
This content originally appeared on DEV Community and was authored by Joshua O.
When deploying changes to an application, there are several strategies that can be taken. In this article, the different strategies will be explained, with an analogy, and an analysis of the benefits and tradeoffs.
Deployment Strategies
Imagine you are the manager of a popular pizza restaurant that is open 24/7 for deliveries. This restaurant has two chefs working in the kitchen and both are needed to ensure orders are fulfilled on time. You have a new special recipe that will change how all pizzas are made. This new recipe involves using a different dough to make the pizza bread, using a different type of cheese, new toppings on the pizza and changes to the pizza oven settings. These are significant changes that you hope will lead to more delicious pizzas being made, which equals happier customers, which hopefully translates to more money.
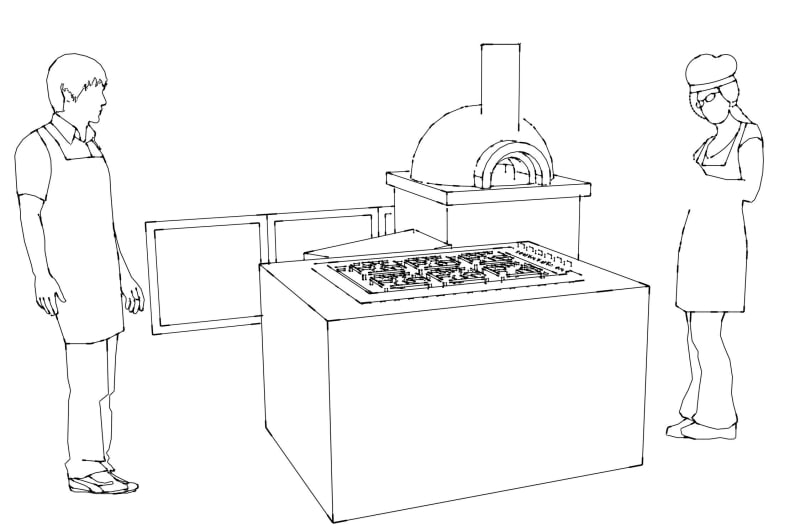
This new recipe is quite complex and will take an hour for a single chef to learn. How do you teach the chefs this new recipe? Remember that this restaurant must be open 24/7. Your approach will be based on whether you are trying to:
reduce the time it takes for both chefs to learn the new recipe
ensure you have enough chefs to fulfil orders while once chef is learning the new recipe
keep costs low during the recipe change
be able to quickly revert back to the old recipe
test the new recipe with a small subset of your customers
A similar set of trade-offs are made when deciding on an application deployment strategy. Do you want to:
minimise deployment time
have zero downtime
ensure capacity is maintained
reduce deployment cost
be able to rollback i.e. easily revert changes
test the change with a small subset of your users
The trade-off comes because you can’t have it all. As an example, having zero downtime, ensuring capacity is maintained and having the ability to rollback comes at the price of a longer deployment time and higher cost. The logic behind this example will be explained in the blue/green deployment strategy example. Ultimately, there are no solutions, only trade-offs.
A three-tiered web application will be used as the example architecture for the different deployment types. This consists of a presentation, logic and database tier as shown below.
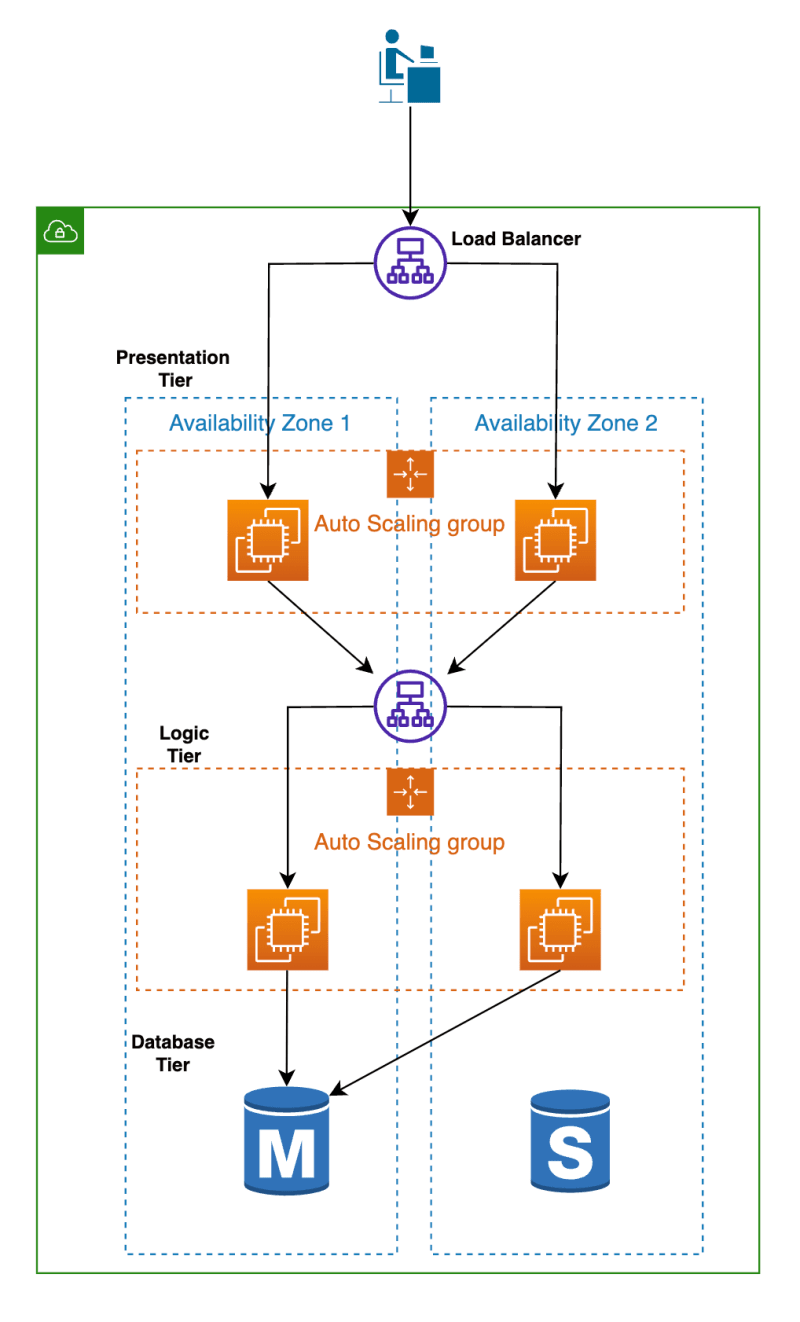
The presentation tier is responsible for presenting the user interface to the user. It includes the user interface components such as HTML, CSS, and JavaScript.
The logic tier s responsible for processing user requests and generating responses, by communicating with the database layer to retrieve or store data.
The database tier is responsible for storing and managing the application's data and allows access to its data through the logic tier.
All At Once Deployment
In this type of deployment, changes to an application are made to all instances at once. In the three-tiered web application architecture, an all at once deployment that makes changes to the UI will take both instances in the presentation tier out of service during the deployment as shown below.

