
This content originally appeared on DEV Community and was authored by MariaZentsova
Many business use cases, such as competitor research, finding new customers or partners require a list of companies, that are operating in a particular field.
In my case, I needed a list of startups and investors, that work in clean tech. I decided to do this work in Sagemaker notebook, as it is a good environment for data science work, and allows easy access to all AWS resources.
AWS Comprehend, which I've used to extract the companies, is an out of the box Natural Language Processing service, that allows to perform Named Entity Recognition, text classification and topic modelling.
1. Setting IAM role permissions
AWS controls access to its services, using IAM roles. To use AWS Comprehend in a Sagemaker, we need to assign an access to this service to our role.
We could get a current role from a Sagemaker session.
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
Once we know, what role is used, we can attach AWS Comprehend permissions to it.
2. Fetching data from S3 bucket
For this analysis we need just a few libraries, such as boto3, sagemaker, pandas and seaborn.
import boto3
import pandas as pd
import sagemaker
from tqdm.notebook import tqdm
tqdm.pandas()
import seaborn as sns
sns.set_theme(style="whitegrid")
The source data for analysis are TechCrunch articles from 2012 to 2021, filtered by clean tech category with machine learning. Let's fetch the data from s3 bucket. We are particularly interested in clean_text field, which contains a cleaned body of the article.
# Load the dataset
s3 = boto3.client('s3')
obj = s3.get_object(Bucket = 'mysustinero',Key = 'cleantechs_predicted.csv')
techcrunch_data = pd.read_csv(obj['Body'])

3. Running AWS Comprehend and investigating the response
Let's run AWS Comprehend for a single article and investigate the result.
response = client.batch_detect_entities(
TextList=[
techcrunch_data['clean_text'][819],
],
LanguageCode='en'
)
Response is a JSON object, which contains extracted entities with the accuracy and offsets. There are a number of entities available, including ORGANIZATION, EVENT, PERSON and LOCATION.
response['ResultList'][0]['Entities']

4. Applying entity extraction to the whole dataset
Once I understood the structure of the response, it was pretty easy to write a function that extracts a list of companies from the text.
def get_organizations(text):
response = client.batch_detect_entities(TextList=[text[0:4900]],LanguageCode='en')
# getting all entities
data = response['ResultList'][0]['Entities']
# get all dictionaries that contain orgs
orgs = [d for d in data if d['Type'] == 'ORGANIZATION']
# extract unique orgs, using set comprehension
unique_orgs = {d['Text'] for d in orgs}
return unique_orgs
Then it's time to apply it to the whole dataset.
df['orgs_list'] = df['clean_text'].progress_apply(get_organizations)
To normalise a dataset, so there is a link between article url and company name, I use pandas explode() function.
# reshape a dataset
result_final = result.explode('orgs_list')
Let's calculate how many unique companies we extracted using this method.
orgs = result_final['orgs_list'].unique()
len(orgs)
# 5507
5. Analyse what Clean Tech companies Techcrunch writes about
After extracting company names, we could run different kinds of analysis. I wanted to extract data what companies in this field TechCrunch writes most about.
#calculate companies mentioned
dff = result_final.groupby(['orgs_list']).size().reset_index()
dff = dff.rename(columns= {0: 'count', 'orgs': 'company'})
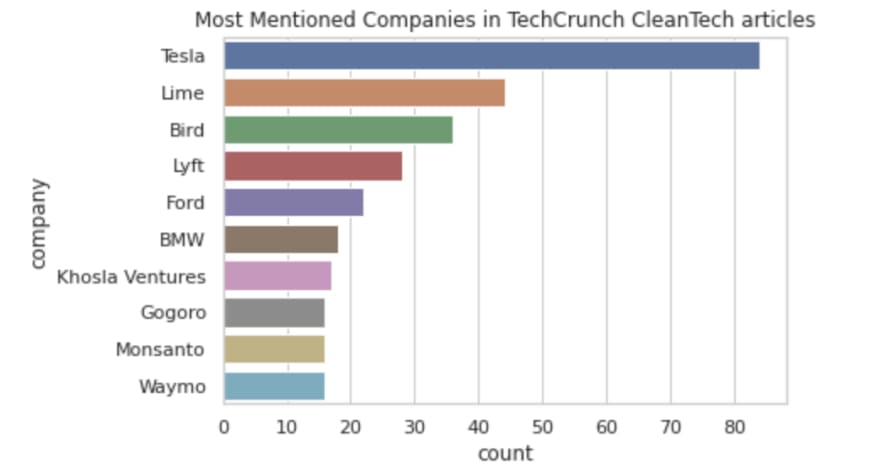
# Generating most popular cleantech companies
dff_chart=dff[dff['count']>15]
categories_chart = sns.barplot(
y="company",
x="count",
data= dff_chart,
order=dff_chart
.sort_values('count', ascending=False).company).set(title='Most Mentioned Companies in TechCrunch CleanTech articles')
We see that Tesla mentioned quite a lot of time in articles about clean tech amongst other companies. Interestingly Monsanto is also mentioned quite a lot, probably in a comparison to clean tech start ups.
Using AWS Comprehend allowed me to quickly generate a list of companies in clean tech ecosystem. This saves a lot of time versus a traditional method, when such datasets are created manually by an analyst.
As the list is generated by machine learning there are bound to be mistakes, and companies not in clean tech area, that are just mentioned in the articles. However, quality checking a generated list is still much more simple and fast.
This content originally appeared on DEV Community and was authored by MariaZentsova
MariaZentsova | Sciencx (2022-03-22T17:32:32+00:00) Extracting company names from news using AWS Comprehend. Retrieved from https://www.scien.cx/2022/03/22/extracting-company-names-from-news-using-aws-comprehend/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.