
This content originally appeared on Level Up Coding - Medium and was authored by Vincent Liu
Toward a story- and impact-driven data science

I never thought I would choose a data science program for my master’s study, just like I would never believe that criminal justice would eventually become my biggest passion before going to college.
Yet, one of life's biggest joys is discovering new possibilities because you never know what’s in store for you, just like the famous quote from Forrest Gump — “Life is like a box of chocolates”. During my three years of doing advocacy work with two criminal justice-focused nonprofits in twin cities, Minnesota, I saw how data and evidence could be intertwined and helped to push for changes in the system. In public and social sectors, data is perceived as evidence, for which local governments use it to talk about the effectiveness of their programs, organizations use it to identify areas of improvement and fact-check policies, and researchers use it to back up their arguments. Coming from a community engagement background, I know data analysis that is carried out in scientific, objective, and strategic manners is the solution to a variety of social problems from crime prevention to addressing homelessness. This discovery led me to study data science.
However, when I was finally in the space, I was somehow disappointed by the field itself. Whereas I believe the field should be applied in nature, that is not the case. Truly algorithms are valuable to the optimization of data systems, which will help organizations save tons of money and enhance work efficiency, the invisible but ubiquitous trend of emphasizing data algorithms over data is just wrong. For me, to be a great data scientist or researcher first requires a solid understanding of data, for example, how the data was collected, where the dataset may be limited or unethical, what impact the project is intended to achieve, how the data work may benefit the targeted audience, and what method is most effective to make the end meet. Then comes the understanding of the pros and cons of different algorithms.
In this post, I want to share a few areas, in which I think data science could learn from social science. I realize that I took an untraditional path to data science and my perspective may not represent the general opinion of people who work in the field. More importantly, this article is not meant to initiate a debate but to communicate my thoughts with you, the reader. As many writers would agree, once a work is finished, it’s detached from its creator (author) and serve for public meaning.
1. Learning From The Quanti vs Quali Debate in Social Science
Before the discussion formally begins, I probably should spill a few words on what is social science, what the term entails, and how social scientists conduct their research. However, I think it will be boring to write a thorough introduction to these topics, which can go really lengthy too (I could literally write a few thousand words on them if I want). Rather, I want to spotlight a debate inside the field — the debate between using quantitative vs qualitative methods.
People love to take sides. As one of the Founding Fathers James Madison said in The Federalist Paper No.10, the tendency to form factions is in the human’s DNA. This belief of people are born into groups is one of the core principles behind the American political system. It is the rationale that fostered Madison and other founders to establish another political infrastructure, the Senate, which differs from the House’s majority rule, is intended to protect minority right.
The inclination is everywhere. When modern social science was still at its early age in the last century, some scholars argued that modeling was the best way to capture the root causes of social problems. Other scholars, who were influenced by the philosophy of empiricism, conducted their research by doing observations in the field. The two types of scholars were spread in a variety of disciplines, and the way they studied social phenomena later became what we now called quantitative methods (survey analysis, statistics, causal inference…) and qualitative methods (interviews, focus groups, ethnography, open-ended surveys…). Depending on the issues they were interested in, these people’s methodological preferences are instilled into academic disciplines with economics being more quantitative, history and anthropology being more qualitative, and sociology and political science in the middle.
The divide is even more prominent in the recent decade with quantitative analysis being the synonym for validity, reliability, and objectivity and quantitative studies receiving far more support than qualitative studies. Some scholars, whereas doing most of the qualitative works, would even label themselves as quantitative or mixed-method on their CVs to get more funding. However, people are forgetting about two points: data doesn’t mean model or number, and the selection of methods should depend on the question they wish to answer. Data comes from a myriad of places. Other than surveys and statistics, we can also acquire data from people’s responses to interviewing prompts, fieldnotes taken during ethnographical works, and written texts. It can also come in disparate formats, such as audio, video, words, and images. The term data is broad in its meaning.
