
This content originally appeared on DEV Community 👩💻👨💻 and was authored by EQ LAB
1. Intro
Contrary to its commonly-praised simplicity, Solidity is no joke. Don’t be deceived by its outward resemblance with general-purpose programming languages: Solidity and Ethereum run-time environment itself are fraught with many ‘traps and pitfalls’, which, being stumbled upon, can greatly increase the time for debugging.
Here are just some of the tricky peculiarities:
- There are several different types of memory available to the contract;
- Turing incompleteness (although there are almost no restrictions compared to Bitcoin)
- The basic data type is a 256-bit integer (32 bytes);
- The byte order is big-endian, unlike in x86, where it is little-endian;
- The solidity compiler may generate an error without specifying a line or a source file which it could not compile;
- Some seemingly innocuous and concise language constructs can unfold into a large number of inefficient bytecode.
In this post we delve deeper into the latter intricacy and will pin down what exactly the compiler turns solidity code into. For such purposes, disassemblers and decompilers are commonly used.
Using a disassembler on its own isn’t trivial. You need to be well versed in the instructions of the Ethereum virtual machine, bear in mind an insane amount of facts and precedents, mentally perform stack operations, and understand the nuances of Ethereum inner workings. Searching for compilation results for code sections of interest in the assembler commands listing is a long and exhausting task. Here the decompiler can certainly come in handy.
Decompilers accept byte-code as an input and restore the high-level code in accordance with a specific set of heuristics. With such code at hand it’s easier to compare blocks of source code with assembler instructions. The decompiler requires only bytecode to work, if any. It can also retrieve the bytecode by itself, if the working network and the contract address are specified.
However, the output code of the decompiler is very different from the original one. There are several reasons for that. First of all, there aren’t yet any well-developed decompilers for Solidity, which implies that you need to be ready for all sorts of bugs and glitches. Moreover, as source-code variable names are often lost during compiling, the decompiler is forced to substitute them with its own, devoid of any meaning (a, b, c, d, ... or var1, var2, var3, ...). Such dissimilarities lead to the need for another time-consuming source code mapping and manual collation.
Thus, it takes a lot of time and effort to figure out what several problem lines of code on solidity turn into. However, there is a better way.
The most popular framework for working with Solidity code is Truffle. When compiling, in addition to the bytecode of the contract, it generates plenty of other useful data. And it is this information which will help us in our endeavours!
Using this data we can form a comparison of the source code and the instructions in two convenient views at once: either matching a source-code to the instructions or the other way around. Now, let’s look at a simplified representation of “instruction — code fragment”.
2. Mapping instructions with code fragments
After a successful contract compilation, Truffle writes a set of json-files to the build/contracts subdirectory of the project. Each of these files corresponds to a source-code file in Solidity and contains the following information:
- Contract bytecode;
- Abi (the information required to call the methods of the contract and refer to its fields);
- Contract source code;
- Source map;
- Abstract syntax tree;
- Contract address after deploying to the network.
For our purposes, we will consider Contract source code, Contract bytecode and Source map. While the first one is more or less obvious, the other two need to be discussed in more detail. Let's start by looking at the Source map.
2.1. Source Map
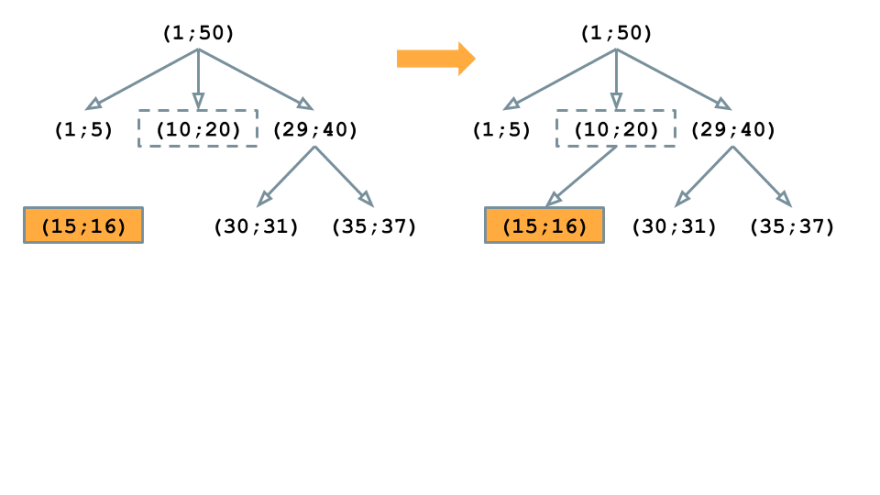
The purpose of the Source map is to match each contract instruction to the section of the source code from which it was generated. To make the matching possible, the address of the source code fragment is stored in the source map for every instruction. Simple compression is used to save storage space: certain address fields are omitted if they are the same as in the previous instruction.