This type of deployment has some pros:
deployments are fast
deployments are cheap
And some cons:
downtime during deployment
a failed deployment will have further downtime since you will need to rollback by deploying the previous version of the application to the instances
rollbacks are manual
An all at once deployment is ideal in a situation when a deployment needs to be made quickly. It is also ideal for situations when there is a low impact of something going wrong. So for example, deployments in non-live environments like development and test environments, that don’t have any real users.
Any use case where the cons listed above are not acceptable would be an anti-pattern for an all at once deployment.
An all at once deployment is analogous to the two chefs being told to stop taking new orders, and stopping any orders they were currently working on to learn the new pizza recipe and then using that that recipe going forward. While they are learning the new recipe, orders will go unfulfilled. If they can’t quite get to grips with the new recipe, any pizzas they make will also not be as good, will take longer to make, or both.

Also, if you later found out that customers do not like how the new pizzas taste, you have to revert back to the old recipe. This means restocking your kitchen with the previous dough and cheese you used and getting rid of the new toppings. This is not an ideal way of making a recipe change as you can lose customers if they don’t like the taste of the pizza.
On the plus side, this approach is cheap, in terms of up front cost at least. If it goes wrong, it can be very expensive as a result of lost future sales and upset customers. It is also fast to implement. If it takes each chef an hour to pick up the new recipe and you show them both at the same time, the new recipe can be ready to go live in an hour.
Rolling Deployment
In a rolling deployment, changes are made to an instance or a batch of instances at the same time. In the three-tiered web application example, UI changes will first be deployed to one instance and once that is complete, it will be repeated on the other instance.

