
This content originally appeared on Level Up Coding - Medium and was authored by Anirban Banerjee
Databricks Deconstructed: Understanding the Internals
What happens when you create Databricks Instance? What happens when you spin off new cluster? Curious? Then this blog is for you…

Multiple time I have been asked this question. To be very frankly I have never thought about this. How often we do thing about this, becuase this is just a another service avaiable on cloud which can be avaiable on deman.
So, on one lazy Sunday, I fired up the laptop and plugged the headphone to find the answer. So are you with me.

For this we have selected Azure as cloud provider, but it is more or less same in other cloud provider like AWS or GCP.
So, to start let’s start with basic and let’s create the Databricks instance first. In this demo, we are going to spin off premium based Databricks on azure.
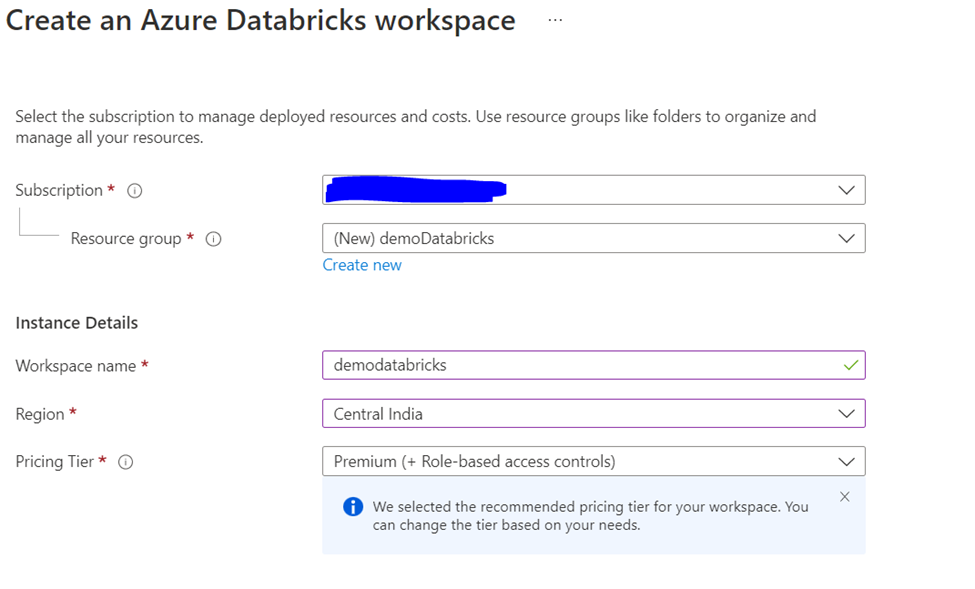
In the networking tab let’s keep things as it. In case if you already have existing vnet then you can choose this option. It is not possible to change the networking once the instance is created.
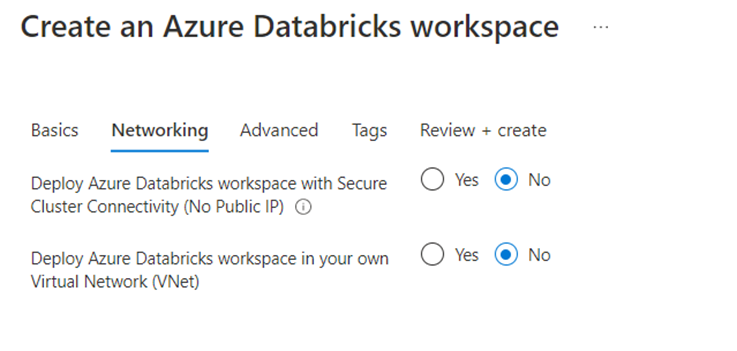
We will enable the infrastructure encryption.
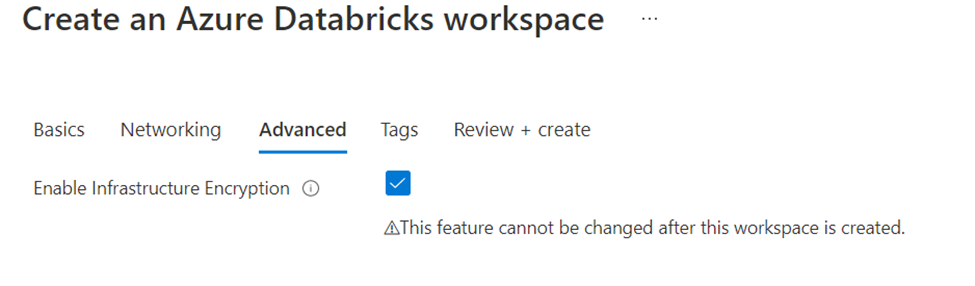
We will add few tags
and will hit the create button.
