
This content originally appeared on Level Up Coding - Medium and was authored by Aashirwad Kashyap
Building resilient data pipeline with Airflow as WMP, Hive for HDFS query and analysis and Superset for data visualisation
Data pipelines are critical for any organisation as they eliminate most of the manual steps from the process and enable a smooth, automated flow of data from one stage to another. They are essential for real-time analytics and help in making faster, data-driven decisions and build business insights (article performance, subjects' popularity, optimization if any, auto-recommendation etc.). As these pipelines are very critical, we decided the system/platform managing it must have the below SLA’s
- Handle Task dependencies
- Support concurrency (able to schedule Multiple Jobs at any point of time)
- Distributed System to handle Scalability
- Resilient to failures (comply with Murphy’s Law)
- Observability for Fast Debugging
- Monitoring (Actionable UI Layer/Dashboard)
Let’s discuss how do we build a resilient system adhering to the above SLAs with a practical real-world scenario. We’ll be dividing the discussion into two phases.
- We’ll discuss how we build a data pipeline to retrieve, transform and aggregate Glance news portal partners analytics data using airflow and hive in-order to build Insights and take data driven business decisions
- Deep dive into Airflow Architecture in-order to understand how a data pipeline works under the hood.
Data Pipeline in Action
We’ll be discussing how to build a resilient data pipeline using workflow management platform but first let’s dive into the problem statement.
Glance has several News-Portal partners who showcase their content (news, articles etc.) on the Lock Screen surface powered by glance and these news-portals have their analytics data (pageview's, bounce Rate, region wise Users etc. ) Captured on their Google Analytics account.
We needed a centralised Dashboard to view all the partners analytics data in order to build business Insights and data driven decisions. Until now this was a manual process where every partner used to submit daily analytics data and which were aggregated and updated locally in our systems. This process involves lot of manual work which is prone to human error’s resulting in building wrong insights and business decisions. This process needed to be automated end to end.

Looking at the problem statement it’s obvious we needed to build a resilient data pipeline which triggers daily and retrieves partners data -> aggregates it -> store in respective destination for consumption
Design Decisions (CRON vs AIRFLOW)
Scheduling of tasks is the core of any system managing the data pipelines and the two most widely used schedulers which we’ll be deep diving into are Cron and Airflow
Cron for Workflow Management: Cron is a well-known tried and tested approach to run tasks in scheduled manner but this too has some limitations such as
- Cron Job runs on a single machine and are not distributed and also it works well when fewer dependencies are involved. For e.g. consider the below case if any one of the jobs fails it will have a cascading effect
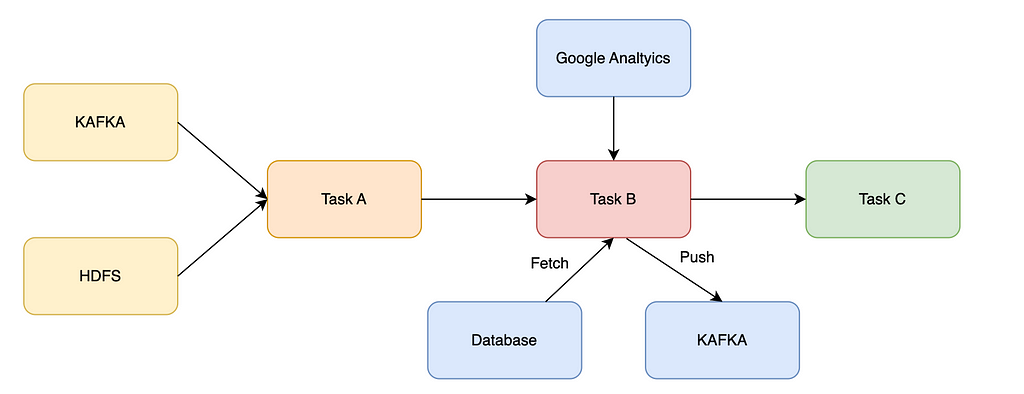
- As Cron Job doesn’t generate any meta data regarding task scheduling, execution, failures, retries etc. monitoring and debugging becomes a complex task which could grow exponentially in future.