Now let's look at the Source map format. The delimiters are semicolon and colon: the former is used between the source map elements, and the latter — between the fields in the element. The field consists of three main elements determining the address of the corresponding fragment of the source code (in order of succession: offset from the beginning of the file, fragment length, file identifier). The fourth element is the type of jump instruction, but it isn’t important for source mapping.

The figure above shows the beginning of the source map, which contains information for 5 instructions. While the instr1 element contains all fields, the instr2 and instr3 are empty, which means that the address of the source code fragment for the second and the third instructions in the contract bytecode is the same as for instr1. In the instr4 only the first two fields are set, indicating that only the offset and length have changed, with the file ID and the type of transition instruction unchanged. In the instr5 there are three fields, so only the type of transition instruction remains the same as in instr1. A value of -1 in the file ID field indicates that the instruction does not match any of the user source files.
To sort through the code parsing, first let’s break down the Source map into elements:
const items = sourceMap.split(';');
Now go through them, storing current field values in the accumulator in case the following elements will lack the data in one or more fields. Even though, at first glance, it seems like the Array.prototype.reduce() function can be of use, there are better options. It is inconvenient to use, for you need to take care of saving the state of the accumulator and aggregating the results every step of the way. The scan() function is arguably better suited for our purposes:
function scan(arr, reducer, initialValue) {
let accumulator = initialValue;
const result = [];
for (const currValue of arr) {
const curr = reducer(accumulator, currValue);
accumulator = curr;
result.push(curr); }
return result;
}
It stores the accumulator values at each step by design, which is exactly what we need in this case. With the help of **scan() **it is now easy to process all the Source map elements:
scan(items, sourceMapReducer, [0, 0, 0, '-', -1]);
The sourceMapReducer() function splits each Source map element into separate fields. At the same time, we save the record number in the Source map, as it will be needed later. If a value is missing, the respective one from the accumulator is taken.
function sourceMapReducer(acc, curr) {
const parts = curr.split(':');
const fullParts = [];
for (let i = 0; i < 4; i++) {
const fullPart = parts[i] ? parts[i] : acc[i];
fullParts.push(fullPart);
}
const newAcc = [
parseInt(fullParts[0]),
parseInt(fullParts[1]),
parseInt(fullParts[2]),
fullParts[3],
acc[4] + 1
];
return newAcc;
}
2.2. Contract bytecode
In json, bytecode is represented as a huge number in hexadecimal notation.
The EVM (Ethereum Virtual Machine) bytecode format is quite simple. All commands fit into one byte, with only exception being the instructions which load constants onto the stack. The size of the constant can vary from 1 byte to 32, and it is encoded in the first byte of the instruction. The remaining bytes contain a constant.
Bytecode parsing can be narrowed down to a sequential byte reading of a hexadecimal number. If the byte read is a constant loading instruction, we determine the number of bytes and immediately read the whole constant.
function parseBytesToInstructions(bytes) {
const instructions = [];
let i = 0;
while (i < bytes.length) {
const byte = bytes[i];
let instruction = [];
if (firstPushInstructionCode <= byte && byte <= lastPushInstructionCode) {
const pushDataLength = byte - firstPushInstructionCode + 1;
const pushDataStart = i + 1;
const pushData = bytes.slice(pushDataStart, pushDataStart + pushDataLength);
instruction = [byte, ...pushData];
i += pushDataLength + 1;
} else {
instruction = [byte];
i++;
}
instructions.push(instruction);
}
return instructions;
}
2.3. Aggregating the data collected
Now we have all the information required to form the first representation: an array with disassembled contract instructions, and another array with data sufficient to determine the corresponding block of source code for each instruction. Therefore, to create the “instruction — code fragment” representation, we can simply go through these two arrays simultaneously “gluing together” information from them elementwise.
3. Mapping code snippets with instructions
It may seem that by constructing the “instruction — source code” representation in the previous section, we killed two birds with one stone and there’s nothing left to do to form the “source code — instruction” representation. This would be true, indeed, if a single instruction in the source map would match exactly one line of source code. Unfortunately, that’s not the case.
One instruction can be assigned to several lines in the source code file at once. Moreover, instructions can refer to the whole method body or even to the whole contract! Quite often a hundred consecutive instructions are tied to the entire code of the one contract. The following bunch of instructions, quite as big as the previous one, is tied to some method of the contract, and the next bunch — to the whole contract again. How useful such a flow with loads of duplicate lines of source code can be is very much in question.
The better solution is to build a tree structure from the blocks of code, integrating the smaller ones (contract methods) into large blocks (the contract itself). Then to each node of this tree we can tie all the corresponding instructions. The data structure like that is way easier to analyze.
