
This content originally appeared on Bits and Pieces - Medium and was authored by Matteo Pampana
Adopt The Right Backend Strategy For Your Microservice To Handle Huge Loads of Reads and Writes

I was at my desk on a lazy Monday morning. Suddenly, an alert appeared on my screen. Our endpoint to show a user's profile info was taking a lot of time to process the requests. I was responsible for that part of the system. I had to do something … quickly.
Customers are the most important part of a company. If the APIs are not efficient, they will experience waiting. Waiting means ugly spinners, rage, and quitting your application. You may lose some of your active users. You decrease the returns of your company.
The User-Experience (UX), even for a nerdy backend engineer, should be the polar star of your daily activities.
I did not want an angry customer screaming on my shoulders. So, I drank my coffee and started thinking about solving this issue.

I was working with a microservices architecture that ran on a Kubernetes cluster. For sure, we could have scaled horizontally increasing the number of pods. Could this have solved the problem? Could this have been sufficient? Maybe. Maybe not.
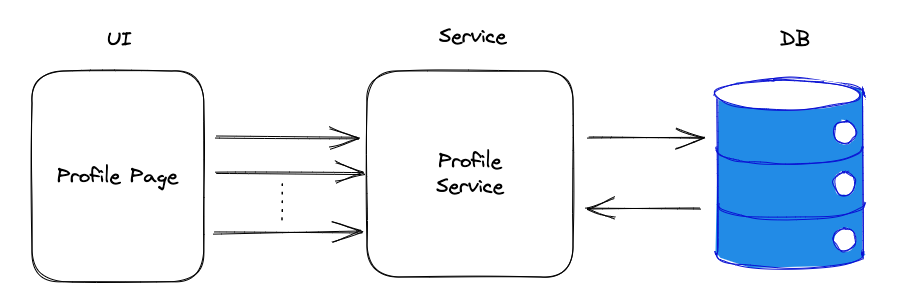
In fact, you can add more pods, but doing so increases the number of connections you have to establish with your database. Your database instance, in turn, does have its own limits and may not be able to handle all the requests. When something is not unlimited, a scheduling policy can occur. Some processes may experience waiting times, thus increasing the response times of your APIs.
I needed an alternative. I started looking at our beautiful dashboards for the user’s profile info APIs.
The graphs were talking out loud: we were experiencing a huge load in the endpoint that was creating new profiles in our database. Instead, the endpoint that was retrieving the profile info had nothing unusual: the traffic was the same as the day before. Its response time was not.
I scratched my head. The creation endpoint was having a peak in traffic and this was causing a decreasing performance in our reads.
Yes! I knew how to tackle this issue.
CQRS - Command Query Responsibility Segregation
There is a pattern known as CQRS: Command Query Responsibility Segregation. This pattern is not rocket science. In this jargon, a command module is responsible for creating and updating a piece of data. A query module is responsible for reading that piece of data.
Long story short:
The CQRS pattern tells that you must separate the module that writes something from the module that reads something.
In this case, we were mixing up (on the backend side) writes and reads from the service’s database.
A peak in the traffic that requested writes on the database, which is typically slower than the reads, has caused the detrition of the read endpoint’s response time simply because it had to wait an unexpected amount of writes to complete.
I decided to apply the CQRS pattern to my backend architecture.
Firstly, I created a database replica. This is a very easy operation to perform if you are running on a cloud provider, like AWS. They manage to create and maintain a replica of your DB instance in a few clicks.
So, I transformed my backend architecture into something like the one below:
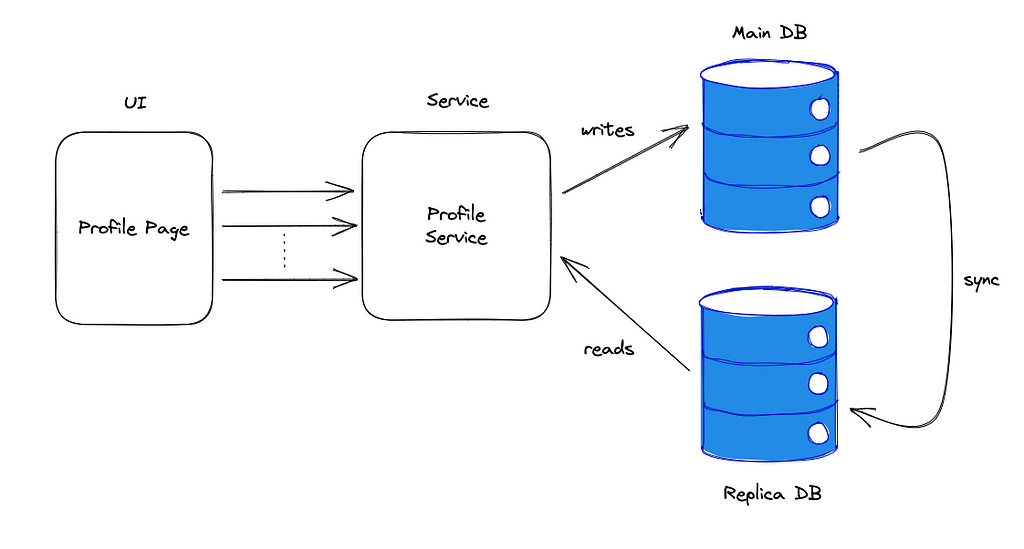
As you can see, at this point my service was still represented as a little “monolith” but the writes operations were not interfering anymore with the reads.
The tricky part here is the sync arrow on the right. It is not trivial to sync multiple storage systems. There are many techniques that can be used to achieve it. I will tell you about my experiences with these different techniques in a different article. For now, let’s move on with our story.
Secondly, I split the profile service into two services. You can guess the names of these two modules were:
- Profile Command Service
- Profile Query Service
The Profile Command Service was responsible for creating and updating the user’s profile info. The Profile Query Service for retrieving it.
So, the backend architecture has become something like the one below:
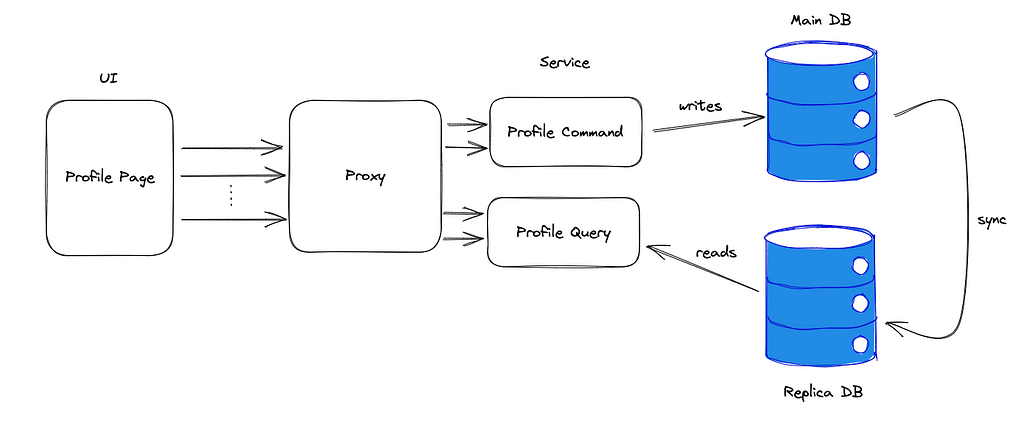
In this picture, I decided to show also the Reverse Proxy to route the UI requests to the correct service, but this was present even in the previous ones since we were talking about microservices architecture.
This separation allowed me to scale the two services differently.
Tip: You can use an open-source toolchain like Bit for splitting the Profile Command and Query services into reusable, independent components that can be shared across multiple microservices. This would help to further reduce the complexity of the architecture and enable you to focus on building and scaling specific functionalities of the microservices. This guide will show you how.
Increasing traffic on the creation/updates of the profile info will be handled automatically scaling up the number of instances of the Profile Command Service without impacting the reads, which will be executed in a different process with a different database.
The response time went back to normal. Now, our users are happier than ever and we have never faced a response time issue with this particular service. 💚