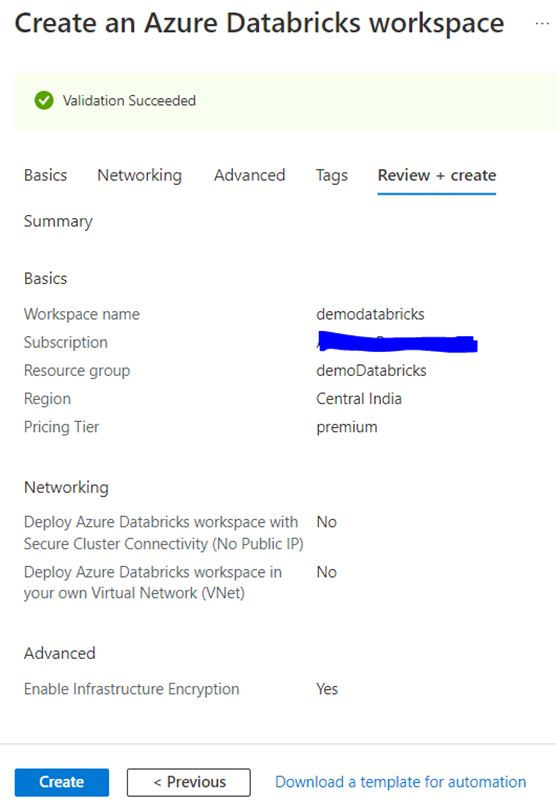
Once the Databricks instance is created we will go to the resource group to see what all the components has been created.
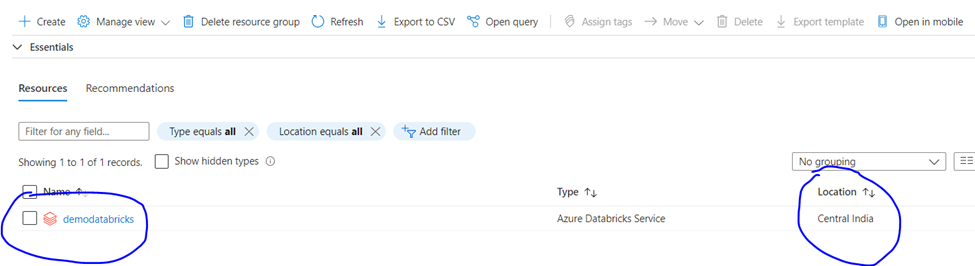
As you can see the location is Central India same as what we have selected earlier. But what about other option. Where Databricks will store the data (I mean where is famous dbfs location).
To view this, we have to go to the all resource group page. There we can find the other newly created resource group.
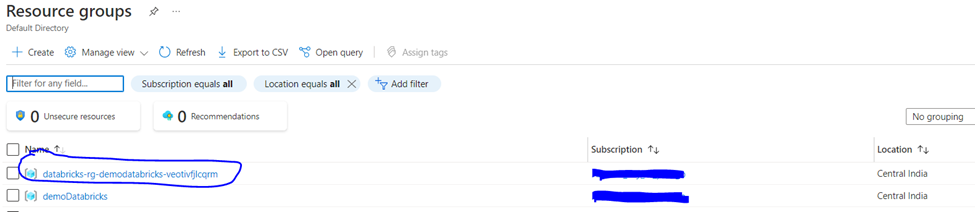
As you can see there is resource group named databricks-rg-demodatabricks-* has been generated. We will go to the resource group and check what’s inside. As you can see following components were created.
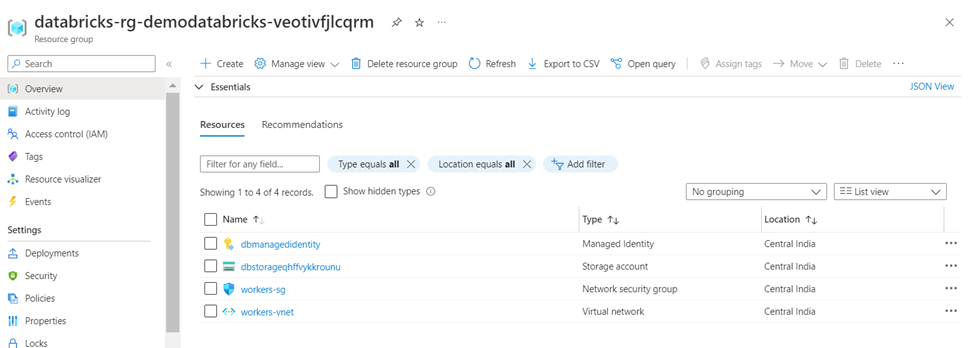
- Managed Identity
- Storage account
- Network security group •
- Virtual network
Let’s try to understand what each components do.