Cron is not resilient in nature and also does not satisfy any of the listed SLA’s above. If your case is fairly simple with minimal to no dependency Cron works well else use an appropriate WMP which fits your requirement.
Airflow as WMP: Airflow is a platform that lets you build and run workflows. A workflow is represented as a DAG (a Directed Acyclic Graph, where one can define individual pieces of work as tasks) and unlike Cron is distributed in nature and built for resiliency. Let’s look at some of the supported feature
- Monitoring & observability
1. Graphical view of all the DAG in Pipeline and their status
2. Failures at Each Task/Subtask Level
3. Option to pause/start/stop DAG
4. View all Sensors/Triggers used - Metadata Generated
1. Next Scheduled Interval
2. Time taken by task and its subtask - Resiliency
1. configurable& forced Retries option
2. Backfill of Data in case of external Failures
3. Alerts for abrupt system behaviour - Workflow
1. control flow for dependency management
2. pre-defined operators & connectors to ingest data from various sources (databases, cloud storage, HDFS, cache etc.)
Airflow inherently supports all the listed SLA’s discussed previously and also provides a nice actionable dashboard for monitoring & observability and hence the default choice for our use case.
Implementation
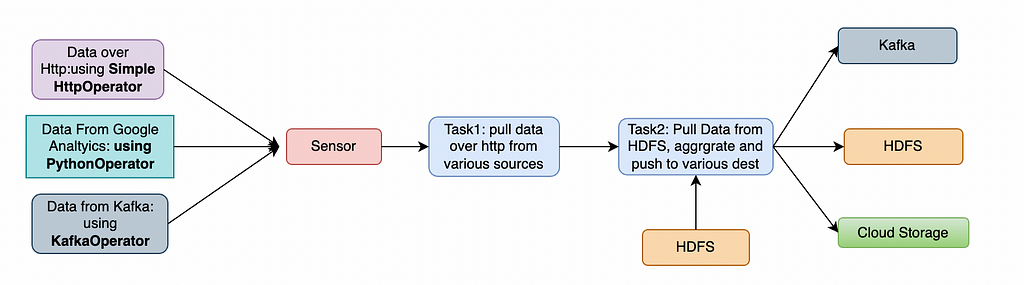
The below architecture on a high level uses Airflow to execute tasks asynchronously based on the specified tasks dependency in DAG and the result is transformed -> aggregated and stored in sink (GCS and HIVE) for later consumption.
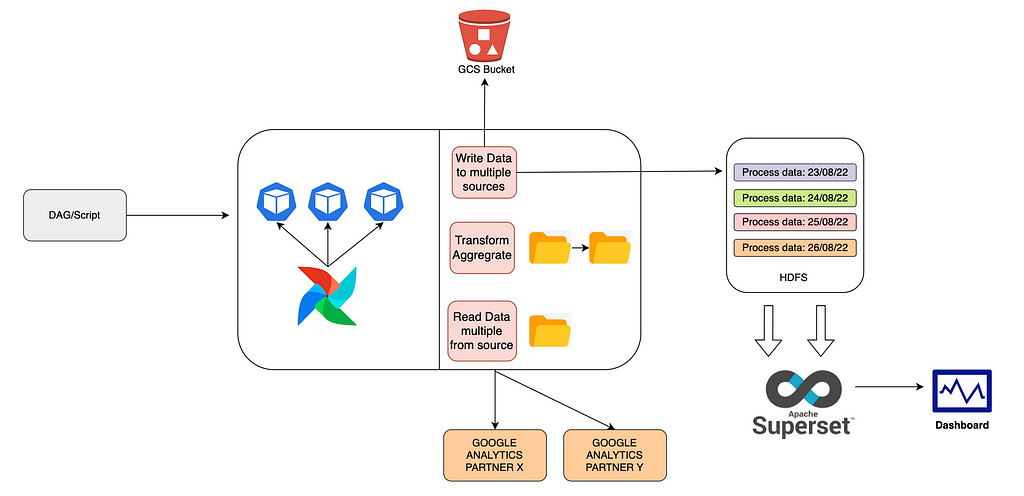
Deep Dive into the Architecture
- We’ll be defining our workflow as a DAG(python script specifying scheduling info and tasks to be performed) scheduled daily
- Below are respective tasks specified in DAG
- Task1: Retrieve and Transform each of the Partners analytics Data
- Task2: Partition the data based on process Date (in-order to fasten query load time) and push the transformed data to GCS Bucket
- Task3: Retrieve the data in GCS Bucket based on process Date and push the transformed data to HIVE
3. Airflow internally schedules and executes the specified tasks asynchronously (using pre-defined executors (celery or k8s) and worker nodes) based on the task dependency.