Conclusions
I learned how to deal with peaks in traffic that in turn involve operations on a storage system. I wanted to share with you how simple the CQRS (Command Query Responsibility Segregation) pattern is as a concept, and how powerful it is when applied to the design of backend architectures.
In fact, the interesting stuff is not really the CQRS pattern itself but the architectural decision that can be made thinking about it. I was (and I currently am) amazed by the impact that this simple concept had on my backend performances.
From monolithic to composable software with Bit
Bit’s open-source tool help 250,000+ devs to build apps with components.
Turn any UI, feature, or page into a reusable component — and share it across your applications. It’s easier to collaborate and build faster.
Split apps into components to make app development easier, and enjoy the best experience for the workflows you want:
→ Micro-Frontends
→ Design System
→ Code-Sharing and reuse
→ Monorepo
Learn more
- How We Build Micro Frontends
- How we Build a Component Design System
- How to reuse React components across your projects
- 5 Ways to Build a React Monorepo
- How to Create a Composable React App with Bit
How I Redesigned The Backend To Quickly Handle Millions Of Reads (And Writes) was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Matteo Pampana
Matteo Pampana | Sciencx (2023-02-22T06:45:01+00:00) How I Redesigned The Backend To Quickly Handle Millions Of Reads (And Writes). Retrieved from https://www.scien.cx/2023/02/22/how-i-redesigned-the-backend-to-quickly-handle-millions-of-reads-and-writes/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.