With this approach, you avoid downtime as changes are only made to one instance at a time. The drawback is that deployments will naturally take longer since you have to wait for the first deployment to finish before deploying to the second instance.
Bringing back the chef analogy, the new recipe will only be shown to one chef at a time. This means a reduced capacity to deal with orders, but orders will still be fulfilled since there will always be at least one chef available.
Rolling with Additional Batch Deployment
This is similar to a rolling deployment, but an additional instance is added into the cluster during the deployment to maintain capacity as shown below.

First you launch a new instance and then deploy the new application there. After the deployment is successful, you terminate an instance running the older application. These three steps of launching a new instance, deploying the new application there and terminating the old instance is repeated until you have deployed the new application on all the instances.
The key point to note with this approach is that by adding a new instance with the new application version before terminating any instances, you are always maintaining capacity. If you need two instances running at the same time, this deployment strategy will ensure you always have two instances available. This is useful for applications that require high availability.
With this approach, some users will be routed to different instances during the deployment. This means customers will see different UI on the web page - some will see the old, others will see new UI while the instances are still being updated. If a consistent user experience is absolutely necessary for all your users at all times, this deployment may not be right for you.
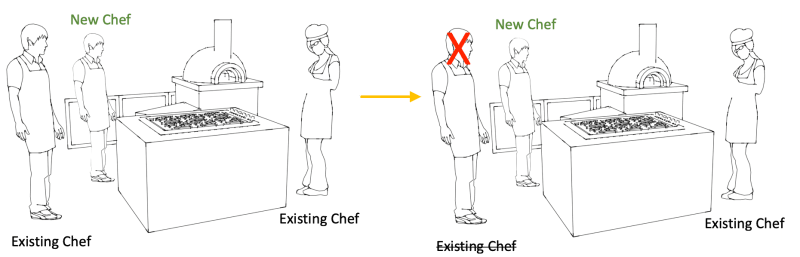
The rolling with additional batch deployment is analogous to hiring an extra chef to show the new recipe to while the two existing chefs still fulfil pizza orders. Once this new chef is familiar with the new recipe, orders are routed to him and one of the existing chefs. The third chef is then told to go home. This is repeated until both chefs in the kitchen are new and familiar with the new recipe. But while this transition is happening, there are always a minimum of two chefs who can fulfil pizza orders in the kitchen.
Canary Deployment
The phrase ‘canary in the coal mine’ originates from an old practice in coal mining where miners would take a canary into the coal mine as an early warning alarm.

Canaries are highly sensitive to toxic gases like methane and carbon monoxide, which humans can’t easily detect as they are odourless and colourless. The canary dying was a signal to evacuate the mine since dangerous levels of toxic gases had built up to levels high enough to kill the bird. This was an effective, albeit brutal way of signalling potential danger to the miners.
In canary deployment, a separate set of instances will have the new application deployed on them, and a small percentage of all visitors will be routed to the new version. This can be done with the weighted routing option using Route 53 (managed DNS service from AWS). With weighted routing, you can specify a weight for each target load balancer.

In this example, Route 53 will initially point 90% of all users to the old application and 10% to the new application. The new application will then be closely monitored to see metrics like error rates, response times etc. If any issues arise with the new application at this stage, then the weights are simply updated so that all traffic points back to the old application. Just like the canary in the coal mine, the initial monitoring on a small set of users serves as a cheap signal to give you confidence to either continue the transition to the new application, or revert back to the old. For critical applications that cannot afford any downtime or other issues, this is an effective way of managing the risk of a new deployment while being able to immediately revert back to the old application.
If everything looks fine with the new application during the initial testing with a small number of users, then the percentage of users routed there will be slowly increased as you gain confidence in its performance, until all users are now routed to the new application and the old instances can be terminated.
Blue/green Deployment
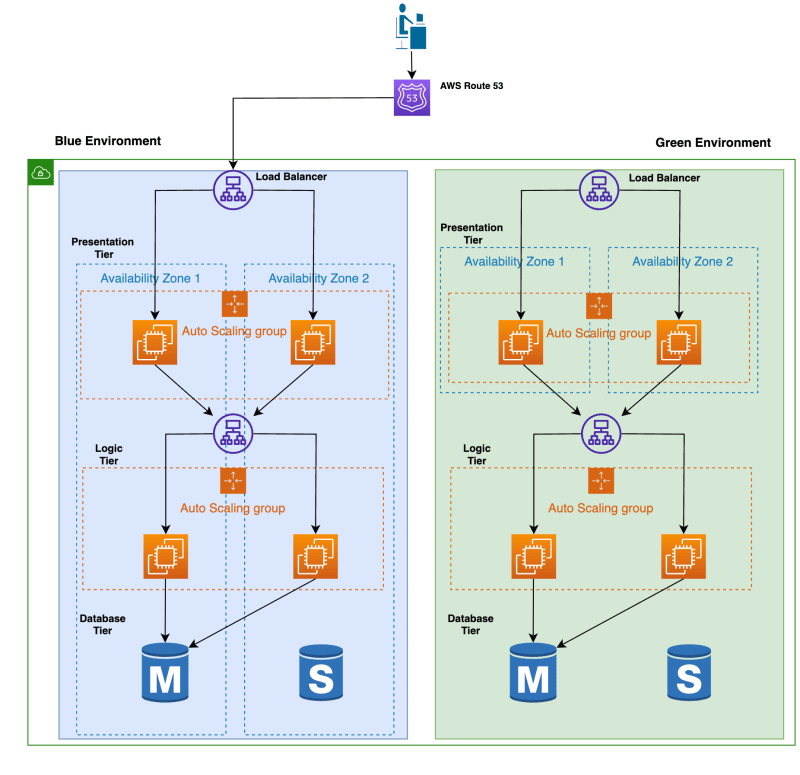
Blue/green deployment involves creating two identical environments: a "blue" environment which hosts the current version of the application and a "green" environment which hosts the new version of the application. This is shown below.