Besides, the two methods have their advantages and disadvantages. A lot of social facts can not be explained by a few models, and replicability is not what we always want. In a lot of cases, we want to know the story, and whereas data analysis could also showcase stories, it is telling a broader picture rather than depictions of what people are actually experiencing on a day-to-day basis. To use which should really be the question of what we wish to get. If statistical or causal relationships and calibrated calculations of benefits and costs are the goals, then do quantitative analysis. On the other hand, if the project is aimed to understand the lives of a certain population and derive some points from real-life observations, then qualitative designs are superior.
Trained in sociology, statistics, political science, law, and public policy, I don’t believe either of them is better than another. Thus, the debate makes little sense to me. Further, early social scientists including Emile Durkheim and Edwin Sutherland usually utilized both methods in their works.
The quan vs quali debate in social science is just like the data vs algorithm argument in data science. Neither is better, and neither is superior. For social science or data science, we need all of them to fit different tasks.

2. Going Into the Origin of Data
Although some would argue otherwise, I personally believe that it’s also the task of data scientists to understand where you get the data and the potential drawbacks associated with the dataset you are choosing. This shed light on a few aspects — (survey/experimental design), data collection, and preliminary data cleaning completed by others.
First, it’s important to know that data could be firsthand or secondhand. Firsthand data is data that we get by involving in or being responsible for the initial phases of the project from idea generation to project implementation and data collection. Firsthand data is often the most ideal because it is also directly tied to the project/research questions. For example, a lot of classical surveys started from social scientists’ desire of testing their hypotheses or satisfying their curiosity. The General Social Survey, the gold-standard data for social science, especially public opinion, scholars, was first conducted in the 70s to understand and track changes in American adults’ values and opinions on a number of issues important to society and democracy. Questions on the GSS are therefore designed intentionally to answer questions, such as what Americans value and what Americans think about the government’s income support policies. Firsthand data, however, is costly and often not acquirable.
Secondhand data, on the other hand, refers to data that we are not directly involved in the collection process but that we directly use in projects or research. Secondhand data is the most common type of data we will encounter when doing an analysis. Most surveys belong to this type unless we are the survey designer and implementer. To give an example, when we do an analysis using the American Community Survey (ACS) survey, ACS is secondhand data (even if ACS is very authoritative and popular).
Secondhand data, however, has some limits. Very rarely the secondhand data we use provide direct answers to the questions we wish to know or the objectives of our projects. Moreover, because we are not sure how the data is collected, there may exist issues in data reliability and validity, or there may exist a large amount of missing data. Most data are also messy because they are not collected for research purposes and their target audience is not researchers.
In the case of using secondhand data, it helps us to know where the limit of our data is. By limits, I am saying a few things: there is no direct solution to our questions so that estimates may be the best we can get and bias could be an important question in our results, the initial survey or experiment may be poorly designed or implemented, thus, the results we get are invalid and/or unreliable, and that the statistics may be unrepresentative to the targeted population. These three listed questions are omnipresent in different data even from the most authoritative sources.
For example, the Uniform Crime Reporting system (UCR) collected by the Federal Bureau of Investigation (FBI) is considered to be one of the most trustworthy and thorough crime statistics data systems. UCR contains over 10 databases on a wide range of topics. However, UCR has some problems: not all law enforcement agencies report their crime statistics, not all crimes that happened in the US are reported to law enforcement, and the FBI has its way of classifying crimes, which may not be the best. UCR collects information on a voluntary basis. Although highly encouraged, the FBI doesn’t mandate agencies to report their crime numbers. In recent years, the FBI collected crimes from only roughly 85 percent of agencies. Moreover, not all crimes are known by police officers, that is, the “dark corner of crimes”. In fact, the majority of crimes, especially those nonviolent and/or nonaggregated crimes, exist under the iceberg — they were like the marginal corners where sunshine never shines upon that are never known by others. Racial minorities, low-income, and other marginal populations are especially less likely to report crimes for reasons including untrust in the police. Last but not least, the issue also pertains to the data design of UCR. FBI has its own way of defining offenses like homicides, aggravated assaults, and rape. The internal flaw makes many studies that use the UCR data unreliable. The aforementioned issues are reasons why we also need to look at self-reported crimes as well, which is included in the National Crime Victimization Survey (NCVS) designed and collected by the Bureau of Justice Statistics.