3.1. Building a tree
We will build a structure step by step, iterating through all contract instructions and adding them one by one to the tree. Two blocks of source code can be in one of the following relationships:
- blocks are equal
- the first block contains the second
- the first block is included in the second
- blocks intersect
- blocks do not intersect
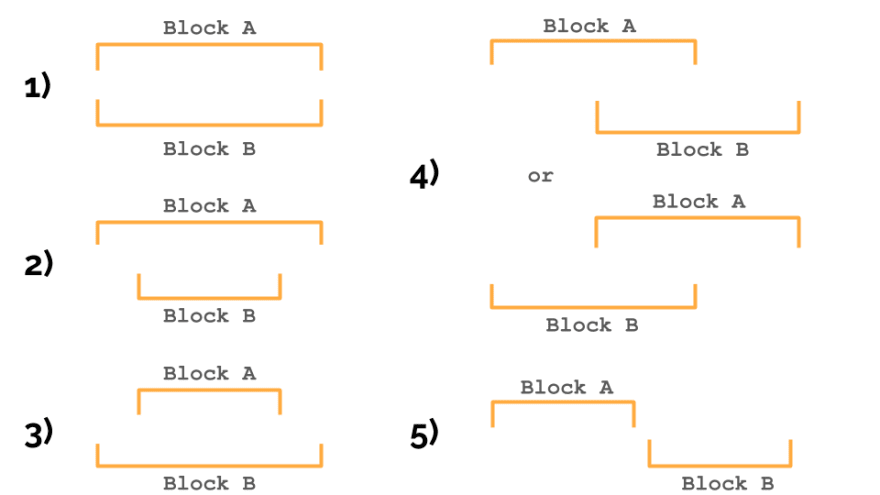
Now, when we khow to define the relationship between the two blocks, we can build our tree with the addNode() function. It finds the right place for a new block in the tree, recursively scanning it starting from the root. Let's look at a simplified version this function:
function addNode(currentNode, block) {
const relation = classifyBlock(currentNode.block, block);
outer:
switch (relation) {
case equalBlock:
// do nothing
break;
case childBlock:
const [children, nonChildren] = splitChildren(currentNode.children, block);
if (children) {
currentNode.children = [
...nonChildren,
createNode(block, children),
];
} else {
for (const childNode of currentNode.children) {
const childRelation = classifyBlock(childNode.block, block);
switch (childRelation) {
case childBlock:
addNode(childNode, block);
break outer;
case neighborhoodBlock:
continue;
default:
throw new Error('Unknown relation');
}
}
currentNode.children.add(createNode(block));
}
break;
default:
throw new Error('Unknown relation');
}
}
First, we define the relation of the added block to the block of the current node in the tree (line 2). If the blocks are equal, it means that the block already exists in the tree and no further action is required (lines 6-8).
Where it gets interesting is when the block under consideration is a child of the block of the current node (lines 7-31). Here we need to consider three possible scenarios: The new block is the parent for some child blocks of the current node (lines 12-15).

A new block is a child of one of the child blocks of the current node (lines 17-28)
The new block is a direct child of the current node (line 29)

In the first and third case we rebuild the immediate children of the current node accordingly. However, in the second scenario we need to recursively go one level down.
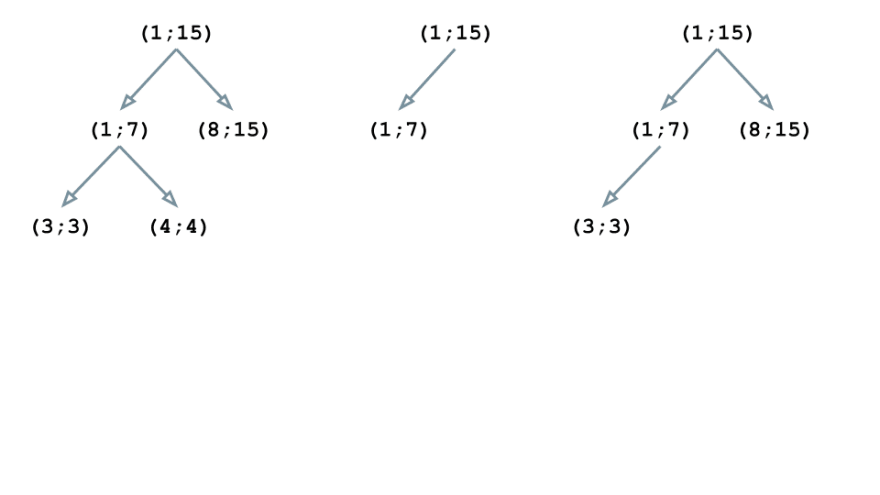
