
This content originally appeared on DEV Community and was authored by Arika O
In the last article we talked about navigation, the first step the browser takes to display the websites. Today we'll move onto the next step and see how resources get fetched.
2. DATA FETCHING
HTTP Request
After we established a secure connection with the server, the browser will send an initial HTTP GET request. First, the browser will request the markup (HTML) document for the page. It will do this using the HTTP protocol.
HTTP (Hypertext Transfer Protocol) is a protocol for fetching resources such as HTML documents. It is the foundation of any data exchange on the Web and it is a client-server protocol, which means requests are initiated by the recipient, usually the Web browser.

The method - e.g: POST, GET, PUT, PATCH, DELETE etc
URI - stands for Uniform Resource Identifier. URIs and used to identify abstract or physical resources on the Internet, resources like websites or email addresses. An URI can have up to 5 parts:
- scheme: used to say what protocol is being used
- authority: used to identify the domain
- path: used to show the exact path to the resource
- query: used to represent a request action
- fragment: used to refer to a part of a resource
// URI parts
scheme :// authority path ? query # fragment
//URI example
https://example.com/users/user?name=Alice#address
https: // scheme name
example.com // authority
users/user // path
name=Alice // query
address // fragment
HTTP header fields - are a list of strings sent and received by both the client program and server on every HTTP request and response (they are usually invisibl for the end-user). In the case of requests, they contain more information about the resource to be fetched or about the browser requesting the resource.
If you want to see how these headers look like, go to Chrome and open the Developer tools (F12). Go to the Network tab and select FETCH/XHR. In the screen shot bellow I just made a Google search for Palm Springs and this is how the request headers look like:

HTTP Response
Once the server receives the request, it will process it and reply with an HTTP response. Attached to the body of the response we can find all relevant headers and the contents of the HTML document we requested.

Status code - e.g: 200, 400, 401, 504 Gateway Timeout etc (we aim for a 200 status code, since it tells us everything went ok ad the request is successfull)
Response header fields - hold additional information about the response, like its location or about the server providing it.
An example of an HTML document can look something like:
<!doctype HTML>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>This is my page</title>
<link rel="stylesheet" src="styles.css"/>
<script src="mainScripts.js"></script>
</head>
<body>
<h1 class="heading">This is my page</h1>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="myImage.jpg" alt="image description"/>
</div>
<script src="sideEffectsScripts.js"></script>
</body>
</html>
For the same google search I mentioned earlier, this is how the reponse headers look like:
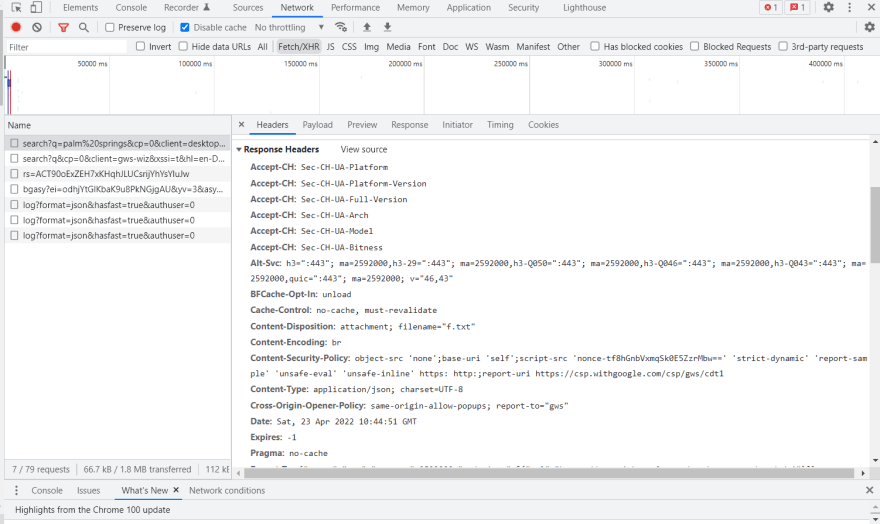
If we take a look at the HTML document, we see that it refrences different CSS and Javascript files. These files will no be requested until the browser won't encounter these links but this doesn't happen in this step, but in the parsing phase which we'll discuss in the next articles. At this point in time, only the HTML is requested and received from the server.
The response for this initial request contains the first byte of data received. Time to First Byte (TTFB) is the time between when the user made the request (by typing the website's name in the address bar) and the receipt of the first packet of HTML (which is usually 14kb).
TCP Slow Start and congestion algorithms
TCP slow start is an algorithm that balances the speed of a network connection. The first data packet will be 14kb (or smaller) and the way it works is that the amount of data transmitted is increased gradually until a predetermined treshold is reached. After each packet of data is received from the server, the client responds with an ACK message. Since the connection has a limited capacity, if the server sends too many packets too quickly, they will be dropped. The client won't send any ACK messages so the server will interpret this as congestion. This is where congestion algorithms come into play. They monitor this flow of sent packets and ACK messages to determine a rate at which traffic is sent to the network and create a steady traffic stream.
This content originally appeared on DEV Community and was authored by Arika O
Arika O | Sciencx (2022-04-23T11:19:19+00:00) How web browsers work – part 2 (with illustrations)🚀. Retrieved from https://www.scien.cx/2022/04/23/how-web-browsers-work-part-2-with-illustrations%f0%9f%9a%80/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.