
This content originally appeared on DEV Community and was authored by carlwils
Table is one of the most commonly used formatting elements in PDF. In some cases, you may need to extract data from PDF tables for further analysis. In this article, you will learn how to achieve this task programmatically using a free Java API (Free Spire.PDF for Java).
Import JAR Dependency
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program, and there are 2 methods to do so.
Method 1: You can download the free API and unzip it. Then add the Spire.Pdf.jar file to your project as dependency.
Method 2: Directly add the jar dependency to maven project by adding the following configurations to the pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>5.1.0</version>
</dependency>
</dependencies>
Sample Code
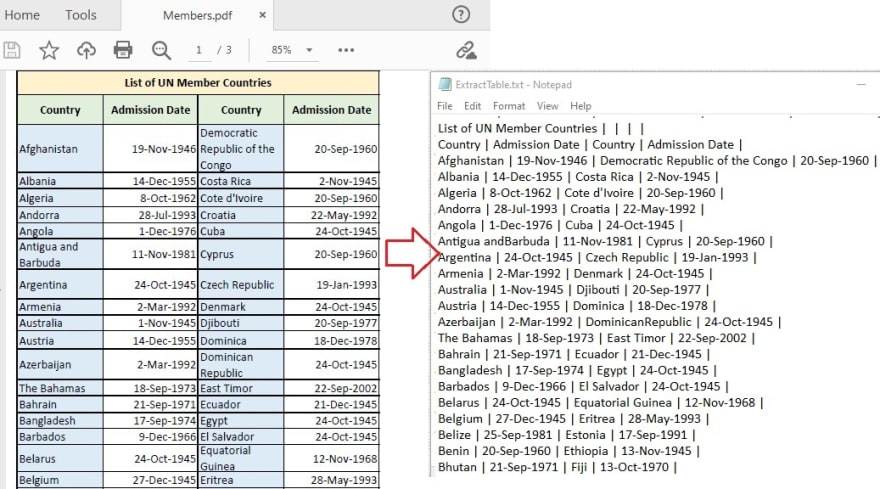
The PdfTableExtractor.extractTable(int pageIndex) method offered by Free Spire.PDF for Java allows you to detect and extract tables from a desired PDF page. The detailed steps and complete sample code are as follows.
- Load a sample PDF document using PdfDocument class.
- Create a StringBuilder instance and a PdfTableExtractor instance.
- Loop through the pages in the PDF, and then extract tables from each page into a PdfTable array using PdfTableExtractor.extractTable(int pageIndex) method.
- Loop through the tables in the array.
- Loop through the rows and columns in each table, and then extract data from each table cell using PdfTable.getText(int rowIndex, int columnIndex) method, then append the data to the StringBuilder instance using StringBuilder.append() method.
- Write the extracted data to a txt document using Writer.write() method.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
public class ExtractTableData {
public static void main(String []args) throws Exception {
//Load a sample PDF document
PdfDocument pdf = new PdfDocument("C:\\Users\\Administrator\\Desktop\\Members.pdf");
//Create a StringBuilder instance
StringBuilder builder = new StringBuilder();
//Create a PdfTableExtractor instance
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//Loop through the pages in the PDF
for (int pageIndex = 0; pageIndex < pdf.getPages().getCount(); pageIndex++) {
//Extract tables from the current page into a PdfTable array
PdfTable[] tableLists = extractor.extractTable(pageIndex);
//If any tables are found
if (tableLists != null && tableLists.length > 0) {
//Loop through the tables in the array
for (PdfTable table : tableLists) {
//Loop through the rows in the current table
for (int i = 0; i < table.getRowCount(); i++) {
//Loop through the columns in the current table
for (int j = 0; j < table.getColumnCount(); j++) {
//Extract data from the current table cell and append to the StringBuilder
String text = table.getText(i, j);
builder.append(text + " | ");
}
builder.append("\r\n");
}
}
}
}
//Write data into a .txt document
FileWriter fw = new FileWriter("ExtractTable.txt");
fw.write(builder.toString());
fw.flush();
fw.close();
}
}
This content originally appeared on DEV Community and was authored by carlwils
carlwils | Sciencx (2022-02-07T08:20:19+00:00) Extract Table Data from PDF Document Using Java. Retrieved from https://www.scien.cx/2022/02/07/extract-table-data-from-pdf-document-using-java/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.