4. Once the Data is pushed superset would retrieve, aggregate the data from Hive Tables based on the process date range at scheduled interval and showcase the data on the dashboard.
Defining Workflow as DAG
- Every Dag need to have below mentioned properties out of which the most important are the
1. Schedule Interval: Depending on the usecase you can define your dag schedule as cron expression or some pre -defined tags (@daily, @weekly etc.) Below defined dag will run daily at UTC 3:00 am
2. Catchup: used when you need to backfill historic data. In order to accomplish this set past time start date and this field value to true
3. Retry_delay
default_args = {
'owner': 'GRAP',
'depends_on_past': False,
'start_date': datetime.datetime(2022, 9, 1),
'email': [alert_email],
'email_on_failure': True,
'email_on_retry': False,
'retries': 5,
'catchup': True,
'retry_delay': timedelta(minutes=30)
}dag = DAG(
dag_id,
default_args=default_args,
schedule_interval='0 3 * * *',
max_active_runs=1,
catchup=True,
tags=['DAILY','ANALYTICS']
)
- Once DAG is initialised next step is to define Tasks. We primarily have two tasks
1. Fetch partner analytics Data from respective partner Google analytics account -> aggregate -> push to GCP cloud storage. Here we have defined a task with a python callable function to execute and op_kwargs represent the parameters to be provided to the function.You can even break this function into multiple task if required and use Xcoms to pass data between the task instances which is bit tricky but provides more readability.
fetch_page_analytics_api_data = PythonOperator(
task_id='fetch_partner_analytics',
python_callable=fetch_partner_analytics,
op_kwargs={ 'dateTemp': '{{ ds }}'},
provide_context=True,
dag=dag
)
2. Next task is to retrieve data from Gcp Cloud storage and push this to Hive(HDFS) partitioned by process date.
partition_registry_new = HiveOperator(
hql=register_new_partitions(table_name),
hive_cli_conn_id='prod_hive_connection_glance_cube',
schema='glance_google_analytics',
hiveconf_jinja_translate=True,
task_id='add_partition_in_hive',
dag=dag
)
- once the respective tasks have been defined, we need to introduce dependency between them if any (here we want data to fetched first before making any partition)
fetch_page_analytics_api_data >> partition_registry_new
- If no dependency is provided airflow due to its distributed nature will be executing the tasks in parallel.
This is how one can define a DAG in Airflow with Tasks and introduce dependency between them. Tasks implementation is not shown above as it may vary depending on the use-case and style of architecting your code will leave up to the user for exploration.
Airflow Architecture

Airflow on a high level is a queueing system build over Meta-Database which stores tasks along with its meta data in a queue and a scheduler which has access to the Meta-Data schedules (rearrange, set priority, remove expired tasks etc.) the tasks in the queue and provides it to the executor which has its own worker nodes to execute tasks in parallel
- DAG: A workflow is represented as a DAG (a Directed Acyclic Graph) and contains individual pieces of work called Tasks. A DAG specifies the dependencies between Tasks, and the order in which to execute them and run retries
1. Tasks: In a DAG you can define multiple tasks and describe what each task would do, be it fetching data, running analysis, triggering other systems, or more.