Managed Identity –This manages the authentication and help user to login. It is connected with Azure AD.
Storage account — This is where you store your data in Databricks. If you don’t mount any other storage location.
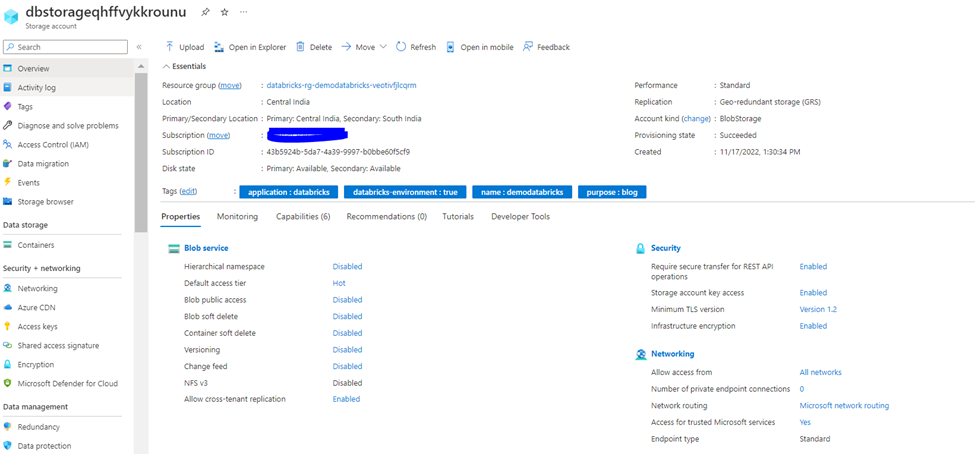
As you can see by default the storage account is created with GRS option enabled and account type BlobStorage and Hierarchical namespace is disabled (that means it is not ADLS).
Network security group — it contains security rules that allow or deny inbound network traffic to, or outbound network traffic from, several types of Azure resources. For example here are the default rules
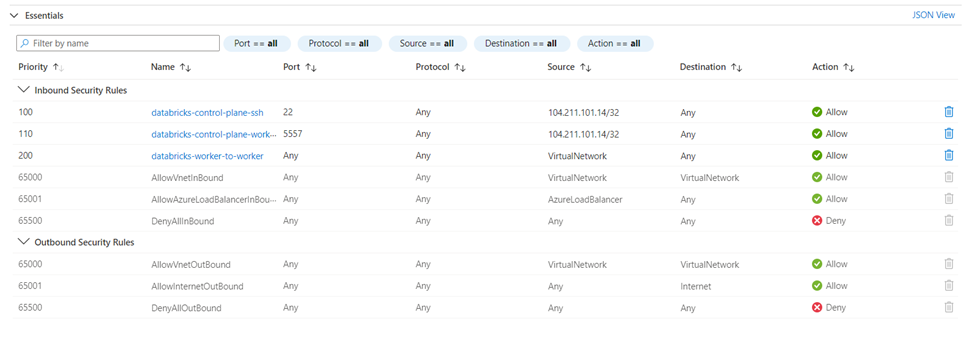
VNET — It is the virtual private network for the Databricks. In case if you already have existing vnet and you want to use it then that need to be selected at the time of Databricks creation. It will contact the public and private subnets and each subnet is connect with the network security group (NSG). In this case it is connected to the NSG that was created.

So far so good.
Now let’s connect to Databricks and try to create a cluster, a multi node cluster and let’s try to understand what happens internally when we do that.
