the results.php webpage doesn't need to wait for the stock price element to be retrieved in order to load the page, this way, long running background operations that include: web scraping, data queries or machine learning don't need to take up loading time on the front-end.
Final thoughts
AJAX is a full-stack, back-end, and front-end developer's dream because it eliminates the problems of:
- Loading time
- Timeout errors on the front-end
- Bad UX that requires the user to constantly be redirected, reloaded, or getting stuck on loading screens
Since AJAX is such a big topic and has so many useful implementations, comment down below if you would like another tutorial on AJAX explaining how to build more complex fullstack applications with it?
Byeeee?
This content originally appeared on DEV Community and was authored by Code_Jedi
Code_Jedi | Sciencx (2021-09-21T19:00:17+00:00) Backend Operations in PHP from 0 to Hero(Pt. 3 Heavy operations and AJAX). Retrieved from https://www.scien.cx/2021/09/21/backend-operations-in-php-from-0-to-heropt-3-heavy-operations-and-ajax/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.