
This content originally appeared on Level Up Coding - Medium and was authored by Vadym Barylo
Valid test pyramid shape and good test coverage are just side effects of following TDD practices. This topic was covered in detail in the previous post.
Following the “tests first” paradigm also helps to define module API in a more consumer-friendly manner, because the tests become actually early adopters of exposed component access points.
But how comprehensive is your protection from inadvertent API misuse to deliberate use in a wrong way? Is TDD enough to ensure that there is an accepted level of covering component behaviors and that no critical vulnerabilities are exposed?
✍ Saga about testing
“Most testers I’ve known are perverse enough that if you tell them the “happy path” through the application, that’s the last thing they’ll do.”
Release It!: Design and Deploy Production-Ready Software
I believe this statement can be accepted not only by testers but also by many software engineers who have tried to adopt an external library into their applications when the range of use-cases this library covers doesn’t include their specific one.

This is a very common problem in software engineering as libraries are built to solve specific needs and not always your requirements are in the range this library aims to cover. So time to time engineers needs to adopt the most appropriate library that is the most closer to their cases.
Very often the single-purpose library is used in surrounding areas because of already gained experience. So adopting it as a general-purpose component becomes easier than using more specialized. A good example is when Selenium becomes a de-facto all-purpose testing platform, including API and performance test areas.
✍ Saga about shared libraries
Common libraries are a way to encapsulate shared logic between different applications. This is a good solution to ensure behavioral consistency between services when all are based on single design rules or re-using common workflows.
Obviously, supporting a valid dependency graph of shared libraries is one more architectural challenge to take into account, so be careful with overloading this graph. This topic is well covered in this post, so will not stop more.
Another reason for using common libraries is to provide high-level abstractions for complex features, hiding implementation and protecting it from overriding by utilizing the OOP encapsulation.
An independent module is the same architecture quantum as the entire service because has its own consumers (other modules or services), own feature roadmap, deployment cycle, etc.
The only big difference — it is not a black box hidden from end-users, but yet another piece of code injected into existing architecture with full read access. So how to ensure that module is limited only to a set of use-cases, defined by the module creator, and does not have backdoors for incorrect use?
Not only public modules but also company private libraries should be revised from this perspective. Incorrect library use or use of non-documented features might produce unexpected side effects. And not always on purpose, but due to lack of documentation or technical expertise.
Sounds like a fully nondeterministic task? Probably yes, but maybe we can define some threshold so any results below this line indicate that we can’t recommend yet this library for further use.
So let’s break this challenging problem into subproblems:
- how to ensure that the library does not expose undocumented API?
- how to ensure document API covers only a defined set of use-cases and there are no critical side effects with improper API use?
⛅ Check for possible side-effects on existing API
What are unexpected side-effects from the developer’s perspective? I would feel uncomfortable when the designed API becomes sensitive to input in a not expected way and provides extended functionality or unexpected behavior based on this input.
How do we prove that API is doing only prescribed work and doing it right? Correct, covering code by unit, integration, and service tests.
How do we prove that tests are full and check not only the success path but all possible conditional flow feature support? Correct, by analyzing its coverage.
Can we ensure that good enough test coverage (e.g. 90+ %) solves our problem with detecting all possible information flows during execution with preventing unexpected side effects? Unfortunately no. It requires a third ingredient in this sauce — ensure our tests are covering all possible data mutations as well.
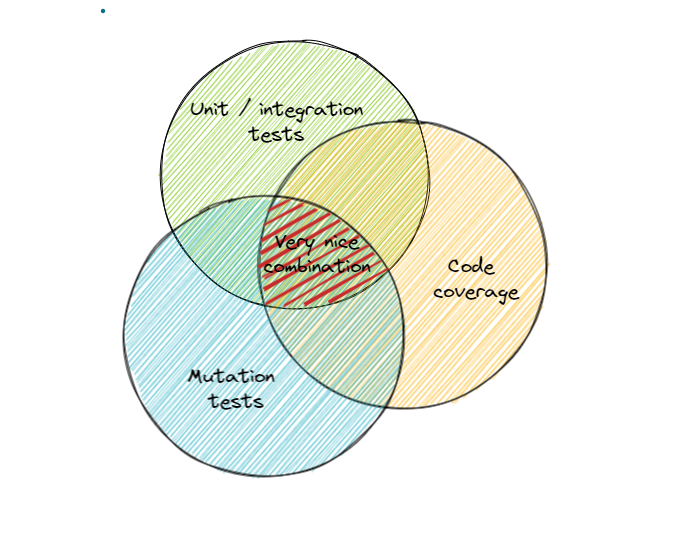
What does it mean “mutation” here? This is a specific measurement to ensure that test checks actual behavior but not just code execution flow, it is sensitive to edge cases, and it is not written only to pass code quality gate.
The combination of these 3 ingredients gives a very strong sauce:
- unit tests + coverage = 🗹 fullness of tests scenarios
- coverage + mutation tests =🗹 fullness of covered code that can signal errors when mutation applied
- unit tests + mutation tests = 🗹 fullness of checked scenarios
⚽ Let’s check it in practice
Source code: https://github.com/donvadicastro/docker-monitoring-stack
We will use the next tools for each verification stage:
- ⚡JUnit for unit and integration tests
- ⚡ SonarQube for measuring test coverage managed by sonarcloud.io
- ⚡ PITest for executing mutation tests
- ⚡ GitHub actions to automate verification
Our goal is to inspect published code (during Pull Request review) from all three perspectives: tests are passed, the number of tests is good enough to prove quality and tests are checking actual behaviors but not only flow completion.