Now let’s consider an example. Suppose the body of our contract consists of 6 instructions n1-n6, which correspond to the lines of the source code as follows:
n1: (1;15)
n2: (1;15)
n3: (1;7)
n4: (8;15)
n5: (3;3)
n6: (4;4)
The first instruction is n1, and the corresponding block (1; 15) becomes the root of our tree structure:

The n2 instruction has the same block as the previous one, so the tree doesn’t change:

The block (1; 7) of the instruction n3 is nested in (1; 15), so we rebuild the structure:

The block (8; 15) is also embedded in the root element of the tree (1; 15). However, this block is neither a parent for (1; 7), nor a child, so the tree gets this form:
The block (3; 3) is nested in (1; 15) and (1; 7), thus becoming a child of (1; 7):
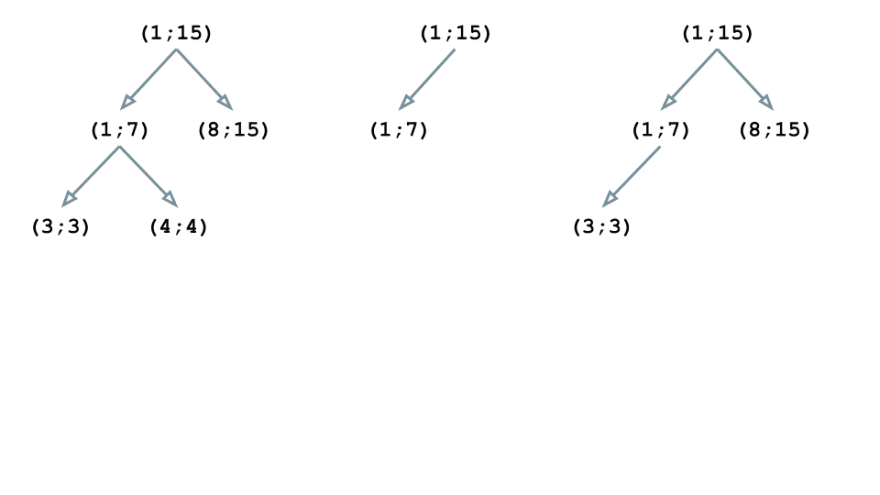
Similarly, (4; 4) is embedded in (1; 15) and (1; 7) but it doesn’t intersect with (3; 3); therefore, it becomes the second child node of (1; 7)
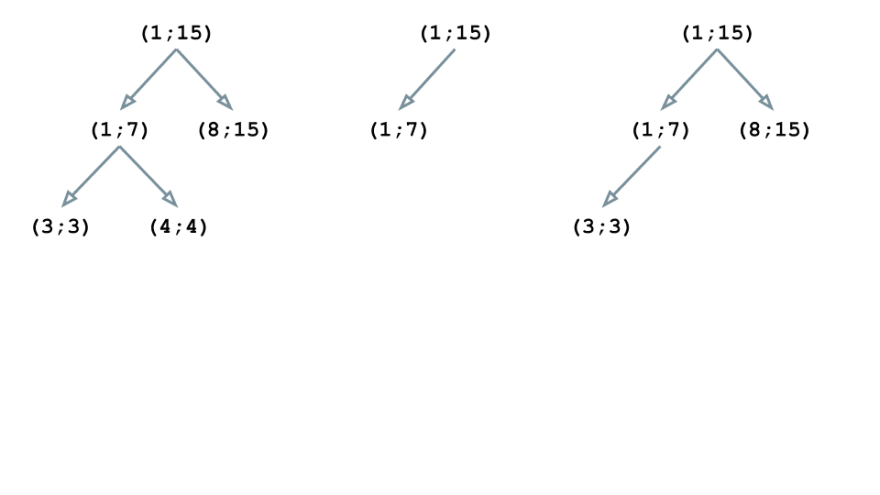
Thus, all the blocks are in place and the we have our tree structure built. Now we can enhance it with useful information such as the text of the source code for the blocks, as well as some assembler instructions.
4. Conclusion
When compiling the contracts, Truffle generates very useful data which can help you to grasp how your code actually behaves and what exactly it does in the blockchain. This is also a convenient way to analyze bottlenecks in your code. However, this data is not exactly intelligible from the first sight, and today you’ve learned how to understand the format of it and figure out a way to present it in a simple and convenient form for further analysis.
Thank you for bearing with us through this long and technical post. We hope you enjoyed it and found it useful. Stay tuned for more insights from us, we can’t wait to share with you more of our hands-on Blockchain experience and fun stories!
Code hard. Build big. Decentralize.
Yours,
EQ LAB Team
This content originally appeared on DEV Community 👩💻👨💻 and was authored by EQ LAB
EQ LAB | Sciencx (2023-01-29T16:42:22+00:00) Solidity Source Mapping. Retrieved from https://www.scien.cx/2023/01/29/solidity-source-mapping/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.