Once the new version of the application is deployed to the green environment, the Route 53 DNS record is updated to only point to the load balancer of the green environment in front of the presentation tier as shown below. The instances of the presentation tier in the blue environment can also be stopped to save cost and only restarted again when there is a new version of the application to deploy.

In this example of blue/green, only the instances in the presentation tier are in a separate environment. However, you could have an identical copy of the blue and green environments across all tiers so that if you were making changes to the logic or database tiers of the application, there would also be no downtime during deployment, with the ability to easily rollback. This is shown below.
The main benefit of blue/green deployment is zero downtime during deployments, since all you have to do is update the DNS record to point to the load balancer of the ‘green’ environment.
Blue/green is similar to canary deployment, but instead of initially sending a small percentage of users to the new version of the application, all users are sent to the new version once it is deployed and thoroughly tested. There is no live testing with real users in a blue/green deployment.
Blue/green deployment is analogous to having two restaurant branches, each with two sets of chefs there. The ‘blue’ restaurant uses the current pizza recipe and all takeaway orders are at first routed to this restaurant as shown below.
The ‘green’ restaurant has perfected the new recipe and is ready to receive orders. Customer orders are then routed to this restaurant as shown below.

If customers complain about the delivery time or quality of the pizza (which shouldn’t happen if the new recipe has been tested with real customers beforehand), the manager can simply route the orders back to the blue restaurant making the old recipe, figure out what went wrong with the new recipe, make some tweaks and try again.
Bringing it Together
The right deployment strategy for your application depends on what you are trying to optimise for.
All at once deployments are ideal is you want to minimise deploy time and upfront cost. The price you pay, however, is application downtime, further downtime if the deployment fails and a manual rollback process.
Rolling deployments will take longer to deploy than an all at once deployment. However, there will be no downtime since deployments are made incrementally on an instance or a set of instances. There will, however, be reduced capacity during deployment, so this may not be ideal for an application that requires high availability.
Rolling with additional batch deployment addresses the issue of reduced capacity with a rolling update. An additional instance or batch of instances with the new version is added to the cluster in order to maintain the same capacity. Only then are instances running the older version of the application terminated.
Canary deployment has no downtime and no reduced capacity during deployment. It is also safer as it allows for testing with a fraction of the users and closely monitoring performance before gradually routing all users to the new version. This does not, however, come for free. Additional infrastructure is required. Also, detailed monitoring and observability of the application has to be in place. This means it is more expensive and more complex to deploy using this strategy. It is important to caveat ‘more expensive’. This approach will incur higher upfront costs, but for a critical application with lots of users that cannot afford any downtime, it could be more expensive (through lost future revenue, unhappy customers or a ruined reputation) to use another deployment strategy that is ‘cheaper’ but ultimately less robust to failures.
Finally, blue/green is ideal for zero downtime deployments that are easy to rollback. It however requires additional cost for a separate set of identical infrastructure to be provisioned.
This content originally appeared on DEV Community and was authored by Joshua O.
Joshua O. | Sciencx (2023-05-20T12:59:31+00:00) Deployment Strategies for Applications. Retrieved from https://www.scien.cx/2023/05/20/deployment-strategies-for-applications/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.