Although these questions are usually of interest to statisticians and applied social scientists, understanding them could benefit us as data scientists as well.

Toward an Impact-Centric and Story-minded Account of Data Analysis
A while ago, I was talking with my friend about Chicago’s potentially worst transportation system — CTA (Chicago Transportation Authority). He said, they surely should optimize their algorithm to make sure all bus arrival times are accurate. I said, Yes, definitely, and that would greatly help people in a lot of communities who don’t have access to a car. Our conversation reflects two different mindsets. While he might care more about the algorithm the agency used to calculate the arrival time of its buses, I am interested in knowing what impacts a chance might bring about.
The story above to a certain degree sheds light on what I mean by an impact and story-centric mindset. This is also where I think data science can really learn from qualitative designs. As data analysts, we are doing data-related work on a regular basis. We fit a statistical or machine learning model on data and use data to convince others that something is going on and we need to take action for it. We often do a lot. However, somehow I think what many people ignored is the “how” — How will my analysis be used by others, how will my analysis help the organization achieve a mission, and how will my work help improve people’s lives? Although these questions are more often the tasks of strategic communication specialists and decision-makers, I think we should also care about them.
First, the project objective and target audience should always be in your mind when analyzing the data as they should be what decides how you conduct the analysis. Companies often have an idea of what they want to find out in mind when assigning the task, but this could be less the case for some governments and nonprofits. For the latter, sometimes they just want the data scientists to run some analysis, explore some issues, and present something to the stakeholders, after which they may know what to do next. In that scenario, it will be your task to find out the appropriate dataset, look at the variables, and think about what information you can undermine from these variables. In both cases, it would be a lot easier if you know what impacts or results you wish to generate on your target population/audience, with which you can say, for example, oh I should explore these few variables to see what is going on with respect to X, or I need to redo (recode) a certain part because I made a wrong decision when doing Y.
This is also an important matter to consider when we are interpreting our results. When doing data science projects, an important rule is avoiding jargon terms in explanations. Instead, interpretations of results should be plain, concise, straight to points, with the audience in mind, and its language should be as close to how people in the target community speak as possible. People won’t know what you mean by terms like random forests or logistic regressions. Rather, it is our job to make sense of those algorithms and tell them in a way that is relevant to the need and concerns of stakeholders and the target audience.
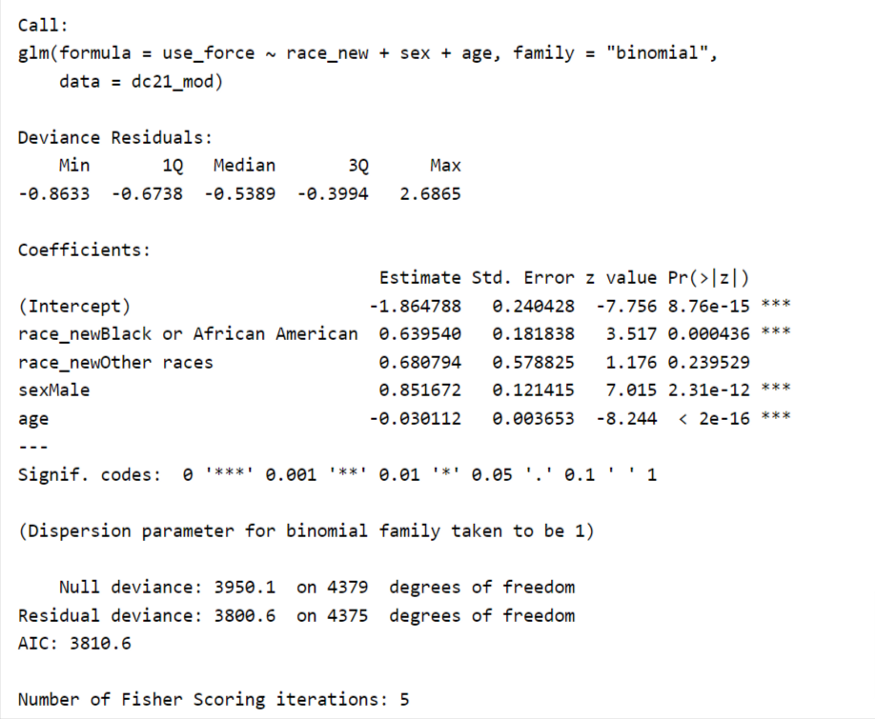
For example, in explaining the above logistic regression summary output, rather than saying African Americans is a statistically significant category with a p-value lower than .05 and a coefficient of 0.63, we could instead say among arrestees in DC in 2021, the odd of having a weapon involved in the incident that led to a police arrest was 1.9 (exp(0.63)=1.9) times higher for people who are African Americans than whites. That may also suggest that Black people are disproportionately arrested for weapon-related offenses, and from here, we may dig further into the issue by exploring if such disproportion is related to the prevalence of racial minority gangs or some other reasons.