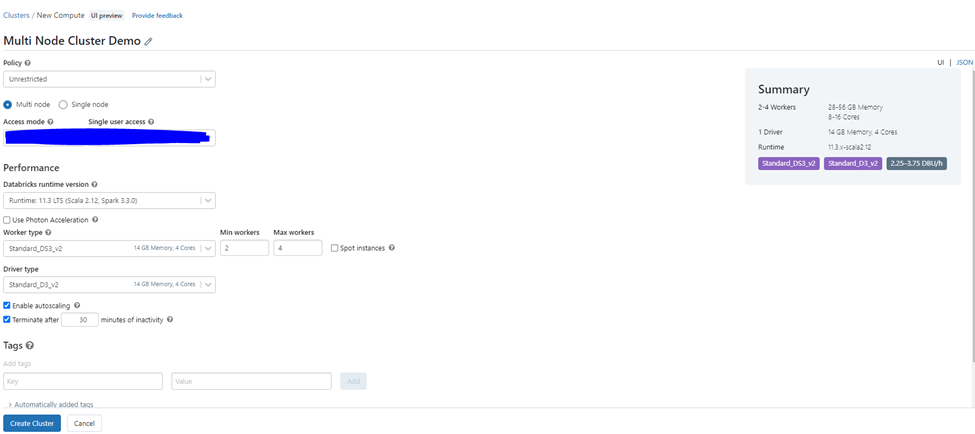
In this demo, we are creating Multi node cluster, with 11.3 Databricks runtime version, worked type is 2 to 8.
If you look closely, we have selected different types of nodes for worker and driver. For worker Standard_DS3_V2 whereas for driver Standard_D3_V2.
Note — While selecting do check out the DBU unit. The more DBU unit more cost will be accrued. Chose the driver and worked node based upon application workload.
Now let’s see what happen when this cluster (multimode cluster) is created.
If we go the previous resource group, then we can see lot of new components are created.
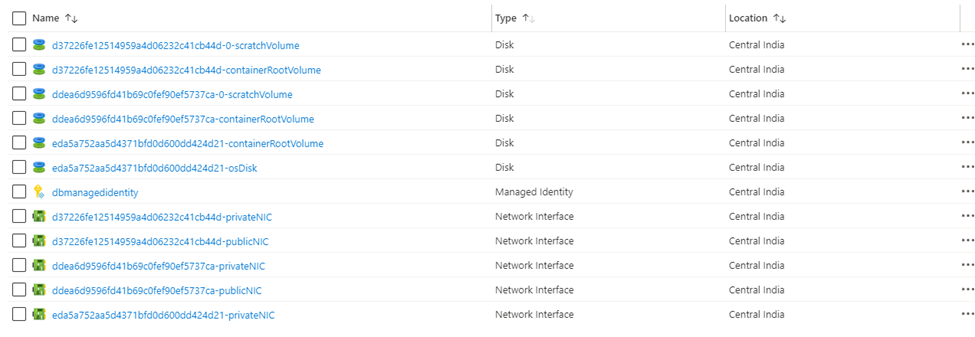
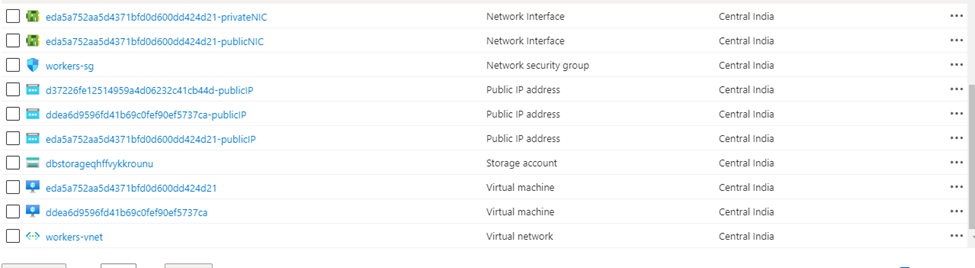
So, this is what happened internally. Based upon the cluster criteria it spins off the VM.

In this case two VM has been created, one is for worker node, and another is for driver node. For example, This one is worked node, because this is same worker type, we have selected while cluster creation. Also, you can see what kind of OS it’s running (In this case it is using Ubuntu 18.04 under the hood).
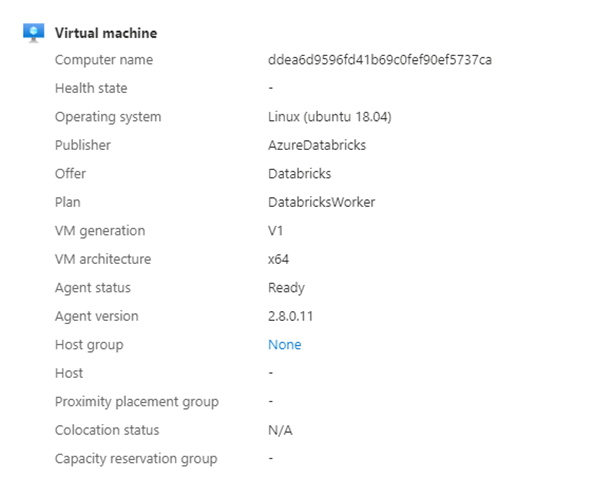
As the VM is created so it will create multiple Disk, network interface, public address.