And we want to fail the overall CI build if at least one of these checks is not passed.
🗹 Configuring unit tests gate
It is a simple enough step as JUnit is widely integrated into development culture, so many open-source and third-party plugins are present on the market to achieve requirements with no extra code. First is to include test run as part of CI process: gradle test later check execution results to make the decision about stage result and post it to PullRequest
- name: Report unit tests
uses: dorny/test-reporter@v1
if: always()
with:
name: Gradle Tests
path: '**/build/test-results/test/TEST-*.xml'
reporter: java-junit
fail-on-error: true
- name: Publish Unit Test Results
uses: EnricoMi/publish-unit-test-result-action@v1
if: always()
with: files: "**/build/test-results/test/TEST-*.xml"
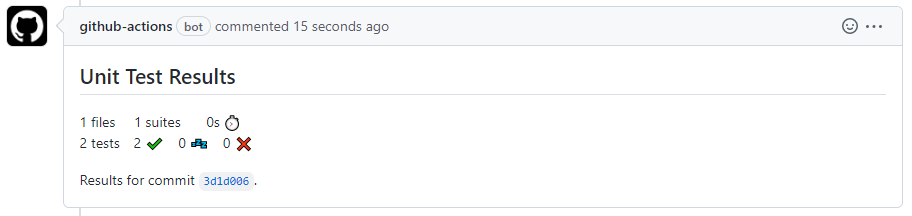
Once step completed — new comment will be published to pull request under verification. Example:
🗹 Configuring code coverage gate
We can use as a self-hosted SonarQube as well free cloud version for public projects. In this exercise sonarcloud.io Sonar cloud version is used, but docker provisioned Sonar declared in docker-compose configuration.
Additionally Sonar server and additional workspace info need to be added to project configuration file. Example:
systemProp.sonar.host.url=https://sonarcloud.io/
systemProp.sonar.login=
systemProp.sonar.projectKey=
systemProp.sonar.projectName=
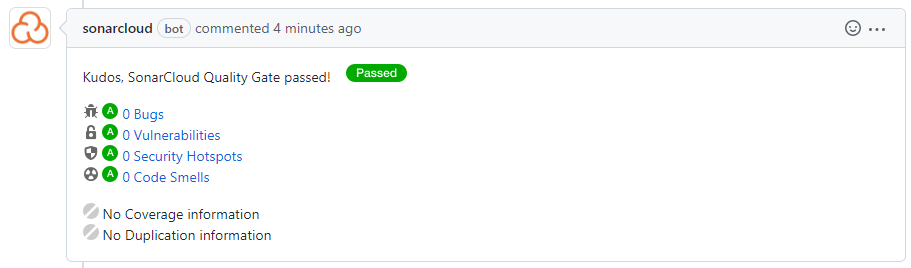
Once configured — one more comment will be published to pull request under verification. Example:
🗹 Configuring mutation tests gate
Adding support to run mutation tests as part of the verification pipeline, requires implementing next steps:
- registering pitest in project
plugins {
id 'info.solidsoft.pitest' version '1.7.4'
}- configuring new task “pitest”
pitest {
junit5PluginVersion = '0.15'
outputFormats = ['XML', 'HTML', 'CSV']
}- configuring CI step to run tests
- name: Mutation tests
run: gradle :application-backend:pitest
- configure CI step to publish results
- name: Comment PR
uses: machine-learning-apps/pr-comment@master
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
path: <path_to_report>
Once configured — one more comment will be published to pull request under verification. Example:
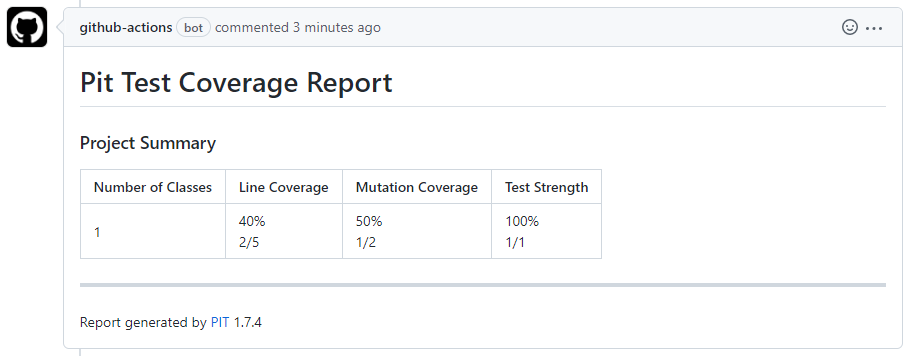
Wish you to have your continuous integration pipelines be the only source of trust to produce decisions about feature quality. This is a prerequisite for further fully automated production deployment pipelines.
Appreciate for your feedback.
Mutation testing as a more robust check of dependent libraries was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Vadym Barylo
Vadym Barylo | Sciencx (2022-05-03T11:44:09+00:00) Mutation testing as a more robust check of dependent libraries. Retrieved from https://www.scien.cx/2022/05/03/mutation-testing-as-a-more-robust-check-of-dependent-libraries/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.