As data scientists or computational researchers, I have been believing that we are like warriors in fighting the battleground of human society with our weapons called data. We are the people who will move the world forward with data, and two things can lead to changes: evidence-driven research and policy and storytelling of people’s real experiences with criminal justice, education, healthcare, and other systems. I don’t believe that either data or story alone will move society forward. Rather, the combinations of both will do. Being data lovers doesn’t mean we are nerds or boring people. It is the opposite because data science is not only a science but also an art. Deep inside, we are who care about the world, the people, and the future of the human race deeply.

Learning Some Domain Knowledge
Last but not least, it will help to learn some domain knowledge too! You don’t need to be the expert but at minimum, you should have a rough understanding of what you are dealing with. For instance, it could be troublesome if you are analyzing healthcare data but have no knowledge of the healthcare system. In that scenario, you may frown and feel confused when people are chatting about SNAP and TANF, and should that be the case, I may assume the conversation won’t go so well.
Another benefit of knowing domain knowledge is it will help in your decision-making when doing analysis. For example, when I was working for a nonprofit on a project about racial disparities in police traffic stops, a team member threw a question in our weekly meetings: how do aggravated assaults differ from assaults? Because he didn’t have knowledge about the legal classification of offenses, he wasn’t sure if he should combine the two categories as one in the explorative analysis or leave them as two, and it could spend a lot of time explaining the differences because criminal law has a very specific definition of the term “aggravated”, which is related to the fundamental principles underlying the criminal-legal system. As data scientists, no matter whether we are working in the social, public, or private sectors, we should develop the habit of finding and reading subject-relevant literature to increase our knowledge of the issue.

Conclusion
If any words are qualified to summarize the whole post, I think it’s the following:
I am just a ferryman,
on the vast blue river called data,
Rowing the boat
Padding the water with my pedals
whose names are methods,
Behind me is the gorgeous land named people,
Ahead of me is the sparkling star,
that glows where the mountain of data science shadows.
— — Vincent, Ferryman
In the poem above, we, researchers or data scientists, are symbolized by ferrymen who row their small boats on the vast river that is made of water whose name is data. Our boat, which is the medium for the research/data analysis pipeline, starts from the mundane human world, treads the river with our weapon (pedals)— analysis/algorithms — and moves to the unforeseeable yet beautiful future of data science, which glows because of the impacts it created on people.
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job
What Data Science Can Learn From Social Science was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Vincent Liu
Vincent Liu | Sciencx (2023-02-08T15:16:21+00:00) What Data Science Can Learn From Social Science. Retrieved from https://www.scien.cx/2023/02/08/what-data-science-can-learn-from-social-science/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.