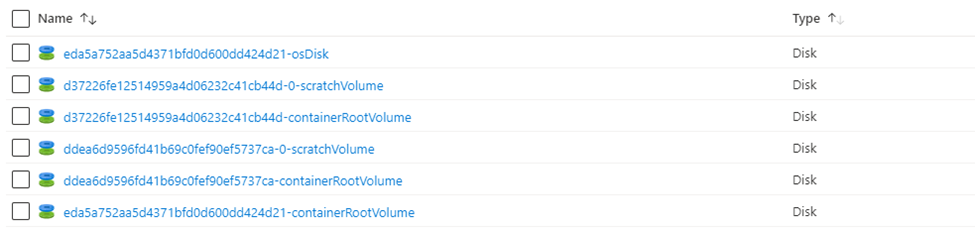


When the autoscaling is turned on in that case based upon the workload Databricks will automatically spin off extra worker node (VM in this case) .
As you can see based upon the cluster configuration it will create the driver nodes, worker nodes and associated other components.
Now in case if you stop the cluster the components will remains, but in case the cluster is deleted from Databricks Compute page then the components will also be deleted.
For example, after deleting the cluster the resource group came to the earlier stage (somewhat).
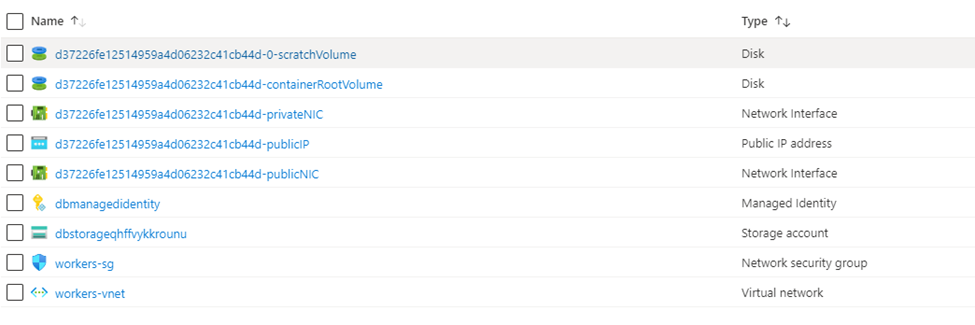
As you can see after cluster deletion most of the components like VM’s are deleted but network interface and public IP address, few disk remaining.
This will be reused once you will create another cluster.
Limitation
It is not possible to modify any of this component. Even though I am the owner of this subscription, but I can’t modify anything.
For example, if I try to delete any components, let’s say Data Disk it will throw the following error.
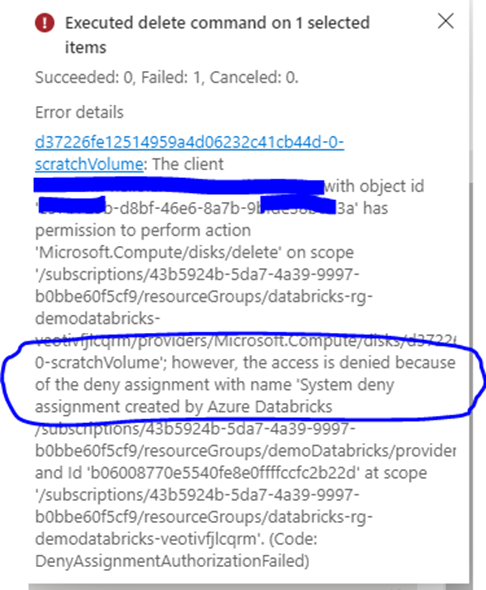
So even though you are the owner of the subscription you can’t modify the components that are being created by Databricks internally.
That’s it from me. Hope this helps you to understand the system better.
Till next time Happy Learning!
The Internals of Databricks was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Anirban Banerjee
Anirban Banerjee | Sciencx (2023-01-19T14:51:10+00:00) The Internals of Databricks. Retrieved from https://www.scien.cx/2023/01/19/the-internals-of-databricks/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.