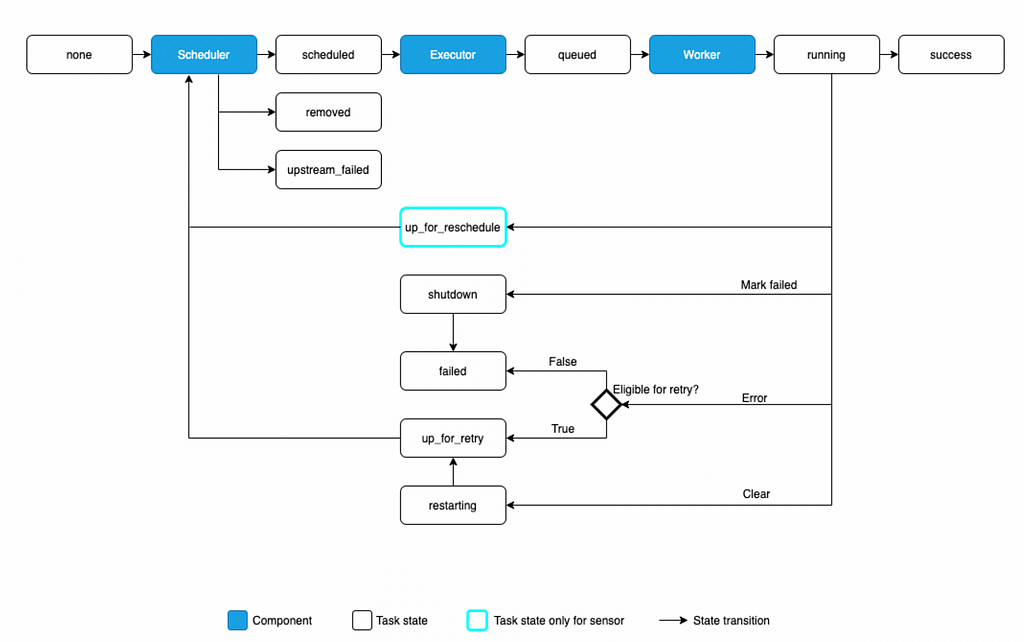
2. Operators: An Operator is a template for a predefined task and you can use multiple operators in a task as per the requirements (for e.g.
->BashOperator: to execute bash commands
->Python Operator: to execute arbitrary python function
->SimpleHttpOperator: to call an endpoint over HTTP)
3. Sensors: a special subclass of Operators which are entirely about waiting for an external event to happen
- Scheduler: Airflow scheduler is a process which accesses all DAG’s and their tasks through Meta-Database performs following actions
1. monitors task and decides tasks priority and execution
2. triggers tasks once their dependencies are complete
3. submits tasks to the executor for execution - Executor: Airflow Executor receives task instance to run from scheduler and puts it into the queue which are later picked up by worker nodes to execute the tasks. There are basically two types of executors
1. Local Executors: those that run tasks locally (inside the scheduler process) mainly used for single machine installations local testing or for smaller workloads
2. Remote Executors: those that run their tasks remotely (usually via a pool of workers) as shown above (for e.g. Celery, Kubernetes, CeleryKubernetes executors) - Webserver: Airflow webserver presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.
Do checkout if interested in more backend stuff 🙂
- Computing Live stream viewers count in real time at High Scale !! | Glance
- How to automate application deployment with CI/CD using Google Kubernetes Engine, Jenkins, DockerHub and ArgoCD
Parting Notes
I hope the above discussion was fruitful and helped you learn a thing or two about working with WMP and building Distributed resilient data pipelines. Shoutout to Mahesh and Vaibhav for the support in building this as well as Priyanshu Dubey, Kanishk Mehta, Shoaib for providing the opportunity to build something awesome.
Beyond Cron: Building Resilient Data Pipelines Using Workflow Management Platform (Airflow) was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Aashirwad Kashyap
Aashirwad Kashyap | Sciencx (2022-12-23T17:01:46+00:00) Beyond Cron: Building Resilient Data Pipelines Using Workflow Management Platform (Airflow). Retrieved from https://www.scien.cx/2022/12/23/beyond-cron-building-resilient-data-pipelines-using-workflow-management-platform